Što je unicode kodiranje. Zašto vam je trebao Unicode? Preduvjeti za stvaranje i razvoj Unicodea
Što je kodiranje
Na ruskom se "skup znakova" također naziva "skup znakova", a proces korištenja ove tablice za prevođenje informacija iz računalne reprezentacije u ljudski, a karakteristika tekstualna datoteka, što odražava upotrebu određenog sustava kodova u njemu pri prikazivanju teksta.
Sustav prezentacije definiran je brojnim pravilima, a primjena tih pravila na izvornu informaciju vrši se postupkom kodiranja. Obrnuti proces naziva se dekodiranje. Zatim promatramo specifičnije aspekte kao što su kodiranje signala, kodiranje znakova, kodiranje ljudskog genoma i kvantno kodiranje. Na kraju će se objasniti osnovni pojmovi kompresije podataka i najčešće korištene metode šifriranja.
U ovom odjeljku vidjet ćemo kako su se ljudi kroz povijest ulagali veliki napori da se izraze s ostatkom svoje rodbine na jednostavan i intuitivan način, kodirajući informacije različitim metodama. Ove su se metode razvijale kroz povijest bez predstavljanja sofisticiranih metoda koje danas koristimo za prve koje su korištene jer je za to bila potrebna velika evolucija, što će se vidjeti u ovom odjeljku.
Kako je tekst kodiran
Skup simbola koji se koristi u pisanju teksta u računalnoj se terminologiji naziva abeceda; broj znakova u abecedi obično se naziva njegova moć. Za prezentaciju tekstualne informacije računalo najčešće koristi abecedu kapaciteta 256 znakova. Jedan od njegovih znakova nosi 8 bitova informacija, stoga binarni kôd svakog znaka zauzima 1 bajt memorije računala. Svi znakovi takve abecede numerirani su od 0 do 255, a svaki broj odgovara 8-bitnom binarnom kodu, koji je redni broj znaka u binarnom sustavu zapisa - od 00000000 do 11111111. Samo prvih 128 znakova s brojevi od nule (binarni kod 00000000) do 127 (01111111). To uključuje mala slova i velika slova Latinica, brojevi, interpunkcijski znakovi, zagrade itd. Preostalih 128 kodova, počevši od 128 (binarni kod 10000000) i završavajući s 255 (11111111), koriste se za kodiranje slova nacionalnih abeceda, službenih i znanstvenih simbola.
Evolucija kodiranja signala
Zastarjelost je sve što znamo ovaj trenutak, kao što je to bilo u dogledno vrijeme sa prethodnim metodama. Kroz povijest su mornari koristili signale za prenošenje hitnih poruka drugim mornarima. To su svjetlosni signali koji se proizvode pomoću velikih projektora sa sustavima koji omogućuju svjetlosne nalete, obično pomoću rešetki smještenih ispred fokusa. Za uspostavu veze Morseov kod koristi se svjetlosnim signalima.
To su signali koji se prenose vibracijama u zraku. Zbog tromosti uređaja potrebnih za prijenos, ovo je vrlo spor medij. Preneseni signali koriste Morseov kod za prijenos informacija. Osim tradicionalnog Morseovog koda u međunarodnom kodu koji je ugrađen, postoje i druge vrste standardiziranih signala koje bi svaki nautičar trebao savršeno razumjeti.
Vrste kodiranja
Najpoznatija tablica kodiranja je ASCII (American Standard Code for Information Interchange). Prvobitno je razvijen za prijenos tekstova telegrafskim putem, a u to vrijeme bio je 7-bitni, odnosno koristilo se samo 128 7-bitnih kombinacija za kodiranje engleskih znakova, službenih i kontrolnih znakova. U ovom slučaju, prve 32 kombinacije (kodovi) poslužile su za kodiranje kontrolnih signala (početak teksta, kraj retka, povratak nosača, poziv, kraj teksta itd.). U razvoju prvih IBM računala ovaj je kôd korišten za predstavljanje simbola u računalu. Od godine u izvorni kod ASCII je imao samo 128 znakova, za njihovo kodiranje dovoljne su bile vrijednosti bajta, u kojima je 8. bit 0. Engleski (grčki, njemački umlauti, francuska dijakritika itd.). Kad su se računala počela prilagođavati drugim zemljama i jezicima, više nije bilo dovoljno mjesta za nove simbole. Kako bi u potpunosti podržao druge jezike osim engleskog, IBM je uveo nekoliko tablica kodova specifičnih za pojedine zemlje. Tako je za skandinavske zemlje predložena tablica 865 (nordijska), za arapske zemlje - tablica 864 (arapski), za Izrael - tablica 862 (Izrael) i tako dalje. U ovim tablicama neki su kodovi iz druge polovice tablice kodova korišteni za predstavljanje znakova nacionalnih abeceda (isključujući neke pseudo-grafičke znakove). Situacija s ruskim jezikom razvila se na poseban način. Očito se može izvršiti zamjena znakova u drugoj polovici tablice kodova različiti putevi... Tako se za ruski jezik pojavilo nekoliko različitih tablica kodiranja ćiriličnih znakova: KOI8-R, IBM-866, CP-1251, ISO-8551-5. Svi oni predstavljaju simbole prve polovice tablice na isti način (od 0 do 127), a razlikuju se u predstavljanju simbola ruske abecede i pseudo-grafike. Za jezike poput kineskog ili japanskog 256 znakova općenito nije dovoljno. Osim toga, uvijek postoji problem ispisivanja ili spremanja tekstova u jednu datoteku u isto vrijeme različiti jezici(na primjer, prilikom citiranja). Stoga, univerzalni tablica kodova UNICODE, koji sadrži simbole koji se koriste u jezicima svih naroda svijeta, kao i različite službene i pomoćne simbole (interpunkcijski znakovi, matematički i tehnički simboli, strelice, dijakritičke oznake itd.). Očito, jedan bajt nije dovoljan za kodiranje tako velikog skupa znakova. Stoga UNICODE koristi 16-bitne (2-bajtne) kodove za predstavljanje 65.536 znakova. Do danas je korišteno oko 49.000 kodova (posljednja značajna promjena bila je uvođenje simbola valute EURO u rujnu 1998.). Radi kompatibilnosti s prethodnim kodiranjima, prvih 256 kodova je isto što i ASCII standard. U standardu UNICODE, osim specifičnih binarni kod(ti se kodovi obično označavaju slovom U, nakon čega slijedi znak + i stvarni kôd u heksadecimalnom prikazu) svakom znaku se dodjeljuje određeno ime. Druga komponenta UNICODE standard su algoritmi za konverziju jedan-na-jedan UNICODE kodova u nizu bajtova promjenjive duljine. Potreba za takvim algoritmima je zbog činjenice da ne mogu sve aplikacije raditi s UNICODE-om. Neke aplikacije razumiju samo 7-bitne ASCII kodove, druge aplikacije razumiju 8-bitne ASCII kodove. Takve aplikacije koriste takozvane proširene ASCII kodove za predstavljanje znakova koji se ne uklapaju u skup od 128 ili 256 znakova, kada su znakovi kodirani nizovima bajtova promjenjive duljine. UTF-7 se koristi za reverzibilno pretvaranje UNICODE kodova u proširene 7-bitne ASCII kodove, a UTF-8 se koristi za reverzibilno pretvaranje UNICODE kodova u proširene 8-bitne ASCII kodove. Imajte na umu da i ASCII i UNICODE i drugi standardi kodiranja znakova ne definiraju slike znakova, već samo sastav skupa znakova i način na koji je predstavljen u računalu. Osim toga (što možda nije odmah očito), redoslijed nabrajanja znakova u skupu vrlo je važan jer utječe na algoritme sortiranja na najznačajniji način. To je tablica korespondencije simbola iz određenog skupa (recimo, simboli koji se koriste za predstavljanje informacija o Engleski jezik, ili na različitim jezicima, kao u slučaju UNICODE -a) i označavaju izraz tablica kodiranja znakova ili skup znakova. Svako standardno kodiranje ima naziv, na primjer, KOI8-R, ISO_8859-1, ASCII. Nažalost, ne postoji standard za kodiranje imena.
Koristi se za komunikaciju između obližnjih brodova kako bi mogao poštivati frekvenciju radija koji se koristi, a ne koristiti ga bespotrebno zauzimajući taj kanal ili zato što je potrebno uspostaviti komunikaciju i radio ne radi ispravno.
Zastavice se koriste za obavljanje komunikacije, pa će ovisno o položaju koji zauzima osoba koja izvodi signale imati vrijednost ili nešto drugo. Pridružena značenja ista su kao korištenje zastavica sa slovima od A do Z, brojeva od 0 do 9 i signala pauze i greške.
Radiotelegrafija i radiotelefonija
S gore navedenim metodama, istodobna komunikacija u oba smjera je nemoguća, pa su one bile od točke do točke. Zahvaljujući pojavi radiotelegrafije, ova vrsta komunikacije je moguća. Radiotelegrafija se temelji na Maxwellovoj teoriji širenja valova u svemiru. Tako je rođena bežična telegrafija, koja je jedan od najvažnijih napretka u telekomunikacijama svih vremena.
Uobičajena kodiranja
ISO 646 o ASCII EBCDIC ISO 8859: o ISO 8859-1-ISO 8859-11, ISO 8859-13, ISO 8859-14, ISO 8859-15 o CP437, CP737, CP850, CP852, CP855, CP857, CP858, CP860, CP861, CP863, CP865, CP866, CP869 Microsoftova kodiranja Windows: o Windows-1250 za jezike Srednje Europe koji koriste latinična slova o Windows-1251 za ćirilična pisma o Windows-1252 za zapadne jezike o Windows-1253 za grčki o Windows-1254 za turski o Windows-1255 za hebrejski o Windows-1256 za arapski jezik Windows-1257 za baltičke jezike o Windows-1258 za vijetnamski jezik MacRoman, MacCyrillic KOI8 (KOI8-R, KOI8-U ...), KOI-7 bugarsko kodiranje ISCII VISCII Big5 (najpoznatija verzija Microsoft CP950) o HKSCS Guobiao o GB2312 o GBK (Microsoft CP936) o GB18030 Shift JIS za japanski (Microsoft CP932) EUC-KR za korejski (Microsoft CP949) ISO-2022 i EUC za kinesko pisanje UTF- 8 i UTF-16 kodiraju Unicode znakoveOva dokumentacija je premještena u arhivu i nije podržana.
Kodiranje danas
Još pred nama će biti radiotelefonija, koja nije ništa drugo do sposobnost moduliranja glasa preko radio valova pomoću teorijske osnove izložena u radiotelegrafiji.
Kodiranje signala
Ovo je vrlo često korišten postupak u kojem se prije niza signala analogni tip transkribirano u digitalne signale. Na taj način olakšava naknadnu obradu, kao i poboljšava fizičke karakteristike.Odnosno, analogni signal je vrlo osjetljiv na promjene mogućih smetnji, to je zbog činjenice da se izvorni signal vrlo teško obnavlja, budući da vrijednosti koje ovaj signal može imati mogu biti beskonačne. Usporedimo li ga s digitalnim signalom koji ima određeni broj mogućih vrijednosti. Ova činjenica olakšava dohvat vrijednosti u digitalnom signalu i stoga se može koristiti za komunikaciju na daljinu.
Korištenje Unicode kodiranja
.NET Framework 3.5
Ažurirano: studeni 2007
Uobičajene aplikacije za vrijeme izvođenja koriste kodiranje za pretvaranje znakova iz unutarnjeg prikaza (Unicode) u drugi prikaz. Dekodiranje se koristi za pretvaranje znakova natrag iz vanjskih kodiranja (ne-Unicode) u interni prikaz. Imenski prostor sadrži niz klasa koje aplikacijama omogućuju kodiranje i dekodiranje znakova. Za pregled ovih klasa pogledajte.
U ovom postupku možemo razlikovati tri dobro diferencirane faze: uzorkovanje, kvantifikacija i kodifikacija. Kvantifikacija: sastoji se u procjeni vrijednosti svakog uzorka, tako da se svakom uzorku dodijeli jedna od mogućih vrijednosti rezultirajućeg digitalni signal... Postupak kvantizacije uzrokuje šum kvantizacije uzrokovan brojem mogućih vrijednosti analogni signal za digitalni signal. Sastoji se od pretvaranja vrijednosti dobivenih tijekom procesa kvantizacije u binarni sustav pomoću brojnih unaprijed postavljenih kodova.
- Uzorkovanje: Sastoji se od uzorkovanja amplitude ulaznog signala.
- Visoko važan parametar u ovom procesu brojem uzoraka u sekundi.
- Kodiranje.
Koristi se za ne-Unicode kodiranje. Klasa podržava širok raspon ANSI / ISO kodiranja.
Primjer koda u nastavku koristi metodu GetEncoding potrebni objekt kodiranja za određenu kodnu stranicu. Metoda GetBytes pozvan na željeni objekt kodiranja za pretvaranje Unicode niza u prikaz bajtova u željenom kodiranju. Zaslon će prikazati bajt prikaz niza na određenoj kodnoj stranici.
Temelji se na kodiranju s jednim polaritetom, kako naziv govori. Dakle, obično binarna vrijednost jednaka pretpostavlja vrijednost izlaznog signala jednaku jedan, a vrijednost jednaka nuli dopušta nultu vrijednost u izlaznom signalu.
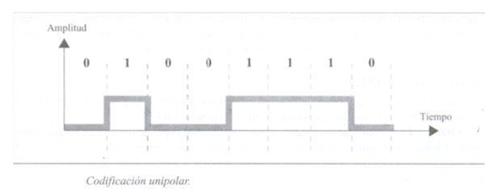
Ovo je tip kodiranja koji se danas najčešće koristi. Temelji se na kodiranju dvaju polariteta za predstavljanje binarnih informacija. Možemo pronaći sljedeću klasifikaciju polarnog kodiranja. 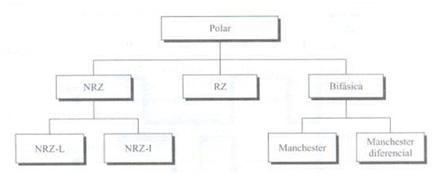
Karakterizira ga činjenica da signal uvijek ima pozitivnu ili negativnu vrijednost. Možemo jasno razlikovati vrste.
Uvozi Sustav Uvozi System.IO Uvozi System.Globalization Uvozi System.Text Javna klasa Encoding_UnicodeToCP Javno dijeljena pod glavna () "Pretvara ASCII znakove u bajtove. "Prikazuje prikaz bajtova niza u"navedena kodna stranica. „Kodna stranica 1252 predstavlja latinične znakove. PrintCPBytes ("Zdravo, Svijete!", 1252) "Kodna stranica 932 predstavlja japanske znakove. PrintCPBytes ("Zdravo, Svijete!", 932) "Pretvara japanske znakove. PrintCPBytes (, 1252) PrintCPBytes ( "\ u307b, \ u308b, \ u305a, \ u3042, \ u306d", 932) End Sub Public Shared Sub PrintCPBytes (str kao niz, kodna stranica kao cijeli broj) Dim targetEncoding As Encoding Dim encodedChars () Kao bajt "Dobiva kodiranje za navedenu kodnu stranicu. targetEncoding = Kodiranje.GetEncoding (codePage) "Dobiva prikaz bajta navedenog niza. encodedChars = targetEncoding.GetBytes (str) "Ispisuje bajtove. Console.WriteLine ( "Prikaz bajta" (0) "u CP" (1) ":", _ str, codePage) Dim i As Integer For i = 0 Za encodedChars.Length - 1 Console.WriteLine ("Byte (0): (1)", i, encodedChars (i)) Next i End Sub End Class
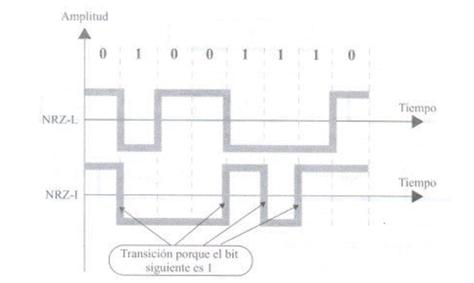
Obično, ako je bit postavljen na jedan, signal će biti pozitivan, ako je nula, signal će biti negativan. Dakle, ova vrijednost ovisi ne samo o trenutnom bitu, već i o prethodnom bitu. Dakle, pouzdaniji je.
Karakterizira ga korištenje tri moguće izlazne razine. Čini se da se mali mijenja iz pozitivnog u nulu i iz nule u negativan u pozitivan. Svaka transakcija događa se u sredini intervala, kao što je prikazano na sljedećoj slici. Ova vrsta kodiranja također omogućuje pokretanje postupka sinkronizacije korištenjem prijelaza generiranih na pola utora.
 Što je bolje iPhone 6s ili 6 plus
Što je bolje iPhone 6s ili 6 plus Gdje su snimke zaslona i igre u mapi Steam?
Gdje su snimke zaslona i igre u mapi Steam? Kako izbrisati ili vratiti sve izbrisane dijaloge VKontakte odjednom?
Kako izbrisati ili vratiti sve izbrisane dijaloge VKontakte odjednom?