Tabela Ansi dla rosyjskich znaków. Kodowanie: przydatne informacje i krótka retrospektywa
Czasami nawet dość doświadczony specjalista nie powie Ci od razu, jaka konkretna wartość nacisku lub długości w jednym systemie odpowiada wartościom w innym systemie wartości.
Do ułatwiać W tym zadaniu oferujemy tabele stosunku wartości ciśnienia i długości w systemach europejskich i amerykańskich z małymi wyjaśnienia... Ale najpierw kilka słów o samych standardach.
HAŁAS jest niemieckim standardem (oznacza Deutsches Institut für Normung, czyli opracowany przez Niemiecki Instytut Normalizacyjny), który jest opracowywany ściśle w ramach przepisów Międzynarodowej Organizacji Normalizacyjnej - ISO (Międzynarodowa Organizacja Normalizacyjna).
ANSI- standard przyjęty w Stanach Zjednoczonych Ameryki. Oznacza Amerykański Narodowy Instytut Norm, czyli standard Amerykańskiego Narodowego Instytutu Standardów.
W związku z tym standardy ANSI są określane przez tę instytucję i daleko nie zawsze między standardami HAŁAS oraz ANSI Dokładny konformizm w różnych dziedzinach.
Konwersja jednostek ciśnienia z ANSI na DIN
Tutaj wszystko jest proste: jeśli standard ANSI liczba 150 stoi naprzeciwko ciśnienia - oznacza to, że ciśnienie nominalne (dla którego przeznaczony jest zawór) wynosi 20 barów, 300 - 50 barów itd. Maksymalna wartość o Klasa ANSI- 2500 będzie równe 420 bar zgodnie z normą europejską HAŁAS.
Korzystając z tej tabeli, nietrudne przetłumacz wartości ciśnienia iz powrotem: z HAŁAS v ANSI, chociaż nasi inżynierowie bardzo potrzebują takiego tłumaczenia rzadziej.
Konwersja jednostek długości z systemu amerykańskiego na europejski (rosyjski)
Jak wiadomo, Amerykanie wszystko jest mierzone w calach i stopach, a my i Europejczycy- milimetry, centymetry i metry, czyli jak zdecydowana większość państw na świecie, w których żyjemy metryczny system jednostek.
Jak przeliczyć cale na milimetry? Właściwie to też nie jest trudne, pamiętaj tylko, że 1 cal to 25,4 mm. Jednak dość często liczba po przecinku zaniedbany a nawet liczenie wskazuje, że 1 cal = 25mm.
Jeśli więc np. przekrój wlotu według amerykańskiego systemu miar wynosi 2 cale, to przekładając tę wartość na nasz system miar zgodnie z powyższą regułą, otrzymujemy 50 mm, a dokładniej , 51 mm (zaokrąglenie 50,8 wg regulaminu) ...
Pozostaje dodać, że średnica wynosi techniczny cechy są oznaczone literami łacińskimi DN i często jest wskazywany dokładnie w cale, a ciśnienie jest oznaczone literami PN i jest najczęściej wskazywany w słupy- w każdym razie używamy właśnie takiego oznaczenia jak najbardziej wygodny.
I poniższa tabela pomoże możesz obliczyć nie tylko dokładny liczba milimetrów w jednym calu (z dokładnością do tysięcznej milimetra), ale pomoże też dowiedzieć się, ile milimetrów zawiera np. 2,5 cala.
Aby to zrobić, znajdź kolumnę 2 "" (2 cale), a po lewej stronie poszukaj 1/2. Łącznie 2,5 cala = 63,501 mm, co jest całkiem możliwe do zaokrąglenia do 64 mm, a na przykład 6,25 cala (tj. 6 i 1/4) = 158,753 mm lub 159 mm.
|
| Cale „” w milimetrach |
|||||||
|
| ||||||||
|
| ||||||||
Jeśli potrzebujesz tylko wpisać kilka znaki specjalne lub znaków, możesz użyć tabeli znaków lub skrótów klawiaturowych. Listę znaków ASCII można znaleźć w poniższych tabelach lub Wstawianie liter narodowych za pomocą skrótów klawiaturowych.
