Speciální znaky Unicode. Problém rozlišování navenek podobných čísel a písmen.
Každý uživatel internetu, který se snaží nakonfigurovat jednu nebo druhou z jeho funkcí, alespoň jednou viděl na displeji napsané slovo „Unicode“. Co to je, zjistíte přečtením tohoto článku.
Definice
Kódování Unicode je standard kódování znaků. Nabízela ji nezisková organizace Unicode Inc. v roce 1991. Norma je navržena tak, aby kombinovala co nejvíce různých typů znaků v jednom dokumentu. Stránka, která byla vytvořena na jejím základě, může obsahovat písmena a hieroglyfy z různé jazyky(z ruštiny do korejštiny) a matematické znaky... V tomto případě se všechny znaky v tomto kódování zobrazí bez problémů.
Důvody pro vytvoření
Kdysi dávno, dávno předtím jednotný systém"Unicode", kódování bylo zvoleno na základě preferencí autora dokumentu. Z tohoto důvodu je často nutné pro čtení jednoho dokumentu používat různé tabulky. Někdy se to muselo udělat vícekrát, což běžnému uživateli výrazně zkomplikovalo život. Jak již bylo zmíněno, řešení tohoto problému v roce 1991 navrhla nezisková organizace Unicode Inc., která navrhla nový typ kódování znaků. Bylo zamýšleno spojit zastaralé a různorodé standardy. "Unicode" je kódování, které umožnilo dosáhnout v té době nemyslitelného: vytvořit nástroj, který podporuje obrovské množství znaků. Výsledek předčil mnohá očekávání – souběžně se objevily dokumenty obsahující anglický i ruský text, latinské a matematické výrazy.
Vytvoření jednotného kódování ale předcházela potřeba vyřešit řadu problémů, které vyvstaly kvůli obrovské rozmanitosti standardů, které již v té době existovaly. Nejběžnější jsou:
- elfská písmena nebo "krakozyabry";
- omezená znaková sada;
- problém převodu kódování;
- duplikace písem.

Malý historický exkurz
Představte si, že jsou 80. léta. Počítačová technika ještě není tak rozšířená a má jinou podobu než dnes. V té době je každý OS svým způsobem jedinečný a každý nadšenec si ho upravuje pro konkrétní potřeby. Potřeba výměny informací se mění v další zdokonalování všeho na světě. Pokus o čtení dokumentu vytvořeného pod jiným OS často zobrazí na obrazovce nesrozumitelnou sadu znaků a začínají hry s kódováním. Ne vždy je to možné udělat rychle a někdy lze potřebný dokument otevřít po šesti měsících, nebo i později. Lidé, kteří si často vyměňují informace, si sami vytvářejí převodní tabulky. A tak práce na nich odhaluje zajímavý detail: je potřeba je tvořit dvěma směry: „od mého k vašemu“ a naopak. Stroj nemůže provést banální inverzi výpočtů, protože v pravém sloupci je zdroj a v levém - výsledek, ale ne naopak. Pokud by bylo potřeba nějaké použít Speciální symboly v dokumentu musely být nejprve doplněny a poté také partnerovi vysvětleny, co musí udělat, aby se tyto symboly nezměnily v „krakozyabry“. A nezapomínejme, že pro každé kódování jste museli vyvinout nebo implementovat vlastní fonty, což vedlo k vytvoření obrovského množství duplikátů v OS.
Představte si také, že na stránce písem uvidíte 10 stejných Times New Roman s malými poznámkami: pro UTF-8, UTF-16, ANSI, UCS-2. Chápete nyní, že bylo nutné vytvořit univerzální standard?

"Otcové stvořitelé"
Počátky Unicode lze vysledovat až do roku 1987, kdy Joe Becker ze společnosti Xerox spolu s Lee Collinsem a Markem Davisem z Jablko zahájil výzkum praktického vytvoření univerzální znakové sady. V srpnu 1988 zveřejnil Joe Becker návrh 16bitového mezinárodního vícejazyčného kódovacího systému.
O několik měsíců později byla pracovní skupina Unicode rozšířena o Kena Whistlera a Mikea Kernegana z RLG, Glenna Wrighta ze Sun Microsystems a několik dalších, čímž byla dokončena přípravná práce na společném standardu kódování.

obecný popis
Unicode je založen na konceptu znaku. Tato definice je chápána jako abstraktní fenomén, který existuje ve specifické formě písma a je realizován prostřednictvím grafémů (jejich „portrétů“). Každý znak je specifikován v "Unicode" unikátní kód patřící do konkrétního bloku normy. Například grafém B je v anglické i ruské abecedě, ale v Unicode odpovídá 2 různým znakům. Je na ně aplikována transformace, to znamená, že každý z nich je popsán databázovým klíčem, sadou vlastností a celým jménem.
Výhody Unicode
Kódování Unicode se od ostatních svých současníků lišilo velkým množstvím znaků pro „šifrování“ znaků. Faktem je, že jeho předchůdci měli 8 bitů, to znamená, že podporovali 28 znaků, ale nový vývoj měl již 216 postav, což byl obrovský krok vpřed. To umožnilo zakódovat téměř všechny existující a běžné abecedy.
S příchodem „Unicode“ nebylo potřeba používat převodní tabulky: jako jediný standard to jednoduše eliminovalo jejich potřebu. Stejně tak „krakozyabry“ upadly v zapomnění – jediný standard je znemožnil a stejně tak eliminoval nutnost vytvářet duplicitní fonty.
Vývoj Unicode
Pokrok samozřejmě nestojí a od první prezentace uplynulo 25 let. Kódování Unicode si však tvrdošíjně udržuje svou pozici ve světě. V mnoha ohledech se to stalo možným díky tomu, že se to stalo snadno implementovaným a rozšířeným a bylo uznáváno jako vývojáři proprietárního (placeného) a open source softwaru.

Zároveň bychom neměli předpokládat, že dnes máme k dispozici stejné kódování Unicode jako před čtvrt stoletím. Na tento moment jeho verze se změnila na 5.х.х a počet kódovaných znaků se zvýšil na 231. Možnost používat větší zásobu znaků byla opuštěna, aby byla stále zachována podpora Unicode-16 (kódování, kde byl jejich maximální počet omezen na 216). Od svého vzniku až do verze 2.0.0 „Standard Unicode“ téměř zdvojnásobil počet znaků, které obsahuje. Růst příležitostí pokračoval i v následujících letech. Do verze 4.0.0 bylo potřeba zvýšit samotný standard, což se podařilo. Díky tomu získal „Unicode“ podobu, ve které jej známe dnes.

Co dalšího je v Unicode?
Kromě obrovského, neustále rostoucího počtu symbolů má ještě jednu užitečnou funkci. Jde o takzvanou normalizaci. Namísto procházení celého dokumentu znak po znaku a nahrazování příslušných ikon z vyhledávací tabulky se používá některý ze stávajících normalizačních algoritmů. o čem to mluvíme?
Místo plýtvání výpočetními prostředky na pravidelnou kontrolu stejného symbolu, který může být podobný v různých abecedách, se používá speciální algoritmus. Umožňuje vám vyjmout podobné znaky v samostatném sloupci substituční tabulky a odkazovat na ně, spíše než znovu a znovu kontrolovat všechna data.
Byly vyvinuty a implementovány čtyři takové algoritmy. V každém z nich probíhá transformace podle striktně definovaného principu, který se od ostatních liší, proto nelze označit žádný z nich za nejúčinnější. Každý z nich byl vyvinut pro specifické potřeby, byl implementován a úspěšně používán.

Distribuce normy
Za 25 let své historie je kódování Unicode pravděpodobně nejrozšířenější na světě. Programy a webové stránky jsou také přizpůsobeny tomuto standardu. Skutečnost, že Unicode dnes používá více než 60 % internetových zdrojů, může naznačovat šíři aplikace.
Nyní víte, kdy vznikl standard Unicode. Co to je, také víte a budete schopni ocenit plný význam vynálezu vytvořeného skupinou specialistů z Unicode Inc. před více než 25 lety.
Potřebujete hosting nebo doménu? Klikněte zde! Chcete vytvořit internetový obchod? Klikněte zde! (Shopify)Někdy je při psaní příspěvku potřeba znak (znak), který není na klávesnici, v takových situacích vám pomůže unicode tabulka znaků. Dnes budeme uvažovat služba online, ve kterém jsou seskupeny všechny znaky unicode ...
Tabulka znaků Unicode
Pro ty, které zajímá pozadí vzhledu Unicode- zde je odkaz na wikipedii
Označme tedy své zájmy znaky unicode- to je jejich použití v jejich článcích, na jejich stránkách.
Nejprve přejdeme na stránku znaky unicode služby:


Pojďme se trochu podívat na rozhraní této služby. Zcela nahoře je vyhledávací pole, v něm stačí zadat název hledaného prvku, např.: "Šípka" nebo "Elipsa", po zadání klikni na vyhledávání pro výsledek .
Vedle vyhledávání je přepínač jazyka stránky.
Níže je seznam často požadovaných symbolů, možná mezi nimi bude ten, který potřebujete, pokud ano, kliknutím na symbol přejdete na stránku s podrobnými informacemi o něm.
Hlavní část stránky zabírá tabulka znaků Unicode, pro pohodlnější vyhledávání můžete také kliknout na "Řídící znaky" a vybrat skupinu znaků, například: "Řecké znaky", pokud potřebujete vložit řecký znak.
Najděte požadovanou položku v tabulce znaků Unicode
Použijme například vyhledávání a zadáme do něj slovo "Arrow" a stiskneme hledat.

Na stránce s výsledky vyhledávání hledáme symbol, který potřebujeme, a kliknutím na něj přejdeme na stránku detailní informace o něm.
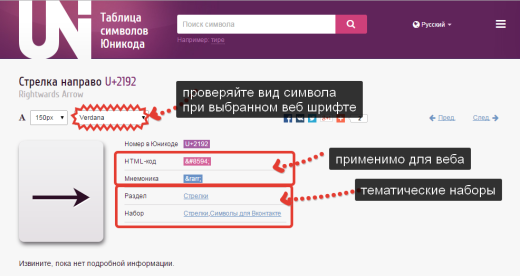
Na stránce Unicode znak zajímá nás jeho HTML kód nebo Mnemotechnický kód, oba lze použít na webové stránce, zkopírujte kód a vložte jej na správné místo v HTML značce, prohlížeč jej interpretuje a zobrazí jako symbol na strana.
Vezměte prosím na vědomí, že na stránce znaků Unicode je k dispozici výběr písma. Vždy si vyzkoušejte, jak se vaše písmo bude zobrazovat pomocí písem Verdana, Arial (a dalších webových písem). ne všechny znaky jsou jimi podporovány.
(kódy od 0 do 127), tzn. jeden bajt kóduje latinská písmena, čísla a speciální znaky. Ruská písmena (cyrilice) jsou reprezentována 16bitovými (dvoubajtovými) kódy:
110XXXX 10XXXXXX,
kde X označuje binární číslice pro umístění znakového kódu v souladu s tabulkou UNICODE.
Unicode (anglicky Unicode) je standard kódování znaků, který umožňuje zastoupení znaků téměř ve všech psaných jazycích. Znaky Unicode jsou zakódovány jako celá čísla bez znaménka. Tato čísla se budou nazývat kódy znaků Unicode nebo jednoduše UNICODE... Unicode má několik forem reprezentace znaků v počítači: UTF-8, UTF-16 (UTF-16BE, UTF-16LE) a UTF-32 (UTF-32BE, UTF-32LE)... (Anglický formát transformace Unicode - UTF).
Zvažte, jak je to zakódováno UTF-8 dopis F... Její UNICODE- 1046 10 nebo 0416 16 nebo 10 000 010110 2. UNICODE v binární podobě je rozdělena na dvě části: pět levých bitů a šest pravých bitů. Levá strana je doplněna na byte se znakem 110 dvoubajtový kód UTF-8: 110 10000. Dva bity jsou přiřazeny pravé straně 10 znak pokračování vícebajtového kódu: 10 010110. Kód koncového písmene F proti UTF-8 vypadá takto:
110
10000 10
010110 2
nebo D0 96 16
Ruské písmeno je tedy zakódováno dvakrát: nejprve do 11 bitů UNICODE a poté do 16bitového UTF-8.
V tabulce níže kromě kódů UNICODE a UTF-8 v hexadecimálním zápisu jsou uvedeny kódy UTF-8 v desítkovém zápisu a pro srovnání kódy azbuky v kódování CP-1251, jinak nazývaný windovs-1251.
| Symbol | UNICODE | UTF-8 | CP-1251 | ||
|---|---|---|---|---|---|
| Hex | Deset | Hex | Deset | ||
| A | 0410 | 1040 | D090 | 208 144 | 192 |
| B | 0411 | 1041 | D091 | 208 145 | 193 |
| PROTI | 0412 | 1042 | D092 | 208 146 | 194 |
| G | 0413 | 1043 | D093 | 208 147 | 195 |
| D | 0414 | 1044 | D094 | 208 148 | 196 |
| E | 0415 | 1045 | D095 | 208 149 | 197 |
| F | 0416 | 1046 | D096 | 208 150 | 198 |
| Z | 0417 | 1047 | D097 | 208 151 | 199 |
| A | 0418 | 1048 | D098 | 208 152 | 200 |
| Th | 0419 | 1049 | D099 | 208 153 | 201 |
| NA | 041A | 1050 | D09A | 208 154 | 202 |
| L | 041B | 1051 | D09B | 208 155 | 203 |
| M | 041C | 1052 | D09C | 208 156 | 204 |
| N | 041D | 1053 | D09D | 208 157 | 205 |
| Ó | 041E | 1054 | D09E | 208 158 | 206 |
| NS | 041F | 1055 | D09F | 208 159 | 207 |
| R | 0420 | 1056 | D0A0 | 208 160 | 208 |
| S | 0421 | 1057 | D0A1 | 208 161 | 209 |
| T | 0422 | 1058 | D0A2 | 208 162 | 210 |
| Mít | 0423 | 1059 | D0A3 | 208 163 | 211 |
| F | 0424 | 1060 | D0A4 | 208 164 | 212 |
| NS | 0425 | 1061 | D0A5 | 208 165 | 213 |
| C | 0426 | 1062 | D0A6 | 208 166 | 214 |
| H | 0427 | 1063 | D0A7 | 208 167 | 215 |
| NS | 0428 | 1064 | D0A8 | 208 168 | 216 |
| SCH | 0429 | 1065 | D0A9 | 208 169 | 217 |
| B | 042A | 1066 | D0AA | 208 170 | 218 |
| NS | 042B | 1067 | D0AB | 208 171 | 219 |
| B | 042C | 1068 | D0AC | 208 172 | 220 |
| NS | 042D | 1069 | D0AD | 208 173 | 221 |
| NS | 042E | 1070 | D0AE | 208 174 | 222 |
| JSEM | 042F | 1071 | D0AF | 208 175 | 223 |
| A | 0430 | 1072 | D0B0 | 208 176 | 224 |
| b | 0431 | 1073 | D0B1 | 208 177 | 225 |
| proti | 0432 | 1074 | D0B2 | 208 178 | 226 |
| G | 0433 | 1075 | D0B3 | 208 179 | 227 |
| d | 0434 | 1076 | D0B4 | 208 180 | 228 |
| E | 0435 | 1077 | D0B5 | 208 181 | 229 |
| F | 0436 | 1078 | D0B6 | 208 182 | 230 |
| s | 0437 | 1079 | D0B7 | 208 183 | 231 |
| a | 0438 | 1080 | D0B8 | 208 184 | 232 |
| čt | 0439 | 1081 | D0B9 | 208 185 | 233 |
| Na | 043A | 1082 | D0BA | 208 186 | 234 |
| l | 043B | 1083 | D0BB | 208 187 | 235 |
| m | 043C | 1084 | D0BC | 208 188 | 236 |
| n | 043D | 1085 | D0BD | 208 189 | 237 |
| Ó | 043E | 1086 | D0BE | 208 190 | 238 |
| NS | 043F | 1087 | D0BF | 208 191 | 239 |
| R | 0440 | 1088 | D180 | 209 128 | 240 |
| s | 0441 | 1089 | D181 | 209 129 | 241 |
| T | 0442 | 1090 | D182 | 209 130 | 242 |
| na | 0443 | 1091 | D183 | 209 131 | 243 |
| F | 0444 | 1092 | D184 | 209 132 | 244 |
| NS | 0445 | 1093 | D185 | 209 133 | 245 |
| C | 0446 | 1094 | D186 | 209 134 | 246 |
| h | 0447 | 1095 | D187 | 209 135 | 247 |
| NS | 0448 | 1096 | D188 | 209 136 | 248 |
| SCH | 0449 | 1097 | D189 | 209 137 | 249 |
| b | 044A | 1098 | D18A | 209 138 | 250 |
| NS | 044B | 1099 | D18B | 209 139 | 251 |
| b | 044C | 1100 | D18C | 209 140 | 252 |
| NS | 044D | 1101 | D18D | 209 141 | 253 |
| NS | 044E | 1102 | D18E | 209 142 | 254 |
| jsem | 044F | 1103 | D18F | 209 143 | 255 |
| Symboly mimo obecné pravidlo | |||||
| jo | 0401 | 1025 | D001 | 208 101 | 168 |
| E | 0451 | 1025 | D191 | 209 145 | 184 |
Někdy potřebujete přidat ikonu do svého návrhu, ale nechcete vkládat další obrázky nebo celé písmo ikony, jako je Font Awesome? Pak pro vás máme dobrou zprávu – ve vašem prohlížeči je již rozsáhlá knihovna dostupných ikon a symbolů. Jmenuje se Unicode a je to standard, který přiřazuje jedinečné identifikátory pro stále rostoucí počet (aktuálně přes 110 000) symbolů a ikon.
To však neznamená, že máte na výběr ze stovek tisíc ikon. Záleží na prohlížeči, který je vykresluje, a používá k tomu fonty, které jsou nainstalovány v systému. V tomto článku jsme sestavili řadu znakových sad, které jsou dostupné v systémech Windows, Linux, OS X, Android a IOS. Dnes je můžete použít ve svých návrzích!
Tip: který vysvětluje vše, co je třeba vědět o kódování a Unicode, které doporučujeme přečíst každému vývojáři softwaru.
Jak používat tyto ikony
Ikony zobrazené v tabulkách níže jsou běžné symboly, které můžete zkopírovat a vložit, jako by to byla písmena abecedy. Pokud se však kódování používá k uložení souborů HTML / CSS ne UTF-8 nebudou zobrazeny. Proto jsme zavedli kód HTML escape, který bude vždy fungovat. Zde je to, co musíte udělat, abyste tyto ikony mohli používat.:
- Najděte ikonu, která se vám líbí. Poskytli jsme malé i velké náhledy.
- Zkopírujte kód.
- Vložte jej do HTML jako prostý text. V CSS je můžete použít jako hodnotu vlastnosti obsah... V JS, PHP a dalších programovacích jazycích je můžete použít jako prostý text v řetězcích.
- Ikony si můžete přizpůsobit nastavením velikosti písma, barvy, textu a stínů stejně jako normální text.
ikony
| název | Náhled | Kód | |
|---|---|---|---|
| smajlík | ☺ | ☺ | ☺ |
| Varovná cedule | ⚠ | ⚠ | ⚠ |
| Horké prameny | ♨ | ♨ | ♨ |
| Invalidní vozík | ♿ | ♿ | ♿ |
| Recyklovat | ♻ | ♻ | ♻ |
| 8-Kulička | ➑ | ➑ | ➑ |
| Vysokého napětí | ⚡ | ⚡ | ⚡ |
| Bílá hvězda | ☆ | ☆ | ☆ |
| Černá hvězda | ★ | ★ | ★ |
| Bílé srdce | ♡ | ♡ | ♡ |
| Černé srdce | ❤ | ❤ | ❤ |
| Káva | ☕ | ☕ | ☕ |
| Letoun | ✈ | ✈ | ✈ |
| Přesýpací hodiny | ⌛ | ⌛ | ⌛ |
| Hodiny | ⌚ | ⌚ | ⌚ |
| Černé nůžky | ✂ | ✂ | ✂ |
| Bílé nůžky | ✄ | ✄ | ✄ |
| Koruna | ♕ | ♕ | ♕ |
| Kotva | ⚓ | ⚓ | ⚓ |
| Přejít | ✝ | ✝ | ✝ |
| Černo-bílý kruh | ◑ | ◑ | ◑ |
| Osm poznámek | ♪ | ♪ | ♪ |
| Vyzářené osminové tóny | ♫ | ♫ | ♫ |
| Hvězdička se čtyřmi balónky | ✣ | ✣ | ✣ |
| Zakroužkovaná bílá hvězda | ✪ | ✪ | ✪ |
| Bílá hvězda | ✰ | ✰ | ✰ |
| Bílá čtyřcípá hvězda | ✧ | ✧ | ✧ |
| Černá čtyřcípá hvězda | ✦ | ✦ | ✦ |
| Kontrola volebních uren | ☑ | ☑ | ☑ |
| Zkontrolujte značku | ✔ | ✔ | ✔ |
| Křížová značka | ✘ | ✘ | ✘ |
| Tužka | ✎ | ✎ | ✎ |
| Psací ruka | ✍ | ✍ | ✍ |
| ženský | ♀ | ♀ | ♀ |
| mužský | ♂ | ♂ | ♂ |
| Černý telefon | ☎ | ☎ | ☎ |
| Bílý telefon | ☏ | ☏ | ☏ |
| Obálka | ✉ | ✉ | ✉ |
| Umístění telefonu | ✆ | ✆ | ✆ |
Unicode šipky
| název | Náhled | Kód | |
|---|---|---|---|
| Šipka doleva | ← | ← | ← |
| Šipka doprava | → | → | → |
| Šipka nahoru | |||
| Šipka dolů | ↓ | ↓ | ↓ |
| Šipka vlevo vpravo | ↔ | ↔ | ↔ |
| Šipka nahoru dolů | ↕ | ↕ | ↕ |
| šipky doprava a doleva | ⇄ | ⇄ | ⇄ |
| Šipky nahoru a dolů | ⇅ | ⇅ | ⇅ |
| Šipka dolů-vlevo 90 stupňů | ↲ | ↲ | ↲ |
| Šipka dolů-vpravo 90 stupňů | ↳ | ↳ | ↳ |
| Šipka nahoru-vlevo 90 stupňů | ↰ | ↰ | ↰ |
| Šipka nahoru-vpravo 90 stupňů | ↱ | ↱ | ↱ |
| Severozápadní šipka Do Rohu | ⇱ | ⇱ | ⇱ |
| South East Arrow To Corner | ⇲ | ⇲ | ⇲ |
| Šipka doleva na lištu | ⇤ | ⇤ | ⇤ |
| Šipka doprava do pruhu | ⇥ | ⇥ | ⇥ |
| Půlkruhová šipka proti směru hodinových ručiček | ↶ | ↶ | ↶ |
| Ve směru hodinových ručiček půlkruhová šipka | ↷ | ↷ | ↷ |
| Kruhová šipka proti směru hodinových ručiček | ↺ | ↺ | ↺ |
| Šipka kruhu ve směru hodinových ručiček | ↻ | ↻ | ↻ |
| Širokohlavá šipka vpravo | ➔ | ➔ | ➔ |
| Šipka dolů klikatá | ↯ | ↯ | ↯ |
| Severozápadní šipka | ↖ | ↖ | ↖ |
| Těžká jihovýchodní šipka | ➘ | ➘ | ➘ |
| Těžká šipka doprava | ➙ | ➙ | ➙ |
| Těžká severovýchodní šipka | ➚ | ➚ | ➚ |
| Přerušovaná šipka doprava | ➟ | ➟ | ➟ |
| Tečkovaná šipka doleva | ⇠ | ⇠ | ⇠ |
| Černá šipka vpravo | ➤ | ➤ | ➤ |
| Bílá šipka doleva | ⇦ | ⇦ | ⇦ |
| Bílá šipka doprava | ⇨ | ⇨ | ⇨ |
| Levý úhel uvozovky | « | « | « |
| Pravoúhlá uvozovka | » | » | » |
| Pravý černý ukazatel | |||
| Levý černý ukazatel | ◀ | ◀ | ◀ |
| Nahoru černý ukazatel | ▲ | ▲ | ▲ |
| Dolů černý ukazatel | ▼ | ▼ | ▼ |
| Pravý bílý ukazatel | ▷ | ▷ | ▷ |
| Levý bílý ukazatel | ◁ | ◁ | ◁ |
| Nahoru bílý ukazatel | △ | △ | △ |
| Dolů bílý ukazatel | ▽ | ▽ | ▽ |
| Luk šíp | ➴ | ➴ | ➴ |
Speciální znaky v unicode
Unicode měna
Ikony počasí
| název | Náhled | Kód | |
|---|---|---|---|
| Stupeň | ° | ° | ° |
| Malé slunce | ☀ | ☀ | ☀ |
| Velké slunce | ☼ | ☼ | ☼ |
| Mrak | ☁ | ☁ | ☁ |
| Deštník | ☔ | ☔ | ☔ |
| Sněhová vločka 1 | ❆ | ❆ | ❆ |
| Sněhová vločka 2 | ❅ | ❅ | ❅ |
| Sněhová vločka 3 | ❄ | ❄ | ❄ |
Unicode ukazatele
| název | Náhled | Kód | |
|---|---|---|---|
| Ukazatel vlevo černá | ☚ | ☚ | ☚ |
| Ukazatel vpravo černá | ☛ | ☛ | ☛ |
| Ukazatel vlevo Bílá | ☜ | ☜ | ☜ |
| Ukazatel Nahoru Bílá | ☝ | ☝ | ☝ |
| Ukazatel vpravo Bílá | ☞ | ☞ | ☞ |
| Ukazatel Dolů Bílá | ☟ | ☟ | ☟ |
Znamení zvěrokruhu v unicode
| název | Náhled | Kód | |
|---|---|---|---|
| Beran | ♈ | ♈ | ♈ |
| Býk | ♉ | ♉ | ♉ |
| Dvojčata | ♊ | ♊ | ♊ |
| Rakovina | ♋ | ♋ | ♋ |
| Lev | ♌ | ♌ | ♌ |
| Panna | ♍ | ♍ | ♍ |
| váhy | ♎ | ♎ | ♎ |
| Štír | ♏ | ♏ | ♏ |
| Střelec | ♐ | ♐ | ♐ |
| Kozoroh | ♑ | ♑ | ♑ |
| Vodnář | ♒ | ♒ | ♒ |
| Ryby | ♓ | ♓ | ♓ |
Unicode symboly karet
| název | Náhled | Kód | |
|---|---|---|---|
| Černé kluby | ♠ | ♠ | ♠ |
| Srdce černé | ♥ | ♥ | ♥ |
| Diamanty černé | ♦ | ♦ | ♦ |
| Piky černé | ♣ | ♣ | ♣ |
| Bílé kluby | ♤ | ♤ | ♤ |
| Srdce bílé | ♡ | ♡ | ♡ |
| Diamanty bílé | ♢ | ♢ | ♢ |
| Piky bílé | ♧ | ♧ | ♧ |
Šachové figurky v unicode
| název | Náhled | Kód | |
|---|---|---|---|
| Král bílý | ♔ | ♔ | ♔ |
| Královna bílá | ♕ | ♕ | ♕ |
| Věž bílý | ♖ | ♖ | ♖ |
| biskup Bílý | ♗ | ♗ | ♗ |
| Rytíř bílý | ♘ | ♘ | ♘ |
| Pěšec bílý | ♙ | ♙ | ♙ |
| Král černý | ♚ | ♚ | ♚ |
| Královna černá | ♛ | ♛ | ♛ |
| Věž černá | ♜ | ♜ | ♜ |
| biskup Černý | ♝ | ♝ | ♝ |
| Rytíř černý | ♞ | ♞ | ♞ |
| Pěšec černý | ♟ | ♟ | ♟ |
Hra v kostky
| název | Náhled | Kód | |
|---|---|---|---|
| Hod kostkou jedna | ⚀ | ⚀ | ⚀ |
| Hod kostkou dva | ⚁ | ⚁ | ⚁ |
| Hod kostkou tři | ⚂ | ⚂ | ⚂ |
| Hod kostkou čtyři | ⚃ | ⚃ | ⚃ |
| Hod kostkou pět | ⚄ | ⚄ | ⚄ |
| Hod kostkou šest | ⚅ | ⚅ | ⚅ |
Unicode matematické symboly
| název | Náhled | Kód | |
|---|---|---|---|
| Nekonečno | ∞ | ∞ | ∞ |
| Plus mínus | ± | ± | ± |
| Menší než nebo rovno | ≤ | ≤ | ≤ |
| Více než nebo rovno | ≥ | ≥ | ≥ |
| Nerovná se | ≠ | ≠ | ≠ |
| Divize | ÷ | ÷ | ÷ |
| Násobení x | × | × | × |
| Těžké násobení x | ✖ | ✖ | ✖ |
| Horní index jedna | ¹ | ¹ | ¹ |
| Horní index dva | ² | ² | ² |
| Horní index tři | ³ | ³ | ³ |
| Zakroužkované plus | ⊕ | ⊕ | ⊕ |
| Násobení v kroužku | ⊗ | ⊗ | ⊗ |
| Logické AND | ∧ | ∧ | ∧ |
| Logické NEBO | ∨ | ∨ | ∨ |
| Delta | ∆ | ∆ | ∆ |
| Koláč | ∏ | ∏ | ∏ |
| Sigma (SUM) | ∑ | ∑ | ∑ |
| Omega | Ω | Ω | Ω |
| Prázdná sada | ∅ | ∅ | ∅ |
| Úhel | ∠ | ∠ | ∠ |
| Paralelní | ∥ | ∥ | ∥ |
| Kolmý | ⊥ | ⊥ | ⊥ |
| Téměř se rovná | ≈ | ≈ | ≈ |
| Trojúhelník | △ | △ | △ |
| Kruh | ○ | ○ | ○ |
| Náměstí | □ | □ | □ |
Zlomky
| název | Náhled | Kód | |
|---|---|---|---|
| Jedna čtvrtina (1/4) | ¼ | ¼ | ¼ |
| Jedna polovina (1/2) | ½ | ½ | ½ |
| Tři čtvrtiny (3/4) | ¾ | ¾ | ¾ |
| Jedna třetina (1/3) | ⅓ | ⅓ | ⅓ |
| Dvě třetiny (2/3) | ⅔ | ⅔ | ⅔ |
| Jedna osm (1/8) | ⅛ | ⅛ | ⅛ |
| Tři osmičky (3/8) | ⅜ | ⅜ | ⅜ |
| Five Eights (5/8) | ⅝ | ⅝ | ⅝ |
| Sedm osmiček (7/8) | ⅞ | ⅞ | ⅞ |
Římské číslice v unicode
| název | Náhled | Kód | |
|---|---|---|---|
| Římské číslo jedna | Ⅰ | Ⅰ | Ⅰ |
| Římské číslo dvě | Ⅱ | Ⅱ | Ⅱ |
| Římské číslo tři | Ⅲ | Ⅲ | Ⅲ |
| Římská číslice čtyři | Ⅳ | Ⅳ | Ⅳ |
| Římská číslice pět | Ⅴ | Ⅴ | Ⅴ |
| Římské číslo šest | Ⅵ | Ⅵ | Ⅵ |
| Římské číslo sedm | Ⅶ | Ⅶ | Ⅶ |
| Římská číslice osm | Ⅷ | Ⅷ | Ⅷ |
| Římská číslice devět | Ⅸ | Ⅸ | Ⅸ |
| Římské číslo deset | Ⅹ | Ⅹ | Ⅹ |
| Římské číslo jedenáct | Ⅺ | Ⅺ | Ⅺ |
| Římská číslice dvanáct | Ⅻ | Ⅻ | Ⅻ |
Existují určité rozdíly ve vykreslování těchto symbolů v různých operační systémy... To je způsobeno různými rodinami písem, které se používají. Kromě toho systémy iOS a Android nahrazují některé znaky Unicode emotikony, takže nezapomeňte zkontrolovat přidané znaky, abyste se ujistili, že tomu tak není a ikony se zobrazují podle očekávání.
Prvky kódového prostoru, které představují nezáporná celá čísla. Rodina kódování definuje strojovou reprezentaci sekvence kódů UCS.
Kódy Unicode jsou rozděleny do několika oblastí. Oblast s kódy U + 0000 až U + 007F obsahuje znaky ASCII s odpovídajícími kódy. Dále jsou to oblasti znaků různých písem, interpunkčních znamének a technických symbolů. Některé z kódů jsou vyhrazeny pro budoucí použití. Pod znaky azbuky jsou přiděleny oblasti znaků s kódy od U + 0400 do U + 052F, od U + 2DE0 do U + 2DFF, od U + A640 do U + A69F (viz azbuka v Unicode).
Předpoklady pro vytvoření a rozvoj Unicode
Protože v řadě počítačových systémů (například Windows NT) se již jako výchozí kódování používaly pevné 16bitové znaky, bylo rozhodnuto zakódovat všechny nejdůležitější znaky pouze v rámci prvních 65 536 pozic (tzv. anglických. základní vícejazyčná rovina, BMP). Zbytek místa je použit pro "doplňkové znaky" (angl. doplňkové znaky): systémy psaní zaniklých jazyků nebo velmi zřídka používané čínské znaky, matematické a hudební symboly.
Pro kompatibilitu se starými 16bitovými systémy byl vynalezen systém UTF-16, kde prvních 65 536 pozic, s výjimkou pozic z intervalu U + D800 ... U + DFFF, je zobrazeno přímo jako 16bitová čísla, a zbytek je reprezentován jako "náhradní páry" (první prvek z páru z oblasti U + D800… U + DBFF, druhý prvek z páru z oblasti U + DC00… U + DFFF). Pro náhradní páry byla použita část kódového prostoru (2048 pozic) dříve vyhrazená pro „znaky pro soukromé použití“.
Protože UTF-16 může zobrazit pouze 2 20 + 2 16 −2048 (1 112 064) znaků, bylo toto číslo zvoleno jako konečná hodnota pro kódový prostor Unicode.
Přestože byla oblast kódu Unicode rozšířena za 2-16 již ve verzi 2.0, první znaky v oblasti „top“ byly umístěny až ve verzi 3.1.
Role tohoto kódování ve webovém sektoru neustále roste, na začátku roku 2010 byl podíl webů využívajících Unicode cca 50 %.
Unicode verze
Vzhledem k tomu, že se tabulka znaků Unicode mění a doplňuje a jsou vydávány nové verze tohoto systému – a tato práce pokračuje, protože původní systém Unicode zahrnoval pouze rovinu 0 – dvoubajtové kódy – jsou také vydávány nové dokumenty ISO. Systém Unicode existuje celkem v následujících verzích:
- 1.1 (vyhovuje normě ISO / IEC 10646-1: 1993), 1991-1995.
- 2.0, 2.1 (stejná norma ISO / IEC 10646-1: 1993 plus dodatky: "Dodatky" 1 až 7 a "Technické opravy" 1 a 2), norma z roku 1996.
- 3.0 (ISO / IEC 10646-1: norma 2000) norma 2000.
- 3.1 (normy ISO / IEC 10646-1: 2000 a ISO / IEC 10646-2: 2001) z roku 2001.
- 3.2 norma 2002.
- 4.0, standard 2003.
- 4.01, standard 2004.
- 4.1, standard 2005.
- 5.0, standard 2006.
- 5.1, standard 2008.
- 5.2, standard 2009.
- 6.0, standard 2010.
- 6.1, standard 2012.
- 6.2, standard 2012.
Kódový prostor
Ačkoli formy zápisu UTF-8 a UTF-32 umožňují zakódovat až 2 331 (2 147 483 648) kódových bodů, bylo rozhodnuto použít pouze 1 112 064 pro kompatibilitu s UTF-16. I to je však více než dost – dnes se (ve verzi 6.0) používá o něco méně než 110 000 kódových bodů (109 242 grafických a 273 dalších symbolů).
Kódový prostor je rozdělen na 17 letadla 2 16 (65536) znaků každý. Říká se nulová rovina základní, obsahuje symboly nejběžnějších skriptů. První rovina se používá hlavně pro historická písma, druhá - pro zřídka používané znaky CJK, třetí je vyhrazena pro archaické čínské znaky. Letadla 15 a 16 jsou vyhrazena pro soukromé použití.
K označení Unicode znaky zápis tvaru „U + xxxx"(Pro kódy 0 ... FFFF), nebo" U + xxxxx"(Pro kódy 10000 ... FFFFF), nebo" U + xxxxxx"(Pro kódy 100000 ... 10FFFF), kde xxx- hexadecimální číslice. Například znak „i“ (U + 044F) má kód 044F = 1103.
Systém kódování
Univerzální kódovací systém (Unicode) je soubor grafických symbolů a způsob jejich kódování pro počítačové zpracování textových dat.
Grafické symboly jsou symboly, které mají viditelný obrázek. Grafické znaky jsou protikladem k ovládacím a formátovacím znakům.
Grafické symboly zahrnují následující skupiny:
- písmena obsažená alespoň v jedné z podporovaných abeced;
- čísla;
- interpunkční znaménka;
- speciální znaky (matematické, technické, ideogramy atd.);
- oddělovače.
Unicode je systém pro lineární reprezentaci textu. Znaky s dalšími horními nebo dolními indexy mohou být reprezentovány jako sekvence kódů sestavené podle určitých pravidel (složený znak) nebo jako jeden znak (monolitická verze, předem složený znak).
Úprava postav
Znázornění znaku "Y" (U + 0419) ve formě základního znaku "I" (U + 0418) a modifikačního znaku "" (U + 0306)
Grafické znaky se v Unicode dělí na rozšířené a nerozšířené (bez šířky). Nerozšířené znaky při zobrazení nezabírají místo v řádku. Patří sem zejména diakritická znaménka a další diakritická znaménka. Rozšířené i neprodloužené znaky mají své vlastní kódy. Rozšířené symboly se jinak nazývají základní (angl. základní znaky), a nerozšířené - upravující (angl. kombinování znaků); a tito se nemohou setkat nezávisle. Například znak "á" může být reprezentován jako posloupnost základního znaku "a" (U + 0061) a modifikačního znaku " ́" (U + 0301), nebo jako monolitický znak "á" (U + 00C1).
Speciálním typem modifikujících postav jsou selektory stylu obličeje (angl. selektory variací). Vztahují se pouze na ty symboly, pro které jsou takové varianty definovány. Ve verzi 5.0 jsou pro sérii definovány možnosti stylu matematické symboly, za symboly tradiční mongolské abecedy a za symboly mongolského čtvercového písma.
Normalizační formy
Protože mohou být zastoupeny stejné symboly různé kódy, což někdy komplikuje zpracování, existují normalizační procesy určené k uvedení textu do určité standardní podoby.
Standard Unicode definuje 4 formy normalizace textu:
- Normalizační forma D (NFD) - Kanonický rozklad. V procesu převodu textu do této formy jsou všechny složené znaky rekurzivně nahrazeny několika složenými v souladu s rozkladovými tabulkami.
- Normalizační forma C (NFC) je kanonický rozklad následovaný kanonickým složením. Nejprve je text redukován do tvaru D, poté je provedena kanonická kompozice - text je zpracován od začátku do konce a jsou dodržována následující pravidla:
- Symbol S je počáteční pokud má třídu modifikace nulu ve znakové základně Unicode.
- V jakékoli posloupnosti znaků začínajících počátečním znakem S je znak C blokován od S právě tehdy, když je mezi S a C jakýkoli znak B, který je buď počátečním znakem nebo má stejnou nebo vyšší třídu modifikace než C. Toto pravidlo platí pouze pro řetězce, které prošly kanonickým rozkladem.
- Hlavní Složený je znak, který má kanonickou dekompozici ve znakové základně Unicode (nebo kanonickou dekompozici pro Hangul a není zahrnut v seznamu výjimek).
- Znak X lze primárně zarovnat se znakem Y tehdy a pouze tehdy, pokud existuje primární složený Z kanonicky ekvivalentní sekvenci.
- Pokud další znak C není blokován posledním nalezeným počátečním základním znakem L a lze jej s ním úspěšně zarovnat, pak je L nahrazeno složeným L-C a C je odstraněno.
- Normalizační forma KD (NFKD) - Compatible Decomposition. Při obsazení do této formy jsou všechny složené znaky nahrazeny pomocí jak kanonických dekompozičních map Unicode, tak kompatibilních dekompozičních map, načež je výsledek umístěn v kanonickém pořadí.
- Normalizační forma KC (NFKC) - Kompatibilní rozklad následovaný kanonický složení.
Termíny "složení" a "rozklad" znamenají v tomto pořadí spojení nebo rozklad symbolů na jejich součásti.
Příklady
| Zdrojový text | NFD | NFC | NFKD | NFKC |
|---|---|---|---|---|
| Français | frank \ u0327ais | Fran \ xe7ais | frank \ u0327ais | Fran \ xe7ais |
| A, E, Y | \ u0410, \ u0401, \ u0419 | \ u0410, \ u0415 \ u0308, \ u0418 \ u0306 | \ u0410, \ u0401, \ u0419 | |
| が | \ u304b \ u3099 | \ u304c | \ u304b \ u3099 | \ u304c |
| Jindřich iv | Jindřich iv | Jindřich iv | Jindřich iv | Jindřich iv |
| Henry Ⅳ | Henry \ u2163 | Henry \ u2163 | Jindřich iv | Jindřich iv |
Obousměrné písmeno
Standard Unicode podporuje jazyky psaní se směrem zleva doprava (angl. zleva doprava, LTR), a s psaním zprava doleva (angl. zprava doleva, RTL) - například arabská a hebrejská písmena. V obou případech jsou postavy uloženy v „přirozeném“ pořadí; jejich zobrazení s přihlédnutím k požadovanému směru písmene zajišťuje aplikace.
Unicode navíc podporuje kombinované texty, které kombinují fragmenty s různými směry písmene. Tato funkce se nazývá obousměrnost(angl. obousměrný text, BiDi). Některé zjednodušené textové procesory (například v mobily) může podporovat Unicode, ale ne obousměrnou podporu. Všechny znaky Unicode jsou rozděleny do několika kategorií: psané zleva doprava, psané zprava doleva a psané v libovolném směru. Symboly posledně jmenované kategorie (hlavně interpunkční znaménka) se při zobrazení orientují ve směru okolního textu.
Doporučené symboly
Unicode zahrnuje prakticky všechny moderní skripty, včetně:
jiný.
Pro akademické účely bylo přidáno mnoho historických písem, včetně: run, starověké řečtiny, egyptských hieroglyfů, klínového písma, mayského písma, etruské abecedy.
Unicode poskytuje širokou škálu matematických a hudebních symbolů a piktogramů.
Unicode však zásadně nezahrnuje loga společností a produktů, i když je lze nalézt ve fontech (například logo Apple v kódování MacRoman (0xF0) nebo logo Windows ve fontu Wingdings (0xFF)). V písmech Unicode musí být loga umístěna pouze v oblasti vlastních znaků.
ISO / IEC 10646
Unicode Consortium úzce spolupracuje s pracovní skupina ISO / IEC / JTC1 / SC2 / WG2, která vyvíjí mezinárodní standard 10646 (ISO / IEC 10646). Synchronizace je zavedena mezi normou Unicode a ISO / IEC 10646, ačkoli každá norma používá svou vlastní terminologii a systém dokumentace.
Spolupráce Unicode Consortium s Mezinárodní organizací pro standardizaci (angl. Mezinárodní organizace pro normalizaci, ISO ) začala v roce 1991. V roce 1993 vydala ISO normu DIS 10646.1. Pro synchronizaci s ním Konsorcium schválilo verzi 1.1 standardu Unicode, která byla doplněna o další znaky z DIS 10646.1. V důsledku toho jsou hodnoty kódovaných znaků v Unicode 1.1 a DIS 10646.1 naprosto stejné.
Do budoucna spolupráce obou organizací pokračovala. V roce 2000 Standard Unicode 3.0 byla synchronizována s ISO / IEC 10646-1: 2000. Nadcházející třetí verze ISO / IEC 10646 bude synchronizována s Unicode 4.0. Možná budou tyto specifikace dokonce zveřejněny jako jednotný standard.
Podobně jako formáty UTF-16 a UTF-32 ve standardu Unicode má standard ISO / IEC 10646 také dvě hlavní formy kódování znaků: UCS-2 (2 bajty na znak, podobně jako UTF-16) a UCS-4 (4 bajty na znak, podobně jako UTF-32). UCS znamená univerzální víceoktet(multibajt) kódovaná znaková sada(angl. univerzální víceoktetová kódovaná znaková sada ). UCS-2 lze považovat za podmnožinu UTF-16 (UTF-16 bez náhradních párů) a UCS-4 je synonymem pro UTF-32.
Prezentační metody
Unicode má několik forem reprezentace (eng. Transformační formát Unicode, UTF ): UTF-8, UTF-16 (UTF-16BE, UTF-16LE) a UTF-32 (UTF-32BE, UTF-32LE). Forma reprezentace UTF-7 byla vyvinuta také pro přenos přes sedmibitové kanály, ale kvůli nekompatibilitě s ASCII nebyla rozšířena a nebyla zahrnuta do standardu. 1. dubna 2005 byla navržena dvě vtipná podání: UTF-9 a UTF-18 (RFC 4042).
Unicode UTF-8: 0x00000000 - 0x0000007F: 0xxxxxxx 0x00000080 - 0x000007FF: 110xxxxx 10xxxxxx 0x00000800 - 0x0000FFFF: 1110xxxx 10xxxxxx 10xxxxxx 0x00010000 - 0x001FFFFF: 11110xxx 10xxxxxx 10xxxxxx 10xxxx
Teoreticky možné, ale také nezahrnuté ve standardu:
0x00200000 - 0x03FFFFFF: 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 0x04000000 - 0x7FFxx1x1x0x0x1011x10x0x1x1x1x0x
Ačkoli UTF-8 umožňuje zadat stejný znak několika způsoby, správný je pouze ten nejkratší. Zbytek formulářů by měl být z bezpečnostních důvodů odmítnut.
Pořadí bajtů
V datovém toku UTF-16 může být horní bajt zapsán buď před nízkým (ang. UTF-16 big-endian), nebo po mladším (angl. UTF-16 little-endian). Podobně existují dvě možnosti pro čtyřbajtové kódování - UTF-32BE a UTF-32LE.
Chcete-li definovat formát reprezentace Unicode na začátku textový soubor píše se podpis - znak U + FEFF (nezalomitelná mezera s nulovou šířkou), také tzv značka pořadí bajtů(angl. značka objednávky bajtů, kusovník ). To umožňuje rozlišovat mezi UTF-16LE a UTF-16BE, protože znak U + FFFE neexistuje. Někdy se také používá k označení formátu UTF-8, i když pojem pořadí bajtů se na tento formát nevztahuje. Soubory, které se řídí touto konvencí, začínají těmito bajtovými sekvencemi:
UTF-8 EF BB BF UTF-16BE FE FF UTF-16LE FF FE UTF-32BE 00 00 FE FF UTF-32LE FF FE 00 00
Bohužel tato metoda spolehlivě nerozlišuje mezi UTF-16LE a UTF-32LE, protože znak U + 0000 je povolen Unicode (ačkoli skutečné texty jím začínají jen zřídka).
Soubory v kódování UTF-16 a UTF-32, které neobsahují kusovník, musí být v pořadí bajtů big-endian (unicode.org).
Unicode a tradiční kódování
Zavedení Unicode změnilo přístup k tradičnímu 8bitovému kódování. Pokud dříve bylo kódování určeno písmem, nyní je určeno korespondenční tabulkou mezi tímto kódováním a Unicode. Ve skutečnosti se 8bitová kódování stala reprezentací podmnožiny Unicode. Díky tomu bylo mnohem snazší vytvářet programy, které musí pracovat s mnoha různými kódováními: nyní, abyste přidali podporu pro jedno další kódování, stačí přidat další vyhledávací tabulku Unicode.
Mnoho datových formátů navíc umožňuje vložení libovolných znaků Unicode, i když je dokument napsán ve starém 8bitovém kódování. Můžete například použít kódy ampersand v HTML.
Implementace
Většina moderních operačních systémů poskytuje určitý stupeň podpory Unicode.
V operačních systémech řady Windows NT se dvoubajtové kódování UTF-16LE používá pro interní reprezentaci názvů souborů a dalších systémových řetězců. Systémová volání, která přebírají parametry řetězce, jsou k dispozici v jednobajtových a dvoubajtových variantách. Další podrobnosti naleznete v článku
 Odnoklassniki: Registrace a vytvoření profilu
Odnoklassniki: Registrace a vytvoření profilu E je. E (funkce E). Výrazy z hlediska goniometrických funkcí
E je. E (funkce E). Výrazy z hlediska goniometrických funkcí Sociální sítě Ruska Nyní v sociálních sítích
Sociální sítě Ruska Nyní v sociálních sítích