Ansi tablica za ruske znakove. Kodiranja: korisne informacije i kratka retrospektiva
Ponekad vam čak ni prilično iskusni stručnjak neće odmah reći koja određena vrijednost pritiska ili duljine u jednom sustavu odgovara vrijednostima u drugom sustavu vrijednosti.
Do olakšati vam ovaj zadatak, nudimo tablice omjera vrijednosti pritiska i duljine u europskim i američkim sustavima s malim objašnjenja... No, prvo nekoliko riječi o samim standardima.
DIN je njemački standard (označava Deutsches Institut für Normung, odnosno razvio Njemački institut za standardizaciju), koji je razvijen strogo u okvirima odredbi Međunarodne organizacije za standardizaciju - ISO (Međunarodna organizacija za standardizaciju).
ANSI- standard usvojen u Sjedinjenim Američkim Državama. Zalaže se za American National Standards Institute, odnosno standard američkog Instituta za nacionalne standarde.
U skladu s tim, standarde ANSI određuje ova institucija, i to daleko ne uvijek između standarda DIN i ANSI točno sukladnost na raznim poljima.
Pretvaranje jedinica tlaka iz ANSI u DIN
Ovdje je sve jednostavno: ako je standard ANSI broj 150 stoji nasuprot tlaku - to znači da je nominalni (za koji je ventil dizajniran) tlak 20 bara, 300 - 50 bara itd. Maksimalna vrijednost za ANSI klasa- 2500 bit će jednako 420 bara prema europskom standardu DIN.
Koristeći ovu tablicu, nije teško prevesti vrijednosti tlaka i natrag: od DIN v ANSI, iako naši inženjeri moraju mnogo provoditi takav prijevod rjeđe.
Pretvorba jedinica duljine iz američkog sustava u europski (ruski)
Kao što je poznato, Amerikanci sve se mjeri inčima i stopalima, a mi i Europljani- milimetri, centimetri i metri, odnosno, kao i velika većina država u svijetu, živimo metrički sustav jedinica.
Kako pretvoriti inče u milimetre? Zapravo, to također nije teško, samo zapamtite da je 1 inč jednako 25,4 mm. Međutim, često znamenka iza decimalnog zareza zapušteno a za ravnomjerno brojanje naznačite to 1 inč = 25 mm.
Dakle, ako je, na primjer, presjek ulaza 2 inča prema američkom sustavu mjera, tada, prevođenjem ove vrijednosti u naš sustav mjera prema gore navedenom pravilu, dobivamo 50 mm ili, točnije, 51 mm (zaokruživanje 50,8 prema pravilima) ...
Ostaje dodati da je promjer u tehnički karakteristike su označene latiničnim slovima DN a često je naznačeno upravo u inča, a pritisak je označen slovima PN a naznačeno je najčešće u barovi- u svakom slučaju najviše koristimo upravo takvu oznaku udobno.
I sljedeća tablica će pomoći možete izračunati ne samo precizan broj milimetara u jednom inču (s točnošću tisućinke milimetra), ali također će vam pomoći da saznate koliko milimetara sadrži, na primjer, u 2,5 inča.
Da biste to učinili, pronađite stupac 2 "" (2 inča), a s lijeve strane potražite 1/2. Ukupno 2,5 inča = 63,501 mm, što je sasvim moguće zaokružiti do 64 mm, a na primjer 6,25 inča (tj. 6 i 1/4) = 158,753 mm ili 159 mm.
|
| Inči "" u milimetrima |
|||||||
|
| ||||||||
|
| ||||||||
Ako trebate unijeti samo nekoliko posebni znakovi ili znakove, možete koristiti tablicu znakova ili tipkovne prečace. Za popis ASCII znakova pogledajte donje tablice ili Umetanje nacionalnih slova pomoću tipkovnih prečaca.
Bilješke:
Umetanje ASCII znakova
Da biste umetnuli ASCII znak, pritisnite i držite tipku ALT, a zatim upišite kod znaka. Na primjer, da biste umetnuli znak stupnja (º), držite pritisnutu tipku ALT i upišite numerička tipkovnica kod 0176.
Bilješka:
Umetanje Unicode znakova
Važno: Neki Microsoftovih programa Office, kao što su PowerPoint i InfoPath, ne može pretvoriti Unicode kodove znakova. Ako vam je potreban Unicode znak i koristite neki od programa koji ne podržavaju Unicode znakove, upotrijebite za unos znakova koji vam mogu zatrebati.
Bilješke:
Zatvorite sve programe.
Dvaput kliknite ikonu Instalacija i uklanjanje programa na upravljačke ploče.
Učinite nešto od sljedećeg:
ako je prijava Microsoft Office instaliran kao dio sustava Microsoft Office, odaberite Microsoft Office na terenu Instalirani programi a zatim kliknite Zamijeniti;
Ako Uredska aplikacija je instaliran zasebno, kliknite na njegovo ime na popisu Instalirani programi a zatim kliknite Promijeniti.
Brojeve treba upisivati na numeričku tipkovnicu, a ne alfanumeričke. Ako trebate pritisnuti za unos brojeva na numeričkoj tipkovnici NUM tipka ZAKLJUČAJ, provjeri je li to učinjeno.
Ako imate problema s pretvaranjem Unicode koda u znak, upišite kôd na numeričkoj tipkovnici, odaberite ga, a zatim pritisnite Alt + X.
V. Microsoft Windows XP i novije verzije Unicode univerzalnog fonta instaliraju se automatski. U sustavu Microsoft Windows 2000 font Unicode mora se instalirati ručno.
U sustavu Microsoft Windows 2000
U dijaloškom okviru Instaliranje sustava Microsoft Office 2003 odaberite opciju Dodajte ili uklonite komponente a zatim kliknite Unaprijediti.
Molimo izaberite Dodatna prilagodba aplikacije i pritisnite tipku Unaprijediti.
Proširite popis Uobičajeni uredski alati.
Proširite popis Podrška za više jezika.
Pritisnite ikonu Univerzalni font i odaberite željenu opciju instalacije.
Pomoću tablice simbola
Tablica simbola ugrađena je u Microsoft Windows program koji vam omogućuje pregled znakova dostupnih u odabranom fontu. Pomoću tablice simbola možete kopirati pojedinačne simbole ili skupine simbola u međuspremnik, a zatim ih zalijepiti u program koji ih podržava.
Pritisnite gumb Početak, a zatim odaberite Programi, Standard, Servis i tablica simbola.
Da biste odabrali simbol u tablici simbola, kliknite ga, pritisnite gumb Odaberi, kliknite desni klik mišem na mjestu dokumenta u koji želite dodati simbol i odaberite naredbu Umetnuti.
Uobičajeni kodovi znakova
Za više znakova u znaku, pogledajte članak instaliran na vašem računalu, kodove znakova ASCII ili dijagram skripte koda znaka Unicode.
|
Znak |
Znak |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Simboli valute |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Pravni simboli |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Razlomci |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Znakovi interpunkcije i dijalekta |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Simboli obrazaca |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Uobičajeni dijakritički kodoviZa potpuni popis glifova i pridruženih kodova znakova pogledajte.
|
Okvir za pokretanje: brzo reagirajući izgled
Video tutorial korak po korak o osnovama responzivnog izgleda u okviru Bootstrap.
Naučite jednostavno, brzo i učinkovito tipkati pomoću moćnog i praktičnog alata.
Raspored po narudžbi i plaćanje.
Besplatni tečaj "WordPress stranica"
Želite svladati WordPress CMS?
Preuzmite vodiče o dizajnu i izgledu web stranica WordPress.
Naučite raditi s temama i izrezati izgled.
Besplatni video tečaj o crtanju dizajna web mjesta, izgledu i instalaciji na CMS WordPress!
* Zadržite pokazivač miša za pauziranje pomicanja.
Natrag naprijed
Kodiranja: korisne informacije i kratka retrospektiva
Odlučio sam napisati ovaj članak kao mali pregled o pitanju kodiranja.
Shvatit ćemo što je kodiranje općenito i dotaknuti se povijesti kako su se oni načelno pojavili.
Govorit ćemo o nekim njihovim značajkama te također razmotriti trenutke koji nam omogućuju svjesniji rad s kodiranjima i izbjegavanje pojave na mjestu tzv. krakozyabrov, tj. nečitljivi likovi.
Pa, idemo ...
Što je kodiranje?
Jednostavno rečeno, kodiranje je tablica preslikavanja znakova koju možemo vidjeti na ekranu, u određene numeričke kodove.
Oni. svaki znak koji unosimo s tipkovnice ili vidimo na ekranu monitora kodiran je određenim nizom bitova (nula i jedinica). 8 bitova, kao što vjerojatno znate, jednaki su 1 bajtu informacija, ali o tome kasnije.
Izgled samih simbola određen je datotekama fontova koji su instalirani na vašem računalu. Stoga se proces prikaza teksta na ekranu može opisati kao stalno preslikavanje nizova nula i jedinica na neke specifične znakove koji čine font.
Može se smatrati rodonačelnikom svih modernih kodiranja ASCII.
Ova kratica znači Američki standardni kôd za razmjenu informacija(Američka standardna tablica kodiranja za znakove za ispis i neke posebne kodove).
to jednobajtno kodiranje, koji je u početku sadržavao samo 128 znakova: slova latinske abecede, arapske brojke itd.

Kasnije je proširen (u početku nije koristio svih 8 bitova), pa je postalo moguće koristiti ne 128, već 256 (2 do 8. stupnja) različiti likovi koje se mogu kodirati u jedan bajt informacija.
Ovo poboljšanje omogućilo je dodavanje u ASCII simboli nacionalnih jezika, uz već postojeću latinicu.
Postoji mnogo mogućnosti za prošireno ASCII kodiranje zbog činjenice da u svijetu postoji i mnogo jezika. Mislim da su mnogi od vas čuli za takvo kodiranje kao KOI8-R je također prošireno ASCII kodiranje dizajniran za rad s likovima ruskog jezika.
Sljedećim korakom u razvoju kodiranja može se smatrati pojava tzv ANSI kodiranja.
Zapravo, bili su isti proširene verzije ASCII međutim, s njih su uklonjeni različiti pseudo-grafički elementi i dodani tipografski simboli za koje prije nije bilo dovoljno "slobodnog prostora".
Primjer takvog ANSI kodiranja je dobro poznat Windows-1251... Osim tipografskih znakova, ovo kodiranje uključivalo je i slova abecede jezika bliskih ruskom (ukrajinski, bjeloruski, srpski, makedonski i bugarski).
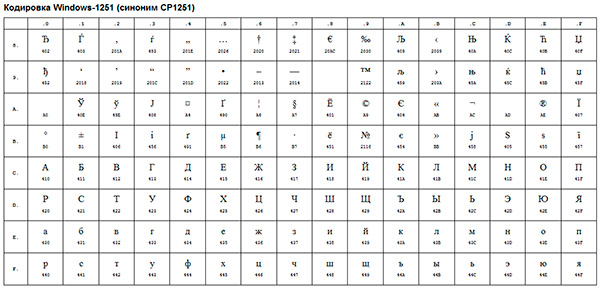
ANSI kodiranje je skupni naziv... Zapravo, stvarno kodiranje pri korištenju ANSI -ja bit će određeno onim što je navedeno u vašem registru operacijski sustav Windows. U slučaju ruskog jezika, to će biti Windows-1251, međutim, za druge jezike to će biti drugačija vrsta ANSI-ja.
Kako razumijete, hrpa kodiranja i nedostatak jedinstvenog standarda nisu donijeli sreću, što je bio razlog čestih sastanaka s tzv. krakozyabrami- nečitljiv besmislen skup znakova.
Razlog njihove pojave je jednostavan - jest pokušavajući prikazati znakove kodirane s jednom tablicom kodiranja koristeći drugu tablicu kodiranja.
U kontekstu razvoja weba možemo se susresti s krakozyabrama kada, na primjer, Ruski tekst greškom je spremljen u pogrešnom kodiranju koje se koristi na poslužitelju.
Naravno, ovo nije jedini slučaj kada možemo dobiti nečitljiv tekst - ovdje postoji mnogo opcija, pogotovo ako uzmete u obzir da postoji i baza podataka u kojoj su informacije također pohranjene u određenom kodiranju, postoji mapiranje veza s bazom podataka itd.
Pojava svih ovih problema poslužila je kao poticaj za stvaranje nečeg novog. To je morao biti kodiranje koje je moglo kodirati bilo koji jezik na svijetu (uostalom, uz pomoć jednobajtnih kodiranja, na svu želju, ne mogu se opisati svi znakovi, recimo, kineskog jezika, gdje očito postoji više od 256 njih), sve dodatne posebne znakove i tipografiju.
Ukratko, bilo je potrebno stvoriti univerzalno kodiranje koje bi jednom zauvijek riješilo problem krakozyabrova.
Unicode-Univerzalno kodiranje teksta (UTF-32, UTF-16 i UTF-8)
Sam je standard 1991. godine predložila neprofitna organizacija Unicode konzorcij(Konzorcij Unicode, Unicode Inc.), a prvi rezultat njegova rada bilo je stvaranje kodiranja UTF-32.
Usput, sama kratica UTF stoji za Format transformacije Unicode(Unicode format pretvaranja).
U ovom kodiranju, za kodiranje jednog znaka, trebalo je koristiti isto toliko 32 bit, tj. 4 bajta informacija. Usporedimo li ovaj broj s jednobajtnim kodiranjem, dolazimo do jednostavnog zaključka: da biste kodirali 1 znak u ovom univerzalnom kodiranju, trebate 4 puta više bitova, što datoteku čini 4 puta težom.
Također je očito da broj znakova koji bi se potencijalno mogli opisati pomoću ovog kodiranja prelazi sve razumne granice i tehnički je ograničen na broj jednak 2 do 32. stepena. Jasno je da se radi o očitom pretjerivanju i rasipanju u smislu težine datoteka, pa ovo kodiranje nije postalo rašireno.
Zamijenila ju je novi razvoj- UTF-16.
Kako naziv govori, u ovom kodiranju je kodiran jedan znak ne više 32 bita, već samo 16(tj. 2 bajta). Očigledno, ovo čini svaki znak dva puta "lakšim" od UTF-32, ali dvostruko "težim" od bilo kojeg jednobajtnog kodiranog znaka.
Broj znakova dostupnih za kodiranje u UTF-16 je najmanje 2 do 16. stupnja, tj. 65536 znakova. Čini se da je sve u redu, osim što je konačna veličina kodnog prostora u UTF-16 proširena na više od milijun znakova.
Međutim, ovo kodiranje nije u potpunosti zadovoljilo potrebe programera. Na primjer, ako pišete koristeći isključivo latinične znakove, nakon prelaska s proširene verzije ASCII kodiranja na UTF-16, težina se svake datoteke udvostručila.
Kao rezultat, učinjen je još jedan pokušaj stvaranja nečeg univerzalnog, i da je nešto dobro poznato kodiranje UTF-8.
UTF-8- ovo je kodiranje više bajtova s promjenjivom duljinom znakova... Gledajući naziv, moglo bi se pomisliti, analogno UTF-32 i UTF-16, da se 8 kodova koristi za kodiranje jednog znaka, ali to nije tako. Točnije, nije baš tako.
To je zato što UTF-8 pruža najbolju kompatibilnost sa starijim sustavima koji su koristili 8-bitne znakove. Za kodiranje jednog znaka u UTF-8 se zapravo koristi od 1 do 4 bajta(hipotetički je moguće do 6 bajtova).
U UTF-8, svi latinični znakovi kodirani su u 8 bita, baš kao i u ASCII kodiranju... Drugim riječima, osnovni dio kodiranja ASCII (128 znakova) prešao je u UTF-8, što vam omogućuje da "potrošite" samo 1 bajt na njihovo predstavljanje, uz održavanje univerzalnosti kodiranja, za koje je sve započeto.
Dakle, ako je prvih 128 znakova kodirano s 1 bajtom, tada su svi drugi znakovi kodirani s 2 ili više bajtova. Konkretno, svaki ćirilični znak kodiran je s točno 2 bajta.
Tako smo dobili univerzalno kodiranje koje nam omogućuje pokrivanje svih mogućih znakova koje je potrebno prikazati, bez nepotrebnog "ponderiranja" datoteka.
Sa ili bez BOM -a?
Ako ste radili s uređivači teksta(uređivači koda) poput Notepad ++, phpDesigner, brzi php itd., vjerojatno ste skrenuli pozornost na činjenicu da pri određivanju kodiranja u kojem će se stranica stvoriti možete odabrati, u pravilu, 3 opcije:
ANSI
- UTF-8
- UTF-8 bez BOM-a
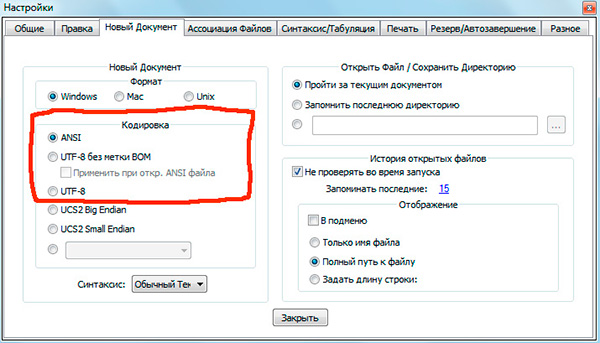
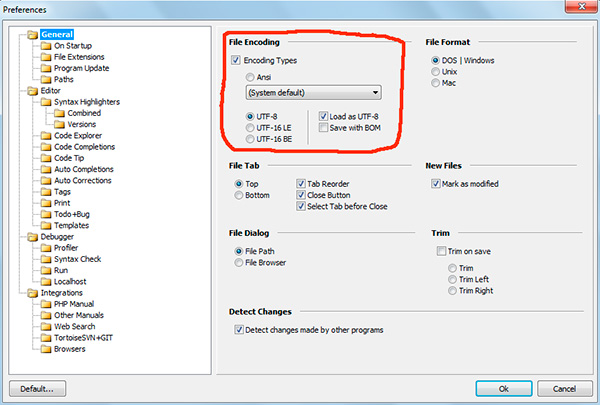

Moram odmah reći da je to uvijek posljednja opcija koju vrijedi izabrati - UTF-8 bez BOM-a.
Dakle, što je BOM i zašto nam ne treba?
BOM stoji za Oznaka redoslijeda bajtova... Ovo je poseban Unicode znak koji se koristi za označavanje redoslijeda bajtova. tekstualna datoteka... Prema specifikaciji, njegova je upotreba opcionalna, ali ako BOM se koristi, tada se mora postaviti na početak tekstualne datoteke.
Nećemo ulaziti u detalje rada. BOM... Za nas je glavni zaključak sljedeći: korištenje ovog servisnog znaka zajedno s UTF-8 sprječava programe da normalno čitaju kodiranje, uslijed čega dolazi do pogrešaka u radu skripti.
Stoga, pri radu s UTF-8, koristite točno tu opciju "UTF-8 bez BOM-a"... Također je bolje ne koristiti uređivače u kojima u načelu ne možete navesti kodiranje (recimo, Bilježnica od standardnih programa do Windows).
Kodiranje trenutne datoteke otvorene u uređivaču koda obično je naznačeno pri dnu prozora.
Napominjemo da je unos "ANSI kao UTF-8" u uredniku Notepad ++ znači isto što i "UTF-8 bez BOM-a"... Ovo je isto.
![]()
U programu phpDesigner ne možete odmah sa sigurnošću reći da li se koristi BOM, ili ne. Da biste to učinili, desnom tipkom miša kliknite natpis "UTF-8", nakon čega u skočnom prozoru možete vidjeti je li BOM(opcija Uštedite pomoću BOM -a).
U uredniku brzi php kodiranje UTF-8 bez BOM-a označeno kao "UTF-8 *".
Kao što možete zamisliti, u različitim urednicima sve izgleda malo drugačije, ali vi shvaćate glavnu ideju.
Nakon što se dokument spremi u UTF-8 bez BOM-a, također morate biti sigurni da je ispravno kodiranje navedeno u posebnoj meta oznaci u odjeljku glava vaš html dokument:
Poštivanje ovih jednostavnih pravila već će vam omogućiti da izbjegnete mnoge razmake s kodiranjima.
To je sve, nadam se da vam je ovaj mali izlet i objašnjenja pomogao da bolje razumijete što su kodiranja, što su to i kako rade.
Ako vas ova tema zanima s primjenjenijeg stajališta, preporučujem da proučite moj video vodič.
Dmitrij Naumenko.
p.s. Pobliže pogledajte premium tutoriale o raznim aspektima izgradnje web stranica besplatni tečaj o stvaranju vlastitog CMS-sustava u PHP-u od nule. Sve će vam to pomoći da brže i lakše savladate razne tehnologije za razvoj weba.
Svidio vam se materijal i htjeli vam zahvaliti?
Samo podijelite sa svojim prijateljima i kolegama!
|
Kôd (binarni) |
(decimata bez potpisa) |
(decimalna oznaka potpisana) |
|
|
A (veliki latinica) | |||
|
B (veliki latinica) | |||
|
a (mali latinski) | |||
|
A (veliki ruski) U kodiranju ANSI | |||
|
A (veliki ruski) U kodiranju ASCII |
Sličan kôd, kao što je gore prikazano, također odgovara cijelom broju od 0 do 255 u nepotpisanom formatu. Dakle, svaki znak ima cijeli broj, koji se naziva i kod znaka. Zbirka kodova znakova naziva se tablica kodova ili kodiranje .
Za osobna računala najčešći tablice kodova ANSI (American National Standard Institute) i ASCII (American Standard Code for Information Interchange). ANSI tablica koristi se u sustavu Windows, a ASCII u DOS -u. Međutim, u ove dvije tablice prvih 128 kodova (0 do 127) podudarati ; razlikuju se samo u sljedećih 128 kodova koji se koriste za spremanje nacionalnih (ruskih) slova i simbola "pseudo-grafike".
U danim tablicama oznaka KS znači "šifra znaka" i S- "simbol".
Standardni dio tablice znakova (ascii-ansi)
Neki od gore navedenih simbola imaju posebno značenje. Tako, na primjer, znak s kodom 9 označava znak vodoravnog tabelarnog prikaza, znak s kodom 10 - znak unosa retka, znak s kodom 13 - znak povratka nosača.
 Greške u singularnosti?
Greške u singularnosti? Samo se uzrok 2 ruši
Samo se uzrok 2 ruši Terraria se neće pokrenuti, što da radim?
Terraria se neće pokrenuti, što da radim?