Uwagi:
Wstawianie znaków ASCII
Aby wstawić znak ASCII, naciśnij i przytrzymaj klawisz ALT, a następnie wpisz kod znaku. Na przykład, aby wstawić znak stopnia (º), przytrzymaj klawisz ALT i wpisz klawiatura numeryczna kod 0176.
Notatka:
Wstawianie znaków Unicode
Ważny: Trochę Programy Microsoft Pakiet Office, taki jak PowerPoint i InfoPath, nie może konwertować kodów znaków Unicode. Jeśli potrzebujesz znaku Unicode i używasz jednego z programów, które nie obsługują znaków Unicode, użyj do wprowadzenia znaków, które mogą być potrzebne.
Uwagi:
Zamknij wszystkie programy.
Kliknij dwukrotnie ikonę Instalacja i usuwanie programów na panel kontrolny.
Wykonaj jedną z następujących czynności:
jeśli aplikacja Microsoft Office zainstalowany jako część Microsoft Office, wybierz Microsoft Office w terenie Zainstalowane programy a następnie kliknij Zastępować;
Gdyby Aplikacja biurowa został zainstalowany osobno, kliknij jego nazwę na liście Zainstalowane programy a następnie kliknij Reszta.
Liczby należy wpisywać na klawiaturze numerycznej, a nie alfanumerycznej. Jeśli musisz nacisnąć, aby wprowadzić cyfry na klawiaturze numerycznej Klawisz NUM ZABLOKUJ, upewnij się, że zostało to zrobione.
Jeśli masz problemy z konwersją kodu Unicode na znak, wpisz kod na klawiaturze numerycznej, zaznacz go, a następnie naciśnij klawisze Alt + X.
V Microsoft Windows XP i nowsze wersje czcionki Unicode Universal Font są instalowane automatycznie. W systemie Microsoft Windows 2000 czcionkę Unicode należy zainstalować ręcznie.
W systemie Microsoft Windows 2000
W oknie dialogowym Instalowanie pakietu Microsoft Office 2003 Wybierz opcję Dodaj lub usuń komponenty a następnie kliknij Dalej.
Proszę wybrać Dodatkowe dostosowanie Aplikacje i naciśnij przycisk Dalej.
Rozwiń listę Wspólne narzędzia biurowe.
Rozwiń listę Wsparcie wielojęzyczne.
Kliknij ikonę Czcionka uniwersalna i wybierz żądaną opcję instalacji.
Korzystanie z tabeli symboli
Tabela symboli jest wbudowana w Microsoft Program Windows, który umożliwia przeglądanie znaków dostępnych w wybranej czcionce. Używając tablicy symboli, możesz skopiować pojedyncze symbole lub grupy symboli do schowka, a następnie wkleić je do programu, który je obsługuje.
Naciśnij przycisk Początek, a następnie wybierz Programy, Standard, Praca oraz tabela symboli.
Aby wybrać symbol w tabeli symboli, kliknij go, kliknij Wybierz, Kliknij kliknij prawym przyciskiem myszy myszą w miejscu dokumentu, w którym chcesz dodać symbol i wybierz polecenie Wstawić.
Wspólne kody znaków
Aby uzyskać więcej znaków, zobacz artykuł zainstalowany na komputerze, kody znaków ASCII lub diagram skryptów kodu znaków Unicode.
|
Znak |
Znak |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Symbole walut |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Symbole prawne |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Frakcje |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Symbole interpunkcyjne i dialektowe |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Symbole formularzy |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Wspólne kody diakrytyczneAby uzyskać pełną listę glifów i powiązanych kodów znaków, zobacz.
|
Framework Bootstrap: szybki responsywny układ
Samouczek wideo krok po kroku przedstawiający podstawy responsywnego układu we frameworku Bootstrap.
Naucz się składać łatwo, szybko i wydajnie, korzystając z potężnego i praktycznego narzędzia.
Układ na zamówienie i zarabianie.
Bezpłatny kurs "Witryna WordPress"
Chcesz opanować CMS WordPress?
Pobierz samouczki dotyczące projektowania i układu witryny WordPress.
Naucz się pracować z motywami i pokrój układ.
Darmowy kurs wideo na temat projektowania strony rysunkowej, układu i instalacji na CMS WordPress!
* Najedź myszą, aby wstrzymać przewijanie.
Wstecz do przodu
Kodowanie: przydatne informacje i krótka retrospektywa
Postanowiłem napisać ten artykuł jako mały przegląd problematyki kodowania.
Dowiemy się, jakie jest kodowanie w ogóle i dotkniemy historii tego, jak w zasadzie się pojawiły.
Porozmawiamy o niektórych ich funkcjach, a także rozważymy momenty, które pozwalają nam bardziej świadomie pracować z kodowaniami i unikać pojawiania się na stronie tzw. krakozyabrowa, tj. nieczytelne znaki.
Więc chodźmy ...
Co to jest kodowanie?
Mówiąc prościej, kodowanie to tabela odwzorowań znaków, które możemy zobaczyć na ekranie, na określone kody numeryczne.
Te. każdy znak, który wpisujemy z klawiatury lub widzimy na ekranie monitora, jest zakodowany pewną sekwencją bitów (zer i jedynek). 8 bitów, jak zapewne wiesz, to 1 bajt informacji, ale o tym później.
Wygląd samych symboli zależy od plików czcionek które są zainstalowane na Twoim komputerze. Dlatego proces wyświetlania tekstu na ekranie można opisać jako ciągłe mapowanie ciągów zer i jedynek na określone znaki, które składają się na czcionkę.
Można uznać za protoplastę wszystkich nowoczesnych kodowań ASCII.
Ten skrót oznacza Amerykański standardowy kod wymiany informacji(American Standard Coding Table dla znaków drukowalnych i niektórych kodów specjalnych).
to kodowanie jednobajtowe, który początkowo zawierał tylko 128 znaków: litery alfabetu łacińskiego, cyfry arabskie itp.

Później został rozszerzony (początkowo nie używał wszystkich 8 bitów), więc stało się możliwe użycie nie 128, ale 256 (2 do ósmej potęgi) różne postacie które można zakodować w jednym bajcie informacji.
To ulepszenie umożliwiło dodanie do ASCII symbole języków narodowych, oprócz już istniejącego alfabetu łacińskiego.
Istnieje wiele opcji rozszerzonego kodowania ASCII ze względu na fakt, że na świecie istnieje również wiele języków. Myślę, że wielu z Was słyszało o takim kodowaniu jak KOI8-R to także rozszerzone kodowanie ASCII przeznaczony do pracy z postaciami języka rosyjskiego.
Kolejny krok w rozwoju kodowań można uznać za pojawienie się tzw kodowania ANSI.
W rzeczywistości były takie same rozszerzone wersje ASCII usunięto z nich jednak różne elementy pseudograficzne i dodano symbole typograficzne, dla których wcześniej nie było wystarczającej ilości „wolnego miejsca”.
Przykładem takiego kodowania ANSI jest dobrze znany Okna-1251... Oprócz znaków typograficznych kodowanie to zawierało również litery alfabetów języków zbliżonych do rosyjskiego (ukraiński, białoruski, serbski, macedoński i bułgarski).
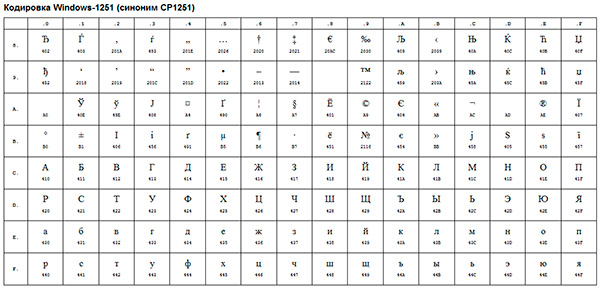
Kodowanie ANSI to nazwa zbiorowa... W rzeczywistości rzeczywiste kodowanie podczas korzystania z ANSI będzie określone przez to, co jest określone w rejestrze twojego system operacyjny Okna. W przypadku języka rosyjskiego będzie to Windows-1251, natomiast dla innych języków będzie to inny rodzaj ANSI.
Jak rozumiesz garść kodowań i brak jednego standardu nie wyszło na dobre, co było powodem częstych spotkań z tzw. krakozyabrami- nieczytelny, bezsensowny zestaw znaków.
Powód ich pojawienia się jest prosty – tak jest próba wyświetlenia znaków zakodowanych w jednej tabeli kodowania przy użyciu innej tabeli kodowania.
W kontekście tworzenia stron internetowych możemy spotkać się z krakozyabami, gdy np. Tekst rosyjski jest omyłkowo zapisany w złym kodowaniu używanym na serwerze.
Oczywiście nie jest to jedyny przypadek, w którym możemy uzyskać nieczytelny tekst - opcji jest tu sporo, zwłaszcza biorąc pod uwagę, że istnieje również baza danych, w której informacje również są przechowywane w określonym kodowaniu, jest mapowanie połączenie z bazą danych itp.
Pojawienie się wszystkich tych problemów stało się bodźcem do stworzenia czegoś nowego. Musiało to być kodowanie, które mogłoby zakodować dowolny język na świecie (wszak przy pomocy jednobajtowych kodowań, w ogóle nie można opisać wszystkich znaków, powiedzmy, języka chińskiego, gdzie jest wyraźnie więcej niż 256 z nich), wszelkie dodatkowe znaki specjalne i typografię.
Krótko mówiąc, trzeba było stworzyć uniwersalne kodowanie, które raz na zawsze rozwiązałoby problem krakozyabrowa.
Unicode — uniwersalne kodowanie tekstu (UTF-32, UTF-16 i UTF-8)
Sam standard został zaproponowany w 1991 roku przez organizację non-profit Konsorcjum Unicode(Unicode Consortium, Unicode Inc.), a pierwszym efektem jego pracy było stworzenie kodowania UTF-32.
Nawiasem mówiąc, sam skrót UTF oznacza Format transformacji Unicode(Format konwersji Unicode).
W tym kodowaniu, aby zakodować jeden znak, należało użyć jak najwięcej 32-bitowy, tj. 4 bajty informacji. Jeśli porównamy tę liczbę z kodowaniami jednobajtowymi, dojdziemy do prostego wniosku: aby zakodować 1 znak w tym uniwersalnym kodowaniu, potrzebujesz 4 razy więcej bitów, co sprawia, że plik jest 4 razy cięższy.
Oczywiste jest również, że liczba znaków, które potencjalnie można opisać za pomocą tego kodowania, przekracza wszelkie rozsądne granice i jest technicznie ograniczona do liczby równej 2 do 32 potęgi. Oczywiste jest, że była to wyraźna przesada i marnotrawstwo pod względem wagi plików, więc to kodowanie nie stało się powszechne.
Została zastąpiona przez nowy rozwój- UTF-16.
Jak sama nazwa wskazuje, w tym kodowaniu zakodowany jest jeden znak już nie 32 bity, ale tylko 16(tj. 2 bajty). Oczywiście sprawia to, że każdy znak jest dwa razy „lżejszy” niż w UTF-32, ale także dwa razy „cięższy” niż dowolny znak zakodowany przy użyciu kodowania jednobajtowego.
Liczba znaków dostępnych do zakodowania w UTF-16 wynosi co najmniej 2 do 16 potęgi, tj. 65536 znaków. Wszystko wydaje się być w porządku, poza tym ostateczna wartość przestrzeni kodu w UTF-16 została rozszerzona do ponad 1 miliona znaków.
Jednak to kodowanie nie w pełni zaspokajało potrzeby programistów. Na przykład, jeśli piszesz wyłącznie za pomocą znaków łacińskich, to po przełączeniu z rozszerzonej wersji kodowania ASCII na UTF-16 waga każdego pliku podwoiła się.
W rezultacie, podjęto kolejną próbę stworzenia czegoś uniwersalnego i tym czymś jest dobrze znane kodowanie UTF-8.
UTF-8- to jest kodowanie wielobajtowe ze zmienną długością znaków... Patrząc na nazwę, możesz pomyśleć, przez analogię do UTF-32 i UTF-16, że 8 bitów jest używanych do kodowania jednego znaku, ale tak nie jest. A dokładniej, nie do końca.
Dzieje się tak, ponieważ UTF-8 zapewnia najlepszą kompatybilność ze starszymi systemami, które używały znaków 8-bitowych. Do zakodowania jednego znaku w UTF-8 jest faktycznie używany od 1 do 4 bajtów(hipotetycznie możliwe jest do 6 bajtów).
W UTF-8 wszystkie znaki łacińskie są zakodowane w 8 bitach, tak jak w kodowaniu ASCII... Innymi słowy, podstawowa część kodowania ASCII (128 znaków) została przeniesiona na UTF-8, co pozwala na „wydanie” tylko 1 bajta na ich reprezentację, przy zachowaniu uniwersalności kodowania, dla którego wszystko zostało uruchomione.
Tak więc, jeśli pierwsze 128 znaków jest zakodowanych z 1 bajtem, wszystkie inne znaki są zakodowane z 2 lub więcej bajtami. W szczególności każdy znak cyrylicy jest zakodowany dokładnie 2 bajtami.
W ten sposób otrzymaliśmy uniwersalne kodowanie, które pozwala nam pokryć wszystkie możliwe znaki, które muszą zostać wyświetlone, bez niepotrzebnego „ważenia” plików.
Z BOM-em czy bez?
Jeśli pracowałeś z edytory tekstu(edytorzy kodu) jak Notatnik ++, phpDesigner, szybki php itp., zapewne zwróciłeś uwagę na to, że określając kodowanie, w jakim zostanie utworzona strona, możesz wybrać co do zasady 3 opcje:
ANSI
- UTF-8
- UTF-8 bez BOM
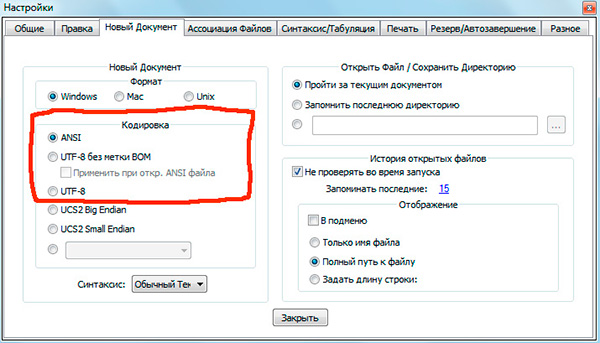
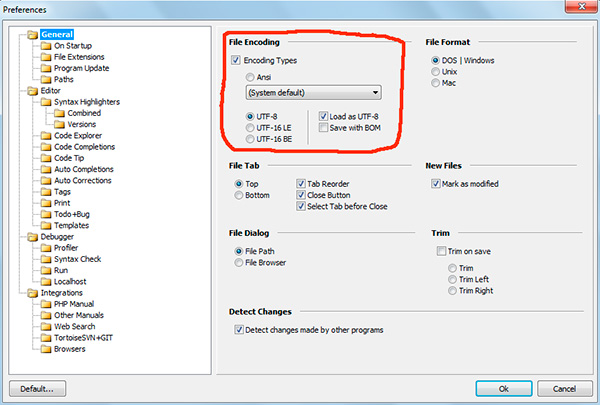

Muszę od razu powiedzieć, że zawsze jest to ostatnia opcja, którą warto wybrać - UTF-8 bez BOM.
Czym więc jest BOM i dlaczego go nie potrzebujemy?
BOM oznacza Oznaczenie kolejności bajtów... Jest to specjalny znak Unicode używany do wskazania kolejności bajtów. plik tekstowy... Zgodnie ze specyfikacją jego użycie jest opcjonalne, ale jeśli BOM jest używany, to musi być ustawiony na początku pliku tekstowego.
Nie będziemy wchodzić w szczegóły pracy. BOM... Dla nas główny wniosek jest następujący: użycie tego znaku serwisowego razem z UTF-8 uniemożliwia programom normalne odczytywanie kodowania, w wyniku czego pojawiają się błędy w pracy skryptów.
Dlatego podczas pracy z UTF-8 używaj dokładnie tej opcji „UTF-8 bez BOM”... Lepiej też nie używać edytorów, w których w zasadzie nie można określić kodowania (powiedzmy, Zeszyt od standardowych programów do Okna).
Kodowanie bieżącego pliku otwartego w edytorze kodu jest zwykle wskazywane na dole okna.
Należy pamiętać, że wpis „ANSI jako UTF-8” w edytorze Notatnik ++ oznacza to samo co „UTF-8 bez BOM”... To jest to samo.
![]()
W programie phpDesigner nie możesz od razu powiedzieć na pewno, czy jest używany BOM, albo nie. Aby to zrobić, kliknij prawym przyciskiem myszy napis „UTF-8”, po czym w wyskakującym okienku widać czy BOM(opcja Zapisz z zestawieniem komponentów).
W edytorze szybki php kodowanie UTF-8 bez BOM oznaczony jako „UTF-8 *”.
Jak możesz sobie wyobrazić, w różnych edytorach wszystko wygląda trochę inaczej, ale masz główną ideę.
Po zapisaniu dokumentu w UTF-8 bez BOM, musisz również upewnić się, że prawidłowe kodowanie jest określone w specjalnym znaczniku meta w sekcji głowa twój dokument html:
Przestrzeganie tych prostych zasad pozwoli już uniknąć wielu spacji za pomocą kodowania.
To wszystko, mam nadzieję, że ta mała wycieczka i wyjaśnienia pomogły ci lepiej zrozumieć, czym są kodowania, czym one są i jak działają.
Jeśli interesuje Cię ten temat z bardziej praktycznego punktu widzenia, polecam zapoznanie się z moim samouczkiem wideo.
Dmitrij Naumenko.
PS Przyjrzyj się bliżej samouczkom premium na temat różnych aspektów tworzenia witryny, a także bezpłatny kurs na tworzeniu od podstaw własnego systemu CMS w PHP. Wszystko to pomoże Ci szybciej i łatwiej opanować różne technologie tworzenia stron internetowych.
Podobał Ci się materiał i chcesz Ci podziękować?
Po prostu podziel się z przyjaciółmi i współpracownikami!
|
Kod (binarny) |
(dziesiętny bez znaku) |
(ze znakiem dziesiętnym) |
|
|
A (duża łacina) | |||
|
B (duża łacina) | |||
|
a (mała łacina) | |||
|
A (duży rosyjski) W kodowaniu ANSI | |||
|
A (duży rosyjski) W kodowaniu ASCII |
Podobny kod, jak pokazano powyżej, również dopasowuje liczbę całkowitą od 0 do 255 w formacie bez znaku. Tak więc każdy znak ma liczbę całkowitą, zwaną także kodem znaku. Zbiór kodów znaków nazywa się tabela kodów lub kodowanie .
W przypadku komputerów osobistych najczęściej tabele kodów ANSI (American National Standard Institute) i ASCII (American Standard Code for Information Interchange). Tabela ANSI jest używana w Windows, a ASCII w DOS. Jednak w tych dwóch tabelach pierwsze 128 kodów (0 do 127) mecz ; różnią się jedynie kolejnymi 128 kodami służącymi do przechowywania narodowych (rosyjskich) liter i symboli „pseudografiki”.
W podanych tabelach oznaczenie KS oznacza „kod znakowy” i Z- "symbol".
Standardowa część tabeli znaków (ascii-ansi)
Niektóre z powyższych symboli mają specjalne znaczenie. Na przykład znak z kodem 9 oznacza znak tabulacji poziomej, znak z kodem 10 - znak nowego wiersza, znak z kodem 13 - znak powrotu karetki.
 Błędy w osobliwości?
Błędy w osobliwości? Just Cause 2 ulega awarii
Just Cause 2 ulega awarii Terraria się nie uruchamia, co mam zrobić?
Terraria się nie uruchamia, co mam zrobić?