Kodowanie informacji tekstowych. Kodowanie znaków - PIE wiki
Standard został zaproponowany w 1991 roku przez Unicode Consortium, Unicode Inc., organizację non-profit. Zastosowanie tego standardu umożliwia zakodowanie bardzo dużej liczby znaków z różnych skryptów: znaki chińskie, znaki matematyczne, litery alfabetu greckiego, alfabetu łacińskiego i cyrylicy mogą współistnieć w dokumentach Unicode, dzięki czemu przełączanie stron kodowych staje się zbędne.
Standard składa się z dwóch głównych sekcji: uniwersalnego zestawu znaków (UCS) i formatu transformacji Unicode (UTF). Uniwersalny zestaw znaków definiuje korespondencję jeden do jednego znaków z kodami - elementy przestrzeni kodu, które reprezentują nieujemne liczby całkowite. Rodzina kodowań definiuje maszynową reprezentację sekwencji kodów UCS.
Standard Unicode został opracowany w celu stworzenia jednolitego kodowania znaków dla wszystkich nowoczesnych i wielu starożytnych języków pisanych. Każdy znak w tym standardzie kodowany jest w 16 bitach, co pozwala na pokrycie nieporównywalnie większej liczby znaków niż dotychczas akceptowane kodowania 8-bitowe. Kolejną ważną różnicą między Unicode a innymi systemami kodowania jest to, że nie tylko przypisuje je do każdego znaku Unikalny kod, ale także określa różne cechy tego symbolu, na przykład:
Typ znaku (duża litera, mała litera, cyfra, znak interpunkcyjny itp.);
Atrybuty znaków (wyświetlanie od lewej do prawej lub od prawej do lewej, spacja, podział wiersza itp.);
Odpowiednia wielka lub mała litera (odpowiednio dla małych i wielkich liter);
Odpowiednia wartość numeryczna (dla znaków numerycznych).
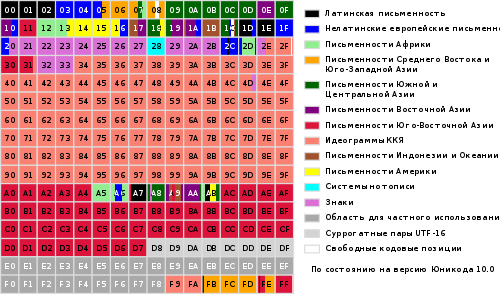
Cały zakres kodów od 0 do FFFF jest podzielony na kilka standardowych podzbiorów, z których każdy odpowiada alfabetowi języka lub grupy znaki specjalne, podobne w swoich funkcjach. Poniższy diagram zawiera ogólną listę podzbiorów Unicode 3.0 (rysunek 2).
Rysunek 2
Standard Unicode jest podstawą przechowywania i tekstu w wielu nowoczesnych systemach komputerowych. Jednak nie jest kompatybilny z większością protokołów internetowych, ponieważ jego kody mogą zawierać dowolne wartości bajtów, a protokoły zwykle używają bajtów 00 - 1F i FE - FF jako narzutu. Aby osiągnąć kompatybilność, opracowano kilka formatów transformacji Unicode (UTF, Unicode Transformation Formats), z których UTF-8 jest obecnie najbardziej powszechny. Ten format definiuje następujące reguły konwersji dla każdego Kod Unicode do zestawu bajtów (od jednego do trzech) odpowiednich do transportu przez protokoły internetowe.
Tutaj x, y, z oznaczają bity kodu źródłowego, które powinny zostać wydobyte, zaczynając od najmniej znaczącego i wprowadzone do bajtów wynikowych od prawej do lewej, aż wszystkie określone pozycje zostaną wypełnione.
Dalszy rozwój standard Unicode wiąże się z dodawaniem nowych płaszczyzn językowych, tj. znaków w zakresach 10000 - 1FFFF, 20000 - 2FFFF itd., gdzie ma zawierać kodowanie dla skryptów martwych języków nie ujętych w powyższej tabeli. Aby zakodować te dodatkowe znaki, opracowano nowy format UTF-16.
Tak więc istnieją 4 główne sposoby kodowania bajtów Unicode:
UTF-8: 128 znaków jest zakodowanych w jednym bajcie (format ASCII), 1920 znaków jest zakodowanych w 2 bajtach ((znaki rzymskie, greckie, cyrylica, koptyjski, ormiański, hebrajski, arabski), 63488 znaków jest zakodowanych w 3 bajtach (chiński , japoński i inne) Pozostałe 2 147 418 112 znaków (jeszcze nie używane) mogą być zakodowane z 4, 5 lub 6 bajtami.
UCS-2: Każdy znak jest reprezentowany przez 2 bajty. To kodowanie obejmuje tylko pierwsze 65 535 znaków z formatu Unicode.
UTF-16: Jest to rozszerzenie do UCS-2 i zawiera 1 114 112 znaków Unicode. Pierwsze 65 535 znaków jest reprezentowanych przez 2 bajty, pozostałe przez 4 bajty.
USC-4: Każdy znak jest zakodowany w 4 bajtach.
Unicode
Logo konsorcjum Unicode
Unicode(najczęściej) lub Unicode(pol. Unicode) to standard kodowania znaków, który umożliwia reprezentację znaków w prawie wszystkich językach pisanych.
Standard został zaproponowany w 1991 roku przez organizację non-profit „Konsorcjum Unicode” (inż. Konsorcjum Unicode, Unicode Inc.).
Zastosowanie tego standardu umożliwia zakodowanie bardzo dużej liczby znaków z różnych skryptów: znaki chińskie, znaki matematyczne, litery alfabetu greckiego, alfabetu łacińskiego i cyrylicy mogą współistnieć w dokumentach Unicode, dzięki czemu przełączanie stron kodowych staje się zbędne.
Norma składa się z dwóch głównych części: uniwersalnego zestawu znaków (ang. UCS, uniwersalny zestaw znaków) i rodziny kodowań (eng. UTF, format transformacji Unicode).
Uniwersalny zestaw znaków definiuje korespondencję jeden do jednego znaków z kodami - elementy przestrzeni kodu, które reprezentują nieujemne liczby całkowite. Rodzina kodowań definiuje maszynową reprezentację sekwencji kodów UCS.
Kody Unicode są podzielone na kilka obszarów. Obszar z kodami od U + 0000 do U + 007F zawiera znaki ASCII z odpowiednimi kodami. Dalej są obszary znaków różnych pism, znaków interpunkcyjnych i symboli technicznych.
Niektóre kody są zarezerwowane do wykorzystania w przyszłości. Pod znakami cyrylicy są alokowane obszary znaków z kodami od U + 0400 do U + 052F, od U + 2DE0 do U + 2DFF, od U + A640 do U + A69F (patrz Cyrylica w Unicode).
- 1 Warunki wstępne tworzenia i rozwoju Unicode
- 2 wersje Unicode
- 3 miejsce na kod
- 4 System kodowania
- 4.1 Polityka konsorcjum
- 4.2 Łączenie i powielanie symboli
- 5 Modyfikowanie postaci
- 6 Algorytmy normalizacji
- 6.1 NFD
- 6.2 NFC
- 6,3 NFKD
- 6.4 NFKC
- 6.5 Przykłady
- 7 Dwukierunkowe pisanie
- 8 wyróżnionych symboli
- 9 ISO/IEC 10646
- 10 sposobów prezentacji
- 10.1 UTF-8
- 10.2 Kolejność bajtów
- 10.3 Unicode i tradycyjne kodowanie
- 10.4 Implementacje
- 11 metod wprowadzania
- 11.1 Microsoft Windows
- 11.2 Macintosh
- 11.3 GNU/Linux
- 12 problemów z Unicode
- 13 „Unicode” czy „Unicode”?
Warunki wstępne tworzenia i rozwoju Unicode
Pod koniec lat 80. standardem stały się 8-bitowe znaki. W tym samym czasie istniało wiele różnych 8-bitowych kodowań i ciągle pojawiały się nowe.
Tłumaczono to zarówno ciągłym poszerzaniem zakresu obsługiwanych języków, jak i chęcią stworzenia kodowania częściowo zgodnego z innym (typowym przykładem jest pojawienie się alternatywnego kodowania dla języka rosyjskiego, ze względu na wykorzystanie zachodniego programy stworzone do kodowania CP437).
W rezultacie pojawiło się kilka problemów:
- problem „krakozyabra”;
- problem ograniczonego zestawu znaków;
- problem konwersji jednego kodowania na inne;
- problem duplikatów czcionek.
Problem „krakozyabr”- problem z wyświetlaniem dokumentów w złym kodowaniu. Problem można rozwiązać albo konsekwentnie wprowadzając metody określania używanego kodowania, albo wprowadzając jedno (wspólne) kodowanie dla wszystkich.
Problem z ograniczonym zestawem znaków... Problem można rozwiązać, zmieniając czcionki w dokumencie lub wprowadzając „szerokie” kodowanie. Przełączanie czcionek było od dawna praktykowane w edytorach tekstu, a często używano czcionek o niestandardowym kodowaniu, tzw. „Czcionki Dingbata”. W rezultacie podczas próby przeniesienia dokumentu do innego systemu wszystkie niestandardowe znaki zamieniały się w „krakozyabry”.
Problem konwersji jednego kodowania na inne... Problem można rozwiązać, kompilując tabele konwersji dla każdej pary kodowań lub używając pośredniej konwersji na trzecie kodowanie, które zawiera wszystkie znaki wszystkich kodowań.
Problem z duplikatami czcionek... Dla każdego kodowania utworzono własną czcionkę, nawet jeśli zestawy znaków w kodowaniach pokrywały się częściowo lub całkowicie. Problem można rozwiązać tworząc „duże” czcionki, z których później wybierane byłyby znaki potrzebne do danego kodowania. Wymagało to jednak stworzenia jednego rejestru symboli w celu określenia, co odpowiada czemu.
Uznano potrzebę stworzenia jednego „szerokiego” kodowania. Stwierdzono, że kodowanie o zmiennej długości, szeroko stosowane w Azji Wschodniej, jest zbyt trudne w użyciu, dlatego zdecydowano się na użycie znaków o stałej szerokości.
Używanie 32-bitowych znaków wydawało się zbyt marnotrawstwem, więc zdecydowano się na 16-bitowe.
Pierwsza wersja Unicode była kodowaniem o stałym rozmiarze znaków 16 bitów, to znaczy, że łączna liczba kodów wynosiła 2 16 (65 536). Od tego czasu znaki są oznaczane czterema cyframi szesnastkowymi (na przykład U + 04F0). Jednocześnie planowano zakodować w Unicode nie wszystkie istniejące znaki, ale tylko te, które są niezbędne w życiu codziennym. Rzadko używane symbole musiały zostać umieszczone w „obszarze prywatnego użytku”, który pierwotnie zajmował kody U + D800 ... U + F8FF.
Aby używać Unicode również jako pośrednika w konwersji różnych kodowań na siebie, zostały w nim uwzględnione wszystkie znaki reprezentowane we wszystkich najbardziej znanych kodowaniach.
W przyszłości postanowiono jednak zakodować wszystkie symbole i w związku z tym znacznie rozszerzyć domenę kodową.
W tym samym czasie kody znaków zaczęto uważać nie za wartości 16-bitowe, ale za abstrakcyjne liczby, które można reprezentować w komputerze na wiele różnych sposobów (patrz metody reprezentacji).
Ponieważ w wielu systemach komputerowych (np. Windows NT) jako domyślne kodowanie stosowano już stałe 16-bitowe znaki, zdecydowano się zakodować wszystkie najważniejsze znaki tylko w obrębie pierwszych 65 536 pozycji (tzw. angielskie). podstawowy samolot wielojęzyczny, BMP).
Reszta miejsca jest przeznaczona na „dodatkowe znaki” (ang. dodatkowe znaki): systemy pisma wymarłych języków lub bardzo rzadko używane znaki chińskie, symbole matematyczne i muzyczne.
Dla kompatybilności ze starymi systemami 16-bitowymi wymyślono układ UTF-16, w którym pierwsze 65 536 pozycji, z wyjątkiem pozycji z przedziału U+D800…U+DFFF, są wyświetlane bezpośrednio jako liczby 16-bitowe, a reszta jest reprezentowana jako „pary zastępcze »(Pierwszy element pary z obszaru U + D800… U + DBFF, drugi element pary z obszaru U + DC00… U + DFFF). W przypadku par zastępczych wykorzystano część przestrzeni kodowej (2048 pozycji), wydzieloną „do użytku prywatnego”.
Ponieważ UTF-16 może wyświetlać tylko 2 20 +2 16 -2048 (1 112 064) znaków, ta liczba została wybrana jako końcowa wartość przestrzeni kodu Unicode (zakres kodów: 0x000000-0x10FFFF).
Chociaż obszar kodu Unicode został rozszerzony poza 2-16 już w wersji 2.0, pierwsze znaki w obszarze „górnym” zostały umieszczone tylko w wersji 3.1.
Rola tego kodowania w sektorze internetowym stale rośnie. Na początku 2010 roku udział stron internetowych korzystających z Unicode wynosił około 50%.
Wersje Unicode
Trwają prace nad finalizacją standardu. Nowe wersje są wydawane w miarę zmian i aktualizacji tabel symboli. Równolegle wydawane są nowe dokumenty ISO/IEC 10646.
Pierwszy standard został wydany w 1991 roku, ostatni w 2016 roku, następny spodziewany jest latem 2017 roku. Wersje standardów 1.0-5.0 zostały opublikowane w formie książkowej i posiadają numer ISBN.
Numer wersji standardu składa się z trzech cyfr (na przykład „4.0.1”). Trzecia cyfra jest zmieniana, gdy wprowadzane są drobne zmiany w standardzie, które nie dodają nowych znaków.
Miejsce na kod
Chociaż formularze notacji UTF-8 i UTF-32 umożliwiają zakodowanie do 2331 (2147483648) punktów kodowych, zdecydowano się użyć tylko 1 112 064 w celu zapewnienia zgodności z UTF-16. Jednak nawet to na razie jest więcej niż wystarczające - w wersji 6.0 wykorzystano nieco mniej niż 110 000 punktów kodowych (109 242 grafiki i 273 inne symbole).
Przestrzeń kodu jest podzielona na 17 samoloty(pol. samoloty) 2 16 (65 536) znaków każdy. Płaszczyzna naziemna ( samolot 0) nazywa się podstawowy (podstawowy) i zawiera symbole najpopularniejszych skryptów. Pozostałe samoloty są dodatkowe ( uzupełniający). Pierwszy samolot ( samolot 1) jest używany głównie do skryptów historycznych, drugi ( samolot 2) - dla rzadko używanych znaków chińskich (CJK), trzeci ( samolot 3) jest zarezerwowane dla archaicznych znaków chińskich. Samoloty 15 i 16 są zarezerwowane do użytku prywatnego.
Oznaczać Znaki Unicode notacja postaci „U + xxxx"(Dla kodów 0 ... FFFF) lub" U + xxxxxx"(Dla kodów 10000 ... FFFFF) lub" U + xxxxxx"(Dla kodów 100000 ... 10FFFF), gdzie XXX- cyfry szesnastkowe. Na przykład symbol „i” (U + 044F) ma kod 044F 16 = 1103 10.
System kodowania
Uniwersalny system kodowania (Unicode) to zbiór symboli graficznych i sposób ich kodowania do komputerowego przetwarzania danych tekstowych.
Symbole graficzne to symbole, które mają widoczny obraz. Znaki graficzne są przeciwieństwem znaków sterujących i formatujących.
Symbole graficzne obejmują następujące grupy:
- litery zawarte w co najmniej jednym z obsługiwanych alfabetów;
- liczby;
- znaki interpunkcyjne;
- znaki specjalne (matematyczne, techniczne, ideogramy itp.);
- separatory.
Unicode to system liniowej reprezentacji tekstu. Znaki z dodatkowymi indeksami górnymi lub dolnymi mogą być reprezentowane jako ciąg kodów zbudowanych według określonych reguł (znak złożony) lub jako pojedynczy znak (wersja monolityczna, znak prekomponowany). Na ten moment(2014), uważa się, że wszystkie litery dużych skryptów są zawarte w Unicode, a jeśli symbol jest dostępny w wersji złożonej, nie jest konieczne powielanie go w formie monolitycznej.
Polityka konsorcjum
Konsorcjum nie tworzy nowego, ale ustala ustalony porządek rzeczy. Na przykład zdjęcia emoji zostały dodane, ponieważ japońscy operatorzy komunikacja mobilna były szeroko stosowane.
Aby to zrobić, dodawanie symbolu przechodzi przez złożony proces. I na przykład symbol rubla rosyjskiego przeszedł go w trzy miesiące tylko dlatego, że otrzymał oficjalny status.
Znaki towarowe są kodowane tylko w drodze wyjątku. Tak więc w Unicode nie ma flagi Windows ani jabłka Apple.
Gdy znak pojawi się w kodowaniu, nigdy się nie przesunie ani nie zniknie. Jeśli konieczna jest zmiana kolejności znaków, odbywa się to nie poprzez zmianę pozycji, ale według krajowego porządku sortowania. Istnieją inne, bardziej subtelne gwarancje stabilności - na przykład tabele normalizacyjne nie ulegną zmianie.
Łączenie i powielanie symboli
Ten sam symbol może przybierać różne formy; w Unicode te formularze są zawarte w jednym punkcie kodowym:
- gdyby wydarzyło się to historycznie. Na przykład litery arabskie mają cztery formy: oderwane, na początku, w środku i na końcu;
- lub jeśli jeden język zostanie przyjęty w jednej formie, a w innej - w innej. Bułgarska cyrylica różni się od rosyjskiego, a chińskie od japońskiego.
Z drugiej strony, jeśli historycznie czcionki miały dwa różne punkty kodowe, pozostają różne w Unicode. Mała grecka sigma ma dwie formy i mają różne pozycje. Rozszerzona litera łacińska Å (A z kółkiem) i znak angstremów Å, grecki listμ i przedrostek „mikro” μ to różne symbole.
Oczywiście podobne znaki w niepowiązanych skryptach są umieszczane w różnych pozycjach kodu. Na przykład litera A po łacinie, cyrylicy, grece i czirokezie to różne symbole.
Niezwykle rzadko ten sam znak jest umieszczany w dwóch różnych pozycjach kodu w celu uproszczenia przetwarzania tekstu. Skok matematyczny i ten sam skok wskazujący miękkość dźwięków to różne symbole, drugi jest uważany za literę.
Modyfikowanie postaci
Przedstawienie znaku „Y” (U+0419) w postaci znaku bazowego „I” (U+0418) oraz znaku modyfikującego „” (U+0306)
Znaki graficzne w Unicode są podzielone na rozszerzone i nierozszerzone (bez szerokości). Znaki, które nie są rozszerzone, nie zajmują miejsca w wierszu podczas wyświetlania. Należą do nich w szczególności znaki akcentujące i inne znaki diakrytyczne. Zarówno znaki rozszerzone, jak i nierozszerzone mają swoje własne kody. Rozszerzone symbole są inaczej nazywane podstawowymi (ang. podstawowe postacie) i nierozszerzonych - przerabianie (ang. łączenie znaków); a ci ostatni nie mogą spotykać się samodzielnie. Na przykład znak „á” może być reprezentowany jako sekwencja znaku podstawowego „a” (U + 0061) i znaku modyfikującego „́” (U + 0301) lub jako znak monolityczny „á” (U + 00E1).
Szczególnym rodzajem znaków modyfikujących są selektory stylu (ang. selektory odmiany). Dotyczą one tylko tych symboli, dla których zdefiniowano takie warianty. W wersji 5.0 opcje stylu są zdefiniowane dla serii symbole matematyczne, dla symboli tradycyjnego alfabetu mongolskiego i symboli mongolskiego pisma kwadratowego.
Algorytmy normalizacji
Ponieważ te same symbole mogą być reprezentowane różne kody, porównanie ciągów bajt po bajcie staje się niemożliwe. Algorytmy normalizacji formularze normalizacyjne) rozwiązać ten problem, konwertując tekst do określonej standardowej postaci.
Odlewanie odbywa się poprzez zastępowanie symboli równoważnymi za pomocą tabel i reguł. „Dekompozycja” to zamiana (dekompozycja) jednego znaku na kilka znaków składowych, a „składanie”, przeciwnie, to zamiana (połączenie) kilku znaków składowych jednym znakiem.
Standard Unicode definiuje 4 algorytmy normalizacji tekstu: NFD, NFC, NFKD i NFKC.
NFD
NFD, inż. n normalizacja F orm D („D” z angielskiego. D ekompozycja), formą normalizacyjną D jest dekompozycja kanoniczna - algorytm, według którego odbywa się rekurencyjne zastępowanie symboli monolitycznych (eng. prekomponowane postacie) na kilka elementów (ang. złożone znaki) zgodnie z tabelami rozkładu.
Å U + 00C5 →
A U + 0041
̊ U + 030A
ṩ U + 1E69 →
s U + 0073
̣ U + 0323
̇ U + 0307
ḍ̇ U + 1E0B U + 0323 →
D U + 0064
̣ U + 0323
̇ U + 0307
Q U + 0071 U + 0307 U + 0323 →
Q U + 0071
̣ U + 0323
̇ U + 0307 NFC
NFC, inż. n normalizacja F orm C („C” z angielskiego. C kompozycja), postać normalizacyjna C jest algorytmem, zgodnie z którym dekompozycja kanoniczna i kompozycja kanoniczna są wykonywane sekwencyjnie. Najpierw dekompozycja kanoniczna (algorytm NFD) redukuje tekst do postaci D. Następnie złożenie kanoniczne, odwrotność NFD, przetwarza tekst od początku do końca, biorąc pod uwagę następujące zasady:
- symbol S liczy się Inicjał jeśli ma klasę modyfikacji równą zero zgodnie z tabelą znaków Unicode;
- w dowolnej sekwencji znaków zaczynającej się od znaku S, symbol C zablokowany z S, tylko jeśli pomiędzy S oraz C czy jest jakiś symbol? b który jest albo początkowy, albo ma taką samą lub większą klasę modyfikacji niż C... Ta zasada dotyczy tylko strun, które przeszły rozkład kanoniczny;
- symbol jest brany pod uwagę podstawowy złożony, jeśli ma rozkład kanoniczny w tabeli znaków Unicode (lub rozkład kanoniczny dla Hangul i nie znajduje się na liście wykluczeń);
- symbol x można najpierw połączyć z symbolem Tak wtedy i tylko wtedy, gdy istnieje kompozyt pierwotny Z, kanonicznie równoważny sekwencji<x, Tak>;
- jeśli następny znak C nie blokowany przez ostatni napotkany znak startowy L i można go z powodzeniem najpierw połączyć z nim L zastąpiony przez kompozyt L-C, a C REMOVED.
o U + 006F
̂ U + 0302 → →
h U + 0048
① U + 2460 →
1 U + 0031
カ U + FF76 →
カ U + 30AB →
fi U + FB01
fi U + FB01
F i U + 0066 U + 0069
F i U + 0066 U + 0069
2 ⁵ U + 0032 U + 2075
2 ⁵ U + 0032 U + 2075
2 ⁵ U + 0032 U + 2075
2 5 U + 0032 U + 0035
2 5 U + 0032 U + 0035
ẛ̣ U + 1E9B U + 0323
s ̣ ̇ U + 017F U + 0323 U + 0307
ẛ ̣ U + 1E9B U + 0323
s ̣ ̇ U + 0073 U + 0323 U + 0307
ṩ U + 1E69
NS U + 0439
oraz ̆ U + 0438 U + 0306
NS U + 0439
oraz ̆ U + 0438 U + 0306
NS U + 0439
mi U + 0451
mi ̈ U + 0435 U + 0308
mi U + 0451
mi ̈ U + 0435 U + 0308
mi U + 0451
A U + 0410
A U + 0410
A U + 0410
A U + 0410
A U + 0410
が U + 304C
か ゙ U + 304B U + 3099
が U + 304C
か ゙ U + 304B U + 3099
が U + 304C
Ⅷ U + 2167
Ⅷ U + 2167
Ⅷ U + 2167
V i i i U + 0056 U + 0049 U + 0049 U + 0049
V i i i U + 0056 U + 0049 U + 0049 U + 0049
ç U + 00E7
C ̧ U + 0063 U + 0327
ç U + 00E7
C ̧ U + 0063 U + 0327
ç U + 00E7 Dwukierunkowa litera
Standard Unicode obsługuje języki pisania w kierunku od lewej do prawej (eng. od lewej do prawej, LTR) oraz zapisem od prawej do lewej (eng. od prawej do lewej, RTL) - na przykład litery arabskie i hebrajskie. W obu przypadkach postacie są przechowywane w „naturalnej” kolejności; ich wyświetlanie, z uwzględnieniem pożądanego kierunku litery, zapewnia aplikacja.
Ponadto Unicode obsługuje połączone teksty, które łączą fragmenty z różnymi kierunkami litery. Ta funkcja nazywa się dwukierunkowość(pol. tekst dwukierunkowy, BiDi). Niektóre uproszczone procesory tekstu (na przykład in telefony komórkowe) może obsługiwać Unicode, ale nie obsługuje dwukierunkowości. Wszystkie znaki Unicode są podzielone na kilka kategorii: pisane od lewej do prawej, pisane od prawej do lewej i pisane w dowolnym kierunku. Symbole tej drugiej kategorii (głównie znaki interpunkcyjne), gdy są wyświetlane, przyjmują kierunek otaczającego tekstu.
Polecane symbole
Schemat podstawowej wielojęzycznej płaszczyzny Unicode
Unicode zawiera praktycznie wszystkie współczesne skrypty, w tym:
- arabski
- Ormiański,
- Bengalski,
- Birmańczyk,
- czasownik
- grecki
- Gruziński,
- dewanagari,
- Żydowski,
- cyrylica,
- chiński (znaki chińskie są aktywnie używane w języku japońskim, a także sporadycznie w koreańskim),
- Koptyjski,
- Khmerów,
- Łacina,
- Tamil,
- koreański (Hangul),
- Czirokezów,
- Etiopczyk,
- japoński (w skład którego oprócz sylabicznego alfabetu wchodzą również chińskie znaki)
inny.
Dla celów akademickich dodano wiele skryptów historycznych, w tym: runy germańskie, starożytne runy tureckie, starożytne pismo greckie, egipskie hieroglify, pismo klinowe, pismo Majów, alfabet etruski.
Unicode zapewnia szeroką gamę symboli i piktogramów matematycznych i muzycznych.
W zasadzie Unicode nie zawiera flag państwowych, logo firm i produktów, chociaż znajdują się one w czcionkach (na przykład logo Apple w kodowaniu MacRoman (0xF0) lub logo Windows w czcionce Wingdings (0xFF)). W czcionkach Unicode logo należy umieszczać tylko w niestandardowym obszarze znaków.
ISO / IEC 10646
Konsorcjum Unicode ściśle współpracuje z Grupa robocza ISO/IEC/JTC1/SC2/WG2, który rozwija międzynarodowy standard 10646 (ISO/IEC 10646). Synchronizacja jest ustanawiana między standardem Unicode a ISO / IEC 10646, chociaż każdy standard używa własnej terminologii i systemu dokumentacji.
Współpraca Konsorcjum Unicode z Międzynarodową Organizacją Normalizacyjną (inż. Międzynarodowa Organizacja Normalizacyjna, ISO ) rozpoczęła się w 1991 roku. W 1993 roku ISO wydała normę DIS 10646.1. Aby zsynchronizować się z nim, Konsorcjum zatwierdziło wersję 1.1 standardu Unicode, która dodała dodatkowe znaki z DIS 10646.1. W rezultacie wartości zakodowanych znaków w Unicode 1.1 i DIS 10646.1 są dokładnie takie same.
W przyszłości współpraca między obiema organizacjami była kontynuowana. W 2000 roku standard Unicode 3.0 został zsynchronizowany z ISO/IEC 10646-1:2000. Nadchodząca trzecia wersja ISO/IEC 10646 zostanie zsynchronizowana z Unicode 4.0. Być może te specyfikacje zostaną nawet opublikowane jako jeden standard.
Podobnie jak formaty UTF-16 i UTF-32 w standardzie Unicode, standard ISO/IEC 10646 ma również dwie główne formy kodowania znaków: UCS-2 (2 bajty na znak, podobnie do UTF-16) i UCS-4 (4 bajty na znak, podobnie do UTF-32). LUW oznacza uniwersalny wielooktet(wielobajtowy) zakodowany zestaw znaków(pol. uniwersalny wielooktetowy zestaw znaków kodowanych ). UCS-2 można uznać za podzbiór UTF-16 (UTF-16 bez par zastępczych), a UCS-4 jest synonimem UTF-32.
Różnice między standardami Unicode i ISO/IEC 10646:
- niewielkie różnice w terminologii;
- ISO/IEC 10646 nie zawiera sekcji wymaganych do pełnej implementacji obsługi Unicode:
- brak danych na kodowanie binarne postacie;
- brak opisu algorytmów porównawczych (inż. porównanie) i renderowania (ang. wykonanie) postacie;
- nie ma listy właściwości symboli (na przykład nie ma listy właściwości wymaganych do zaimplementowania obsługi dwukierunkowości (eng. dwukierunkowy) listy).
Metody prezentacji
Unicode ma kilka form reprezentacji (eng. Format transformacji Unicode, UTF ): UTF-8, UTF-16 (UTF-16BE, UTF-16LE) i UTF-32 (UTF-32BE, UTF-32LE). Forma reprezentacji UTF-7 została również opracowana do transmisji przez kanały siedmiobitowe, ale ze względu na niezgodność z ASCII nie została rozpowszechniona i nie została uwzględniona w standardzie. 1 kwietnia 2005 zaproponowano dwa humorystyczne zgłoszenia: UTF-9 i UTF-18 (RFC 4042).
Systemy Microsoft Windows NT, Windows 2000 i Windows XP używają głównie formatu UTF-16LE. Systemy operacyjne typu UNIX GNU / Linux, BSD i Mac OS X przyjmują UTF-8 dla plików i UTF-32 lub UTF-8 do przetwarzania znaków w pamięć o dostępie swobodnym.
Punycode to kolejna forma kodowania sekwencji znaków Unicode w tak zwane sekwencje ACE, które składają się wyłącznie ze znaków alfanumerycznych, co jest dozwolone w nazwach domen.
UTF-8
UTF-8 to reprezentacja Unicode, która zapewnia najlepszą kompatybilność ze starszymi systemami, które używały znaków 8-bitowych.
Tekst zawierający tylko znaki o numerach mniejszych niż 128 jest konwertowany na zwykły tekst ASCII podczas zapisywania w UTF-8. I odwrotnie, w tekście UTF-8 wyświetlany jest dowolny bajt o wartości mniejszej niż 128 Znak ASCII z tym samym kodem.
Pozostałe znaki Unicode są reprezentowane przez sekwencje o długości od 2 do 6 bajtów (w rzeczywistości tylko do 4 bajtów, ponieważ w Unicode nie ma znaków o kodzie większym niż 10FFFF i nie planuje się ich wprowadzenia w przyszłość), w której pierwszy bajt ma zawsze postać 11xxxxxx a reszta to 10xxxxxx... W UTF-8 nie są używane żadne pary zastępcze, 4 bajty wystarczą do napisania dowolnego znaku Unicode.
Format UTF-8 został wynaleziony 2 września 1992 roku przez Kena Thompsona i Roba Pike'a i zaimplementowany w Planie 9... Standard UTF-8 jest teraz oficjalnie zapisany w RFC 3629 i ISO / IEC 10646 załącznik D.
Znaki UTF-8 pochodzą z Unicode w następujący sposób:
Unicode UTF-8: 0x00000000 - 0x0000007F: 0xxxxxxx 0x00000080 - 0x000007FF: 110xxxxx 10xxxxxx 0x00000800 - 0x0000FFFF: 1110xxxx 10xxxxxx 10xxxxxx 0x00010000 - 0x001FFFFF: 11110xxx 10xxxxxx 10xxxxxx 10xxxx
Teoretycznie możliwe, ale również nieuwzględnione w standardzie:
0x00200000 - 0x03FFFFFF: 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 0x04000000 - 0x7FFFFFFFF: 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
Chociaż UTF-8 pozwala na określenie tego samego znaku na kilka sposobów, tylko najkrótszy jest poprawny. Pozostałe formularze należy odrzucić ze względów bezpieczeństwa.
Kolejność bajtów
W strumieniu danych UTF-16 młodszy bajt może być zapisany przed wysokim (eng. UTF-16 little-endian) lub po senior (pol. UTF-16 big-endian). Podobnie istnieją dwa warianty kodowania czterobajtowego - UTF-32LE i UTF-32BE.
Aby zdefiniować format reprezentacji Unicode na początku plik tekstowy podpis jest napisany - znak U + FEFF (spacja nierozdzielająca o zerowej szerokości), zwany również bajtowy znacznik sekwencji(pol. znak kolejności bajtów (BOM)). Umożliwia to rozróżnienie między UTF-16LE i UTF-16BE, ponieważ nie ma znaku U + FFFE. Czasami jest również używany do oznaczenia formatu UTF-8, chociaż pojęcie kolejności bajtów nie ma zastosowania do tego formatu. Pliki zgodne z tą konwencją zaczynają się od następujących sekwencji bajtów:
UTF-8 EF BB BF UTF-16BE FE FF UTF-16LE FF FE UTF-32BE 00 00 FE FF UTF-32LE FF FE 00 00
Niestety ta metoda nie rozróżnia niezawodnie UTF-16LE i UTF-32LE, ponieważ znak U + 0000 jest dozwolony przez Unicode (chociaż prawdziwe teksty rzadko się od niego zaczynają).
Pliki w kodowaniu UTF-16 i UTF-32, które nie zawierają BOM, muszą być w kolejności bajtów big-endian (unicode.org).
Unicode i tradycyjne kodowanie
Wprowadzenie Unicode zmieniło podejście do tradycyjnego kodowania 8-bitowego. Jeśli wcześniej kodowanie zostało określone przez czcionkę, teraz jest określone przez tabelę korespondencji między tym kodowaniem a Unicode.
W rzeczywistości kodowanie 8-bitowe stało się formą reprezentowania podzbioru Unicode. To znacznie ułatwiło tworzenie programów, które muszą pracować z wieloma różnymi kodowaniami: teraz, aby dodać obsługę jeszcze jednego kodowania, wystarczy dodać kolejną tabelę przeglądową Unicode.
Ponadto wiele formatów danych umożliwia wstawianie dowolnych znaków Unicode, nawet jeśli dokument jest zapisany w starym 8-bitowym kodowaniu. Na przykład możesz używać kodów ampersand w HTML.
Realizacja
Większość nowoczesnych systemów operacyjnych zapewnia pewien stopień obsługi Unicode.
W systemach operacyjnych z rodziny Windows NT dwubajtowe kodowanie UTF-16LE jest używane do wewnętrznej reprezentacji nazw plików i innych ciągów systemowych. Wywołania systemowe, które przyjmują parametry łańcuchowe, są dostępne w wariantach jednobajtowych i dwubajtowych. Aby uzyskać więcej informacji, zobacz artykuł Unicode dotyczący rodziny systemów operacyjnych Microsoft Windows.
podobny do UNIX OS, w tym GNU / Linux, BSD, OS X, używają kodowania UTF-8 do reprezentowania Unicode. Większość programów może obsługiwać UTF-8 jako tradycyjne kodowanie jednobajtowe, niezależnie od faktu, że znak jest reprezentowany jako kilka kolejnych bajtów. Aby pracować z pojedynczymi znakami, łańcuchy są zwykle przekodowywane do UCS-4, tak aby każdy znak miał słowo maszynowe.
Jedną z pierwszych udanych komercyjnych implementacji Unicode była środa programowanie w Javie... Zasadniczo porzucił 8-bitową reprezentację znaków na rzecz 16-bitowej. To rozwiązanie zwiększyło zużycie pamięci, ale pozwoliło nam zwrócić ważną abstrakcję do programowania: dowolny pojedynczy znak (typ zwęglać). W szczególności programista może pracować z ciągiem znaków jak z prostą tablicą. Niestety sukces nie był ostateczny, Unicode przerósł 16-bitowy limit i przez J2SE 5.0 dowolny znak ponownie zaczął zajmować zmienną liczbę jednostek pamięci - jedną zwęglać lub dwa (patrz para zastępcza).
Większość języków programowania obsługuje teraz ciągi Unicode, chociaż ich reprezentacja może się różnić w zależności od implementacji.
Metody wprowadzania
Ponieważ żaden układ klawiatury nie umożliwia jednoczesnego wprowadzania wszystkich znaków Unicode, wymagane jest wsparcie ze strony systemów operacyjnych i aplikacji. alternatywne metody wprowadź dowolne znaki Unicode.
Microsoft Windows
Chociaż począwszy od systemu Windows 2000, narzędzie Mapa znaków (charmap.exe) obsługuje znaki Unicode i umożliwia kopiowanie ich do schowka, ta obsługa jest ograniczona tylko do płaszczyzny bazowej (kody znaków U + 0000… U + FFFF). Symbole z kodami od U + 10000 "Tabela symboli" nie są wyświetlane.
Podobna tabela jest na przykład w Microsoft Word.
Czasami możesz wpisać kod szesnastkowy, nacisnąć Alt + X, a kod zostanie zastąpiony odpowiednim znakiem, na przykład w WordPad, Microsoft Word. W edytorach Alt + X wykonuje również odwrotną transformację.
W wielu programach MS Windows, aby uzyskać znak Unicode, należy nacisnąć klawisz Alt i wpisać wartość dziesiętną kodu znaku na klawiatura numeryczna... Na przykład kombinacje Alt + 0171 ("), Alt + 0187 (") i Alt + 0769 (akcent) będą przydatne podczas pisania cyrylicą. Interesujące są również kombinacje Alt + 0133 (…) i Alt + 0151 (-).
Prochowiec
Mac OS 8.5 i nowsze obsługują metodę wprowadzania o nazwie „Wprowadzanie szesnastkowe Unicode”. Trzymając wciśnięty klawisz Option, musisz wpisać czterocyfrowy kod szesnastkowy żądanego znaku. Ta metoda umożliwia wprowadzanie znaków o kodach większych niż U + FFFF przy użyciu par zastępczych; takie pary zostaną automatycznie zastąpione przez system operacyjny pojedynczymi znakami. Tę metodę wprowadzania należy aktywować w odpowiedniej sekcji przed użyciem. Ustawienia systemowe a następnie wybierz jako bieżącą metodę wprowadzania z menu klawiatury.
Począwszy od systemu Mac OS X 10.2 dostępna jest również aplikacja Character Palette, która umożliwia wybieranie znaków z tabeli, w której można wybierać znaki z określonego bloku lub znaki obsługiwane przez określoną czcionkę.
GNU / Linux
GNOME posiada również narzędzie Mapa symboli (dawniej gucharmap), które umożliwia wyświetlanie symboli dla określonego bloku lub systemu pisania i zapewnia możliwość wyszukiwania według nazwy lub opisu symbolu. Gdy znany jest kod żądanego znaku, można go wprowadzić zgodnie ze standardem ISO 14755: trzymając wciśnięte klawisze Ctrl + ⇧ Shift, wprowadź kod szesnastkowy (zaczynając od niektórych wersji GTK +, kod należy wprowadzić naciskając "U"). Wprowadzony kod szesnastkowy może mieć długość do 32 bitów, co pozwala na wprowadzanie dowolnych znaków Unicode bez używania par zastępczych.
Wszystkie aplikacje X Window, w tym GNOME i KDE, obsługują wprowadzanie klawisza Compose. W przypadku klawiatur, które nie mają dedykowanego klawisza Compose, można do tego celu przypisać dowolny klawisz – np. ⇪ Duże litery.
Konsola GNU/Linux umożliwia również wprowadzenie znaku Unicode przez jego kod - w tym celu kod dziesiętny znaku należy wprowadzić jako cyfry rozszerzonego bloku klawiatury przy wciśniętym klawiszu Alt. Możesz wprowadzać znaki według ich kodu szesnastkowego: w tym celu musisz przytrzymać klawisz AltGr i wpisać cyfry A-F użyj klawiszy na rozszerzonym bloku klawiatury od NumLock do ↵ Enter (zgodnie z ruchem wskazówek zegara). Obsługiwane jest również wejście zgodne z ISO 14755. Aby powyższe metody działały należy włączyć w konsoli tryb Unicode wywołując unicode_start(1) i wybierz odpowiednią czcionkę dzwoniąc setfont(8).
Mozilla Firefox dla systemu Linux obsługuje wprowadzanie znaków ISO 14755.
Problemy z Unicode
W Unicode angielskie „a” i polskie „a” mają ten sam znak. W ten sam sposób rosyjskie „a” i serbskie „a” są uważane za ten sam symbol (ale inny od łacińskiego „a”). Ta zasada kodowania nie jest uniwersalna; najwyraźniej rozwiązanie „na każdą okazję” w ogóle nie może istnieć.
- Chiński, koreański i japoński są tradycyjnie pisane od góry do dołu, zaczynając od prawego górnego rogu. Przełączanie między pisownią poziomą i pionową dla tych języków nie jest przewidziane w Unicode - należy to robić za pomocą języków znaczników lub wewnętrznych mechanizmów edytorów tekstu.
- Unicode pozwala na różne wagi tego samego znaku w zależności od języka. Tak więc znaki chińskie mogą mieć różne wagi w języku chińskim, japońskim (kanji) i koreańskim (hancha), ale jednocześnie w Unicode są oznaczane tym samym symbolem (tzw. unifikacja CJK), chociaż nadal uproszczone i pełne znaki mają różne kody ... Podobnie języki rosyjski i serbski używają różnych liter kursywy. NS oraz T(po serbsku wyglądają jak u i w, patrz serbska kursywa). Dlatego musisz upewnić się, że tekst jest zawsze poprawnie oznaczony jako związany z tym lub innym językiem.
- Tłumaczenie z małych na wielkie również zależy od języka. Na przykład: w języku tureckim występują litery İi i Iı – stąd tureckie zasady zmiany wielkości liter są sprzeczne z angielskimi, które wymagają przetłumaczenia „i” na „I”. Podobne problemy występują w innych językach – np. w kanadyjskim dialekcie francuskiego rejestr jest tłumaczony nieco inaczej niż we Francji.
- Nawet w przypadku cyfr arabskich istnieją pewne subtelności typograficzne: liczby są „wielkie” i „małe”, proporcjonalne i o stałej szerokości - w przypadku Unicode nie ma między nimi różnicy. Takie niuanse pozostają w oprogramowaniu.
Niektóre wady nie są związane z samym Unicode, ale raczej z możliwościami procesorów tekstu.
- Pliki tekstu niełacińskiego w Unicode zawsze zajmują więcej miejsca, ponieważ jeden znak jest kodowany nie jednym bajtem, jak w różnych kodowaniach narodowych, ale sekwencją bajtów (wyjątkiem jest UTF-8 dla języków, których alfabet pasuje na ASCII, a także obecność dwóch znaków w tekście i więcej języków, których alfabet nie pasuje do ASCII). Plik czcionki wymagany do wyświetlenia wszystkich znaków w tabeli Unicode zajmuje stosunkowo dużo pamięci i zasobów obliczeniowych niż czcionka w języku narodowym tylko jednego użytkownika. Wraz ze wzrostem mocy systemów komputerowych oraz spadkiem kosztów pamięci i przestrzeni dyskowej problem ten staje się coraz mniej istotny; jednak pozostaje istotne w przypadku urządzeń przenośnych, takich jak telefony komórkowe.
- Chociaż obsługa Unicode jest zaimplementowana w najpopularniejszych systemach operacyjnych, do tej pory nie wszystkie stosowane oprogramowanie obsługuje poprawna praca z nim. W szczególności znaczniki kolejności bajtów (BOM) nie zawsze są przetwarzane, a znaki akcentowane są słabo obsługiwane. Problem jest przejściowy i wynika z porównawczej nowości standardów Unicode (w porównaniu z jednobajtowymi kodowaniami narodowymi).
- Wydajność wszystkich programów do przetwarzania ciągów (w tym sortowania w bazie danych) zmniejsza się, gdy zamiast kodowania jednobajtowego używany jest kod Unicode.
Niektóre rzadkie systemy pisania wciąż nie są dobrze reprezentowane w Unicode. Przedstawienie „długich” znaków w indeksie górnym, rozciągających się na kilka liter, jak na przykład w cerkiewnosłowiańskim, nie zostało jeszcze wprowadzone.
Unicode czy Unicode?
„Unicode” to zarówno nazwa własna (lub część nazwy, na przykład Konsorcjum Unicode), jak i nazwa zwyczajowa pochodząca z języka angielskiego.
Na pierwszy rzut oka preferowana jest pisownia „Unicode”. W języku rosyjskim istnieją już morfemy „uni-” (słowa z łacińskim elementem „uni-” były tradycyjnie tłumaczone i pisane przez „uni-”: uniwersalny, jednobiegunowy, unifikacyjny, jednolity) i „kod”. Przeciwko, znaki towarowe, zapożyczone z języka angielskiego, są zwykle przekazywane za pomocą praktycznej transkrypcji, w której zdeetymologizowana kombinacja liter „uni-” jest zapisana jako „uni-” („Unilever”, „Unix” itp.), czyli w taki sam sposób, jak w przypadku akronimów litera po literze, takich jak UNICEF „Międzynarodowy Fundusz Narodów Zjednoczonych na rzecz Dzieci” – UNICEF.
Pisownia „Unicode” już mocno weszła w teksty rosyjskojęzyczne. Wikipedia używa bardziej popularnej wersji. W MS Windows używana jest opcja Unicode.
Na stronie Konsorcjum istnieje specjalna strona, na której pojawiają się problemy z przeniesieniem słowa „Unicode” na inne języki i systemy pisania. W przypadku rosyjskiego alfabetu cyrylicy określono opcję „Unicode”.
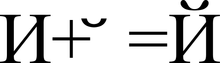
Problemy związane z kodowaniem są zwykle rozwiązywane przez oprogramowanie, więc zwykle nie ma trudności w korzystaniu z kodowania. Jeśli pojawiają się trudności, to zazwyczaj są one generowane przez złe programy - nie krępuj się wyrzucać ich do kosza.
Zapraszam wszystkich do mówienia w
ASCII (ang. English American Standard Code for Information Interchange) - amerykańska standardowa tabela kodowania dla znaków drukowalnych i niektórych kodów specjalnych. W amerykańskim angielskim wymawia się [Éski], podczas gdy w Wielkiej Brytanii [Aski] jest bardziej wymawiane; w języku rosyjskim wymawia się również [aski] lub [aski].
ASCII to kodowanie cyfr dziesiętnych, alfabetów łacińskich i narodowych, znaków interpunkcyjnych i kontrolnych. Pierwotnie zaprojektowany jako 7-bitowy, z powszechnym użyciem 8-bitowego bajtu ASCII, zaczął być uważany za połowę 8-bitowego. Komputery zwykle używają rozszerzeń ASCII z ósmym bitem i drugą połową tabeli kodów (na przykład KOI-8).
Unicode
W 1991 roku w Kalifornii powstała organizacja non-profit Unicode Consortium, w skład której wchodzą przedstawiciele wielu firm komputerowych (Borland, IBM, Lotus, Microsoft, Novell, Sun, WordPerfect itp.), która opracowuje i wdraża standard” Standard Unicode”... Standard kodowania znaków Unicode staje się dominujący w międzynarodowych wielojęzycznych środowiskach oprogramowania. Microsoft Windows NT i jego potomkowie Windows 2000, 2003, XP używają Unicode, a dokładniej UTF-16, jako wewnętrznej reprezentacji tekstu. Systemy operacyjne typu UNIX, takie jak Linux, BSD i Mac OS X, przyjęły Unicode (UTF-8) jako podstawową reprezentację tekstu wielojęzycznego. Unicode rezerwuje 1114 112 (220 + 216) znaków kodu, obecnie używanych jest ponad 96 000 znaków. Pierwsze 256-znakowe kody odpowiadają dokładnie kodom ISO 8859-1, najpopularniejszej 8-bitowej tablicy znaków w świecie zachodnim; w rezultacie pierwsze 128 znaków jest również identycznych z tablicą ASCII. Przestrzeń kodu Unicode jest podzielona na 17 „płaszczyzn”, a każdy plan ma 65536 (= 216) punktów kodowych. Pierwsza płaszczyzna (płaszczyzna 0), podstawowa płaszczyzna wielojęzyczna (BMP) to ta, w której opisana jest większość znaków. BMP zawiera symbole dla prawie wszystkich współczesne języki i dużą liczbę znaków specjalnych. Dwie kolejne płaszczyzny są używane do symboli „graficznych”. Płaszczyzna 1, dodatkowa płaszczyzna wielojęzyczna (SMP) jest używana głównie do symboli historycznych, a także do symboli muzycznych i matematycznych. Plan 2, dodatkowa płaszczyzna ideograficzna (SIP), jest używany dla około 40 000 rzadkich znaków chińskich. Plan 15 i Plan 16 są dostępne do użytku prywatnego. Rysunek 1.10 przedstawia rosyjski blok Unicode (U + 0400 do U + 04FF).
Wspólne kodowania
ISO 646 ASCII BCDIC EBCDIC ISO 8859: ISO 8859-1, ISO 8859-2, ISO 8859-3, ISO 8859-4, ISO 8859-5, ISO 8859-6, ISO 8859-7, ISO 8859-8, ISO 8859 -9, ISO 8859-10, ISO 8859-11, ISO 8859-13, ISO 8859-14, ISO 8859-15 CP437, CP737, CP850, CP852, CP855, CP857, CP858, CP860, CP861, CP863, CP865, CP866 , CP869 Kodowania Microsoft Windows: Windows-1250 dla języków środkowoeuropejskich używających pisowni łacińskiej (polski, czeski, słowacki, węgierski, słoweński, chorwacki, rumuński i albański) Windows-1251 dla cyrylicy Windows-1252 dla języków zachodnich Windows-1253 dla Grecki Windows-1254 dla tureckiego Windows-1255 dla hebrajskiego Windows-1256 dla arabskiego Windows-1257 dla języków bałtyckich Windows-1258 dla wietnamskiego MacRoman, MacCyrillic KOI8 (KOI8-R, KOI8-U ...), KOI-7 bułgarski Kodowanie ISCII VISCII Big5 (najsłynniejszy wariant Microsoft CP950) HKSCS Guobiao GB2312 GBK (Microsoft CP936) GB18030 Shift JIS dla japońskiego (Microsoft CP932) EUC-KR dla koreańskiego (Microsoft CP949) ISO-2022 i EUC dla chińskiego kodowania UTF-8, Zestawy znaków Unicode UTF-16 i UTF-32 \
Kodowanie informacji graficznych
Od lat 80-tych. rozwija się technologia przetwarzania informacji graficznych na komputerze PC. Forma przedstawienia na ekranie wyświetlacza obrazu graficznego składającego się z pojedynczych kropek (pikseli) nazywana jest rastrem. Minimalnym obiektem w edytorze grafiki rastrowej jest punkt. Edytor grafiki rastrowej przeznaczony jest do tworzenia obrazów, diagramów. Rozdzielczość monitora (liczba kropek poziomych i pionowych), a także liczba możliwych kolorów każdej kropki jest określona przez typ monitora 1 piksel czarno-białego ekranu jest zakodowany 1 bitem informacji (czarna kropka lub biała kropka). Liczbę różnych kolorów K i liczbę bitów do ich zakodowania wiąże wzór: K = 2b. Nowoczesne monitory posiadają następujące palety kolorów: 16 kolorów, 256 kolorów; 65 536 kolorów (wysoki kolor), 16 777 216 kolorów (true color).
Mapa bitowa
Przy pomocy lupy widać, że czarno-biały obraz graficzny, np. z gazety, składa się z najmniejszych kropek, które układają się w pewien wzór - raster. We Francji w XIX wieku powstał nowy kierunek w malarstwie - puentylizm. Jego technika polegała na tym, że rysunek nanoszony był na płótno pędzlem w postaci wielobarwnych kropek. Również ta metoda jest od dawna stosowana w przemyśle poligraficznym do kodowania informacji graficznych. Dokładność rysunku zależy od ilości kropek i ich wielkości. Po podzieleniu obrazu na punkty, zaczynając od lewego rogu, przesuwając się wzdłuż linii od lewej do prawej, można zakodować kolor każdego punktu. Co więcej, jeden taki punkt będzie nazywany pikselem (pochodzenie tego słowa jest związane z angielskim skrótem „element obrazu” - element obrazu). Objętość obrazu rastrowego określa się mnożąc liczbę pikseli (przez objętość informacyjną jednego punktu, która zależy od liczby możliwych kolorów. O jakości obrazu decyduje rozdzielczość monitora. Im wyższa, tym oznacza to, że im więcej linii rastrowych i punktów w linii, tym wyższa jakość obrazu. Komputery PC używają głównie następujących rozdzielczości ekranu: 640 na 480, 800 na 600, 1024 na 768 i 1280 na 1024 pikseli.Ponieważ jasność każdego punktu i jego współrzędne liniowe można wyrazić za pomocą liczb całkowitych, można powiedzieć, że ta metoda kodowania pozwala na użycie kodu binarnego do przetwarzania danych graficznych.
Jeśli mówimy o ilustracjach czarno-białych, to jeśli nie używamy półtonów, piksel przyjmie jeden z dwóch stanów: świeci (biały) i nie świeci (czarny). A ponieważ informacja o kolorze piksela nazywana jest kodem piksela, wystarczy jeden bit pamięci, aby ją zakodować: 0 - czarny, 1 - biały. Jeśli ilustracje rozpatrywać w postaci kombinacji kropek o 256 odcieniach szarości (czyli są one obecnie powszechnie akceptowane), to wystarczy ośmiobitowa liczba binarna, aby zakodować jasność dowolnej kropki. V Grafika komputerowa kolor jest niezwykle ważny. Działa jako środek wzmacniający wrażenie wizualne i zwiększający nasycenie informacyjne obrazu. Jak w ludzkim mózgu powstaje poczucie koloru? Dzieje się tak w wyniku analizy strumienia światła wchodzącego do siatkówki z obiektów odbijających lub emitujących. Powszechnie przyjmuje się, że ludzkie receptory kolorów, zwane również czopkami, dzielą się na trzy grupy, z których każda może postrzegać tylko jeden kolor - czerwony, zielony lub niebieski.
Modele kolorystyczne
Jeśli chodzi o kolor kodowania obrazy graficzne, musisz wziąć pod uwagę zasadę rozkładu dowolnego koloru na jego główne składniki. Stosowanych jest kilka systemów kodowania: HSB, RGB i CMYK. Pierwszy model kolorystyczny jest prosty i intuicyjny, czyli wygodny dla człowieka, drugi najwygodniejszy dla komputera, a ostatni model CMYK dla drukarni. Zastosowanie tych modeli kolorystycznych wynika z faktu, że strumień świetlny może być tworzony przez promieniowanie, które jest kombinacją „czystych” barw widmowych: czerwonego, zielonego, niebieskiego lub ich pochodnych. Rozróżnij addytywne odwzorowanie kolorów (typowe dla obiektów emitujących) i subtraktywne odwzorowanie kolorów (typowe dla obiektów odbijających światło). Przykładem przedmiotu pierwszego typu jest lampa elektronopromieniowa monitora, drugiego typu - odbitka.

Model HSB charakteryzuje się trzema komponentami: Barwa, Nasycenie i Jasność. Możesz uzyskać wiele dowolnych kolorów, dostosowując te komponenty. Ten model kolorystyczny najlepiej sprawdza się w tych edytory graficzne, w którym obrazy są tworzone same, a nie przetworzone już gotowe. Następnie utworzoną kompozycję można przekonwertować na model kolorów RGB, jeśli ma być wykorzystana jako ilustracja na ekranie lub CMYK, jeśli jest drukowana.Wartość koloru jest wybierana jako wektor wychodzący ze środka okręgu. Kierunek wektora jest określony w stopniach kątowych i określa odcień. Nasycenie koloru określa długość wektora, a jasność koloru ustawia się na osobnej osi, której punktem zerowym jest czerń. Punkt środkowy jest biały (neutralny), a punkty na obwodzie mają kolor jednolity.
Zasada metody RGB jest następująca: wiadomo, że każdy kolor można przedstawić jako kombinację trzech kolorów: czerwonego (czerwonego, R), zielonego (zielony, G), niebieskiego (niebieskiego, B). Inne kolory i ich odcienie uzyskuje się dzięki obecności lub braku tych składników.Od pierwszych liter kolorów podstawowych system otrzymał swoją nazwę - RGB. Ten model kolorystyczny jest addytywny, tzn. dowolny kolor można uzyskać przez kombinację kolorów podstawowych w różnych proporcjach. Kiedy jeden składnik koloru podstawowego nakłada się na drugi, zwiększa się jasność całkowitego promieniowania. Jeśli połączymy wszystkie trzy składniki, otrzymamy achromatyczny szary kolor, ze wzrostem jasności, którego dochodzi do podejścia do bieli.
Przy 256 tonach (każdy punkt jest zakodowany po 3 bajty), minimalne wartości RGB (0,0,0) odpowiadają czerni, a biel - maksimum ze współrzędnymi (255, 255, 255). Im większa wartość bajtu składnika koloru, tym jaśniejszy kolor. Na przykład ciemnoniebieski jest zakodowany trzema bajtami (0, 0, 128) i jasnoniebieskim (0, 0, 255).
Zasada metody CMYK. Ten model kolorystyczny wykorzystywany jest podczas przygotowywania publikacji do druku. Każdemu z kolorów podstawowych przypisany jest kolor uzupełniający (uzupełniający kolor podstawowy biały). Dodatkowy kolor uzyskuje się poprzez zsumowanie pary pozostałych kolorów podstawowych. Oznacza to, że kolory uzupełniające dla czerwonego to cyjan (Cyan, C) = zielony + niebieski = biały - czerwony, dla zielonego - magenta (Magenta, M) = czerwony + niebieski = biały - zielony, dla niebiesko - żółty (Yellow, Y) = czerwony + zielony = biały - niebieski. Co więcej, zasadę rozkładu dowolnego koloru na składniki można zastosować zarówno dla głównego, jak i dodatkowego, to znaczy, że dowolny kolor można przedstawić jako sumę składnika czerwonego, zielonego, niebieskiego lub jako sumę składnik cyjan, fioletowy, żółty. Zasadniczo ta metoda jest stosowana w przemyśle poligraficznym. Ale tam nadal używają koloru czarnego (czarny, ponieważ litera B jest już zajęta przez kolor niebieski, jest oznaczona literą K). Dzieje się tak, ponieważ nakładanie kolorów dopełniających nie daje czystej czerni.
Obrazy wektorowe i fraktalne
Obraz wektorowy to obiekt graficzny składający się z podstawowych linii i łuków. Podstawowym elementem obrazu jest linia. Jak każdy obiekt posiada właściwości: kształt (prosty, krzywa), grubość., kolor, styl (kropkowany, pełny). Linie zamknięte mają właściwość wypełnienia (albo innymi obiektami, albo wybranym kolorem). Wszystkie inne obiekty Grafika wektorowa składa się z linii. Ponieważ linia jest opisana matematycznie jako pojedynczy obiekt, ilość danych do wyświetlenia obiektu za pomocą grafiki wektorowej jest znacznie mniejsza niż w grafice rastrowej. Informacje o obrazie wektorowym są kodowane jako normalne alfanumeryczne i przetwarzane przez specjalne programy.
DO oprogramowanie tworzenie i przetwarzanie grafiki wektorowej obejmuje następujące GR: CorelDraw, Adobe Illustrator, a także wektoryzatory (tracer) - specjalistyczne pakiety do konwersji obrazów rastrowych na wektorowe.

Grafika fraktalna opiera się na obliczeniach matematycznych, podobnie jak grafika wektorowa. Ale w przeciwieństwie do wektora, jego podstawowym elementem jest sama formuła matematyczna. Prowadzi to do tego, że w pamięci komputera nie są przechowywane żadne obiekty, a obraz budowany jest wyłącznie za pomocą równań. Za pomocą tej metody można budować najprostsze regularne struktury, a także złożone ilustracje imitujące krajobrazy.

Kodowanie dźwięku
Świat wypełniony jest różnorodnymi dźwiękami: tykaniem zegarów i szumem silników, wycie wiatru i szelestem liści, śpiewem ptaków i głosami ludzi. O tym, jak rodzą się dźwięki i czym są, ludzie już dawno zaczęli się domyślać. Nawet starożytny grecki filozof i naukowiec – encyklopedysta Arystoteles, na podstawie obserwacji, wyjaśniał naturę dźwięku, wierząc, że ciało sondujące powoduje naprzemienną kompresję i rozrzedzenie powietrza. Tak więc oscylująca struna czasami rozładowuje się, a następnie ściska powietrze, a dzięki elastyczności powietrza te zmienne wpływy są przenoszone dalej w przestrzeń - z warstwy na warstwę powstają fale sprężyste. Kiedy dotrą do naszego ucha, działają na bębenki uszne i wywołują wrażenie dźwięku.
Przez ucho osoba odbiera fale sprężyste o częstotliwości gdzieś w zakresie od 16 Hz do 20 kHz (1 Hz - 1 wibracja na sekundę). Zgodnie z tym fale sprężyste w dowolnym ośrodku, których częstotliwości mieszczą się w określonych granicach, nazywane są falami dźwiękowymi lub po prostu dźwiękiem. W badaniu dźwięku ważne są pojęcia takie jak ton i barwa dźwięku. Każdy prawdziwy dźwięk, czy to gra na instrumentach muzycznych, czy głos człowieka, jest rodzajem mieszanki wielu wibracji harmonicznych o określonym zestawie częstotliwości.
To chybotanie, które ma najwięcej niska częstotliwość, nazywane są tonem głównym, inne nazywane są alikwotami.
Barwa to inna liczba alikwotów tkwiących w danym dźwięku, co nadaje mu szczególną barwę. Różnica między jedną barwą a drugą wynika nie tylko z liczby, ale także z intensywności alikwotów towarzyszących brzmieniu tonu głównego. To dzięki barwie możemy łatwo odróżnić dźwięki pianina i skrzypiec, gitary i fletu oraz rozpoznać głos znajomej osoby.
Dźwięk muzyczny może charakteryzować się trzema cechami: barwą, czyli barwą dźwięku, która zależy od kształtu drgań, wysokością, która określana jest liczbą drgań na sekundę (częstotliwością) oraz głośnością, która zależy od intensywności wibracji.
Komputer jest obecnie szeroko stosowany w różnych dziedzinach. Przetwarzanie informacji dźwiękowych i muzyki nie było wyjątkiem. Do 1983 roku wszystkie nagrania muzyczne były wydawane na płytach winylowych i kasetach kompaktowych. Obecnie płyty CD są szeroko stosowane. Jeśli masz komputer, na którym zainstalowana jest studyjna karta dźwiękowa, z podłączoną do niego klawiaturą MIDI i mikrofonem, możesz pracować ze specjalistycznym oprogramowaniem muzycznym.
Konwersja cyfrowo-analogowa i analogowo-cyfrowa informacji audio
Rzućmy okiem na procesy konwersji dźwięku z analogowego na cyfrowy i odwrotnie. Zgrubne wyobrażenie o tym, co dzieje się na karcie dźwiękowej, może pomóc uniknąć błędów podczas pracy z dźwiękiem.
Fale dźwiękowe są przekształcane na analogowy zmienny sygnał elektryczny za pomocą mikrofonu. Przechodzi przez tor audio do przetwornika analogowo-cyfrowego (ADC) – urządzenia, które zamienia sygnał na postać cyfrową.
W uproszczeniu zasada działania ADC jest następująca: mierzy on amplitudę sygnału w regularnych odstępach czasu i przesyła dalej, już drogą cyfrową, ciąg liczb niosących informacje o zmianach amplitudy. Podczas konwersji analogowo-cyfrowej nie następuje fizyczna konwersja. Z sygnału elektrycznego pobierany jest niejako odcisk lub próbka, która jest cyfrowym modelem wahań napięcia w torze audio. Jeżeli jest to zobrazowane w formie diagramu, to model ten jest przedstawiony w postaci ciągu kolumn, z których każda odpowiada określonej wartości liczbowej. Sygnał cyfrowy ma charakter dyskretny - to znaczy nieciągły, więc model cyfrowy nie jest dokładnie dopasowany do kształtu fali sygnału analogowego.
Próbka to odstęp czasu między dwoma pomiarami amplitudy sygnału analogowego.
Próbka dosłownie tłumaczy się z angielskiego jako „próbka”. W terminologii multimedialnej i profesjonalnej audio słowo to ma kilka znaczeń. Oprócz okresu czasu próbka jest również nazywana dowolną sekwencją danych cyfrowych, która jest uzyskiwana przez konwersję analogowo-cyfrową. Sam proces konwersji nazywa się próbkowaniem. W rosyjskim języku technicznym nazywa się to dyskretyzacją.
Dźwięk cyfrowy jest wyprowadzany za pomocą przetwornika cyfrowo-analogowego (DAC), który na podstawie przychodzących danych cyfrowych w odpowiednich momentach generuje sygnał elektryczny o wymaganej amplitudzie
Opcje próbkowania
Ważnymi parametrami próbkowania są częstotliwość i głębia bitowa. Częstotliwość - liczba pomiarów amplitudy sygnału analogowego na sekundę.
Jeśli częstotliwość próbkowania nie jest większa niż dwukrotność częstotliwości górnej granicy zakresu dźwięku, to włącz wysokie częstotliwości wystąpią straty. To wyjaśnia, dlaczego standardowa częstotliwość audio CD wynosi 44,1 kHz. Ponieważ zakres oscylacji fal dźwiękowych mieści się w zakresie od 20 Hz do 20 kHz, liczba pomiarów sygnału na sekundę powinna być większa niż liczba oscylacji w tym samym okresie czasu. Jeżeli częstotliwość próbkowania jest znacznie niższa niż częstotliwość fali dźwiękowej, to amplituda sygnału ma czas na kilkukrotną zmianę w czasie między pomiarami, a to prowadzi do tego, że cyfrowy odcisk palca niesie chaotyczny zbiór danych. Przy konwersji cyfrowo-analogowej taka próbka nie przesyła głównego sygnału, a jedynie wytwarza szum.
W nowym formacie CD Audio DVD sygnał jest mierzony 96 000 razy w ciągu jednej sekundy. użyj częstotliwości próbkowania 96 kHz. Aby zaoszczędzić miejsce na dysku twardym w aplikacjach multimedialnych, często stosuje się niższe częstotliwości: 11, 22, 32 kHz. Prowadzi to do zmniejszenia słyszalnego zakresu częstotliwości, co oznacza silne zniekształcenie tego, co jest słyszane.
Jeśli w formie wykresu przedstawiamy ten sam dźwięk o wysokości 1 kHz (do siódmej oktawy fortepianu z grubsza odpowiada tej częstotliwości), ale próbkowany z inną częstotliwością (dolna część sinusoidy to nie pokazane na wszystkich wykresach), wtedy różnice będą widoczne. Jeden podział na osi poziomej, która pokazuje czas, odpowiada 10 próbkom. Skala jest taka sama. Widać, że przy częstotliwości 11 kHz na każde 50 próbek przypada około pięciu oscylacji fali dźwiękowej, czyli jeden okres fali sinusoidalnej jest wyświetlany przy użyciu tylko 10 wartości. To raczej nieprecyzyjna transmisja. Jednocześnie, jeśli weźmiemy pod uwagę częstotliwość próbkowania 44 kHz, to dla każdego okresu sinusoidy jest już prawie 50 próbek. Pozwala to uzyskać sygnał dobrej jakości.
Głębia bitowa wskazuje dokładność, z jaką zmienia się amplituda sygnału analogowego. Dokładność, z jaką wartość amplitudy sygnału w każdym momencie jest przesyłana podczas digitalizacji, określa jakość sygnału po konwersji cyfrowo-analogowej. Dokładność rekonstrukcji przebiegu zależy od głębokości bitowej.
Wartość amplitudy jest kodowana przy użyciu zasady kodowania binarnego. Sygnał dźwiękowy powinien być przedstawiony jako ciąg impulsów elektrycznych (binarne zera i jedynek). Zazwyczaj używane są 8, 16 lub 20-bitowe reprezentacje wartości amplitudy. Gdy kodowanie binarne ciągłe sygnał dźwiękowy zastępuje go sekwencja dyskretnych poziomów sygnału. Jakość kodowania zależy od częstotliwości próbkowania (liczby pomiarów poziomu sygnału na jednostkę czasu). Wraz ze wzrostem częstotliwości próbkowania wzrasta dokładność binarnej reprezentacji informacji. Przy częstotliwości 8 kHz (liczba pomiarów na sekundę to 8000) jakość próbkowanego sygnału dźwiękowego odpowiada jakości transmisji radiowej, a przy częstotliwości 48 kHz (liczba pomiarów na sekundę to 48000) - jakość dźwięku płyty audio CD.
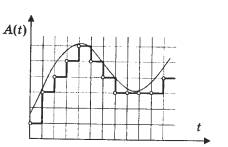
Obecnie istnieje nowy konsumencki format cyfrowy Audio DVD, który wykorzystuje częstotliwość próbkowania 24-bitową i 96 kHz. Z jego pomocą można uniknąć wspomnianej wcześniej wady kodowania 16-bitowego.
Do nowoczesnego cyfrowego urządzenia dźwiękowe Zainstalowane są konwertery 20-bitowe. Dźwięk pozostaje 16-bitowy, zainstalowano konwertery o zwiększonej głębi bitowej, aby poprawić jakość nagrania na niskich poziomach. Ich zasada działania jest następująca: oryginalny sygnał analogowy jest digitalizowany z szerokością 20 bitów. Następnie cyfrowy procesor sygnału DSPP zmniejsza swoją szerokość do 16 bitów. W takim przypadku stosowany jest specjalny algorytm obliczeniowy, za pomocą którego można zmniejszyć zniekształcenia sygnałów niskiego poziomu. Odwrotny proces obserwuje się podczas konwersji cyfrowo-analogowej: głębia bitowa wzrasta z 16 do 20 bitów za pomocą specjalnego algorytmu, który pozwala dokładniej określić wartości amplitudy. Oznacza to, że dźwięk pozostaje 16-bitowy, ale ogólnie poprawia się jakość dźwięku.
Co to jest kodowanie
W języku rosyjskim „zestaw znaków” jest również nazywany tabelą „zestawu znaków”, a proces używania tej tabeli do tłumaczenia informacji z reprezentacji komputerowej na ludzką, a także charakterystyka pliku tekstowego, która odzwierciedla użycie pewnego system kodów w nim podczas wyświetlania tekstu.
Jak kodowany jest tekst
Zbiór symboli używanych w pisaniu tekstu nazywany jest alfabetem w terminologii komputerowej; liczba symboli w alfabecie jest zwykle nazywana jego mocą. Do prezentacji informacje tekstowe komputer najczęściej używa alfabetu o pojemności 256 znaków. Jeden z jego znaków zawiera 8 bitów informacji, dlatego kod binarny każdego znaku zajmuje 1 bajt pamięci komputera. Wszystkie znaki takiego alfabetu są ponumerowane od 0 do 255, a każda liczba odpowiada 8-bitowemu kodowi binarnemu, który jest liczbą porządkową znaku w systemie notacji binarnej - od 00000000 do 11111111. Tylko pierwsze 128 znaków z liczby od zera (kod binarny 00000000) do 127 (01111111). Należą do nich małe litery i wielkie litery Alfabet łaciński, cyfry, znaki interpunkcyjne, nawiasy itp. Pozostałe 128 kodów, zaczynając od 128 (kod binarny 10000000) a kończąc na 255 (11111111) służy do kodowania liter alfabetów narodowych, symboli usługowych i naukowych.
Rodzaje kodowań
Najbardziej znaną tabelą kodowania jest ASCII (American Standard Code for Information Interchange). Pierwotnie został opracowany do przesyłania tekstów za pomocą telegrafu, a w tym czasie był 7-bitowy, czyli do kodowania znaków angielskich, znaków serwisowych i kontrolnych użyto tylko 128 7-bitowych kombinacji. W tym przypadku pierwsze 32 kombinacje (kody) służyły do kodowania sygnałów sterujących (początek tekstu, koniec wiersza, powrót karetki, wywołanie, koniec tekstu itp.). W rozwoju pierwszych komputerów IBM ten kod był używany do reprezentowania symboli w komputerze. Ponieważ w kod źródłowy ASCII miał tylko 128 znaków, do ich zakodowania wystarczyły wartości bajtowe, w których 8 bit to 0. Angielski (greckie, niemieckie umlauty, francuskie znaki diakrytyczne itp.). Kiedy komputery zaczęły dostosowywać się do innych krajów i języków, nie było już miejsca na nowe symbole. Aby w pełni obsługiwać języki inne niż angielski, IBM wprowadził kilka tabel kodów dla poszczególnych krajów. Tak więc dla krajów skandynawskich zaproponowano tabelę 865 (nordycką), dla krajów arabskich - tabelę 864 (arabską), dla Izraela - tabelę 862 (Izrael) i tak dalej. W tych tabelach część kodów z drugiej połowy tabeli kodów została wykorzystana do reprezentacji znaków alfabetów narodowych (pomijając niektóre znaki pseudograficzne). W szczególny sposób rozwinęła się sytuacja z językiem rosyjskim. Oczywiście można dokonać zamiany znaków w drugiej połowie tabeli kodów różne sposoby... Pojawiło się więc kilka różnych tabel kodowania znaków cyrylicy dla języka rosyjskiego: KOI8-R, IBM-866, CP-1251, ISO-8551-5. Wszystkie reprezentują symbole pierwszej połowy tabeli w ten sam sposób (od 0 do 127) i różnią się reprezentacją symboli alfabetu rosyjskiego i pseudografiki. W przypadku języków takich jak chiński czy japoński 256 znaków na ogół nie wystarcza. Dodatkowo zawsze pojawia się problem z wyprowadzeniem lub zapisaniem w jednym pliku tekstów jednocześnie inne języki(na przykład podczas cytowania). Dlatego uniwersalny tabela kodów UNICODE, zawierający symbole używane w językach wszystkich narodów świata, a także różne symbole służbowe i pomocnicze (znaki interpunkcyjne, symbole matematyczne i techniczne, strzałki, znaki diakrytyczne itp.). Oczywiście jeden bajt nie wystarczy do zakodowania tak dużej liczby znaków. Dlatego UNICODE używa 16-bitowych (2-bajtowych) kodów do reprezentacji 65 536 znaków. Do tej pory wykorzystano około 49 000 kodów (ostatnią istotną zmianą było wprowadzenie symbolu waluty EURO we wrześniu 1998 roku). Aby zapewnić zgodność z poprzednimi kodowaniami, pierwsze 256 kodów jest takich samych jak w standardzie ASCII. W standardzie UNICODE, oprócz pewnego kodu binarnego (kody te są zwykle oznaczane literą U, po której następuje znak + i rzeczywisty kod w reprezentacji szesnastkowej), każdemu znakowi przypisywana jest określona nazwa. Kolejny składnik Standard UNICODE to algorytmy konwersji jeden do jednego kodów UNICODE w sekwencji bajtów o zmiennej długości. Potrzeba takich algorytmów wynika z faktu, że nie wszystkie aplikacje mogą pracować z UNICODE. Niektóre aplikacje rozumieją tylko 7-bitowe kody ASCII, inne aplikacje rozumieją 8-bitowe kody ASCII. Takie aplikacje używają tak zwanych rozszerzonych kodów ASCII do reprezentowania znaków, które nie mieszczą się odpowiednio w zestawie 128 znaków lub 256 znaków, gdy znaki są zakodowane za pomocą ciągów bajtów o zmiennej długości. UTF-7 służy do odwracalnej konwersji kodów UNICODE na rozszerzone 7-bitowe kody ASCII, a UTF-8 służy do odwracalnej konwersji kodów UNICODE na rozszerzone 8-bitowe kody ASCII. Należy zauważyć, że zarówno ASCII, jak i UNICODE oraz inne standardy kodowania znaków nie definiują obrazów znaków, a jedynie skład zestawu znaków i sposób jego reprezentacji na komputerze. Dodatkowo (co może nie być od razu oczywiste) bardzo ważna jest kolejność wyliczania znaków w zbiorze, ponieważ w najbardziej znaczący sposób wpływa ona na algorytmy sortowania. Jest to tabela korespondencji symboli z pewnego zbioru (powiedzmy, symbole używane do reprezentowania informacji o język angielski, lub w różnych językach, jak w przypadku UNICODE) i określają termin tablica kodowania znaków lub zestaw znaków. Każde standardowe kodowanie ma nazwę, na przykład KOI8-R, ISO_8859-1, ASCII. Niestety nie ma standardu kodowania nazw.
Wspólne kodowania
ISO 646 o ASCII EBCDIC ISO 8859: o ISO 8859-1 - ISO 8859-11, ISO 8859-13, ISO 8859-14, ISO 8859-15 o CP437, CP737, CP850, CP852, CP855, CP857, CP858, CP860, CP861, CP863, CP865, CP866, CP869 Kodowanie Microsoft Windows: Windows-1250 dla języków środkowoeuropejskich używających liter łacińskich Windows-1251 dla cyrylicy Windows-1252 dla języków zachodnich Windows-1253 dla języka greckiego Windows-1254 dla tureckiego o Windows-1255 dla hebrajskiego o Windows-1256 dla arabskiego o Windows-1257 dla języków bałtyckich o Windows-1258 dla wietnamskiego MacRoman, MacCyrillic KOI8 (KOI8-R, KOI8-U...), KOI -7 Bułgarskie kodowanie ISCII VISCII Big5 (najsłynniejszy wariant Microsoft CP950) o HKSCS Guobiao o GB2312 o GBK (Microsoft CP936) o GB18030 Shift JIS dla języka japońskiego (Microsoft CP932) EUC-KR dla języka koreańskiego (Microsoft CP949) ISO-2022 i EUC dla chińskiego pisania kodowania UTF-8 i UTF-16 zestawu znaków Yong ikodW systemie kodowania ASCII(American Standard Code for Information Interchange) każdy znak jest reprezentowany przez jeden bajt, który może zakodować 256 znaków.
ASCII ma dwie tabele kodowania - podstawową i rozszerzoną. Tabela podstawowa ustala wartości kodów od 0 do 127, a rozszerzona odnosi się do znaków o liczbach od 128 do 255. To wystarczy, aby wyrazić różnymi kombinacjami ośmiu bitów wszystkie znaki języka angielskiego i rosyjskiego , zarówno małe, jak i wielkie litery, a także znaki interpunkcyjne, symbole podstawowych operacji arytmetycznych i typowe symbole specjalne, które można zaobserwować na klawiaturze.
Pierwsze 32 kody tabeli bazowej, zaczynając od zera, są przekazywane producentom sprzętu (przede wszystkim producentom komputerów i urządzeń drukujących). Obszar ten zawiera tak zwane kody kontrolne, które nie odpowiadają żadnym znakom językowym, a zatem kody te nie są wyświetlane ani na ekranie ani na urządzeniach drukujących, ale można nimi sterować sposobem wyprowadzania innych danych. Począwszy od kodu 32 do kodu 127, umieszczane są symbole alfabetu angielskiego, znaki interpunkcyjne, cyfry, operacje arytmetyczne i symbole pomocnicze, wszystkie widoczne na łacińskiej części klawiatury komputera.
Druga, rozszerzona część poświęcona jest krajowym systemom kodowania. Na świecie istnieje wiele niełacińskich alfabetów (arabski, hebrajski, grecki itd.), w tym cyrylica. Również układy klawiatury niemieckiej, francuskiej i hiszpańskiej różnią się od angielskich.
Angielska część klawiatury miała wiele standardów, ale teraz wszystkie zostały zastąpione jednym kodem ASCII. W przypadku klawiatury rosyjskiej istniało również wiele standardów: GOST, GOST-alternatywa, ISO (Międzynarodowa Organizacja Normalizacyjna - Międzynarodowy Instytut Normalizacyjny), ale te trzy standardy faktycznie wymarły, chociaż mogą się gdzieś spotkać, w niektórych przedpotopowych komputerach lub w sieci komputerowe.
Główne kodowanie znaków języka rosyjskiego, które jest używane w komputerach z systemem operacyjnym System Windows nazywa Okna-1251, został opracowany dla alfabetów cyrylicy przez firmę Microsoft. Oczywiście bezwzględna większość komputerowych danych tekstowych jest zakodowana w systemie Windows-1251. Nawiasem mówiąc, kodowanie o innej czterocyfrowej liczbie zostało opracowane przez Microsoft dla innych popularnych alfabetów: arabskiego, japońskiego i innych.
Innym popularnym kodowaniem jest KOI-8(kod wymiany informacji, ośmiocyfrowy) – jego geneza sięga czasów Rady Wzajemnej Pomocy Gospodarczej Państw Europy Wschodniej. Obecnie kodowanie KOI-8 jest szeroko rozpowszechnione w sieciach komputerowych na terenie Rosji oraz w rosyjskim sektorze Internetu. Zdarza się, że jakiś tekst listu lub coś innego nie jest czytelny, co oznacza, że trzeba przełączyć się z KOI-8 na Windows-1251. dziesięć
W latach 90. najwięksi producenci oprogramowania: Microsoft, Borland, ten sam Adobe zdecydowali się na opracowanie innego systemu kodowania tekstu, w którym każdemu znakowi przydzielone zostaną nie 1, a 2 bajty. Ma imię Unicode, a możliwe jest zakodowanie 65 536 znaków tego pola wystarczy, aby zmieścić się w jednej tabeli alfabetów narodowych dla wszystkich języków planety. Większość Unicode (około 70%) zajmują chińskie znaki, w Indiach istnieje 11 różnych alfabetów narodowych, istnieje wiele egzotycznych nazw, na przykład: pismo kanadyjskich aborygenów.
Ponieważ kodowanie każdego znaku w Unicode jest przydzielane nie 8, ale 16 bitów, rozmiar pliku tekstowego jest podwojony. To było kiedyś przeszkodą we wprowadzeniu systemu 16-bitowego. a teraz przy gigabajtowych dyskach twardych, setkach megabajtów pamięci RAM, gigahercowych procesorach, podwojeniu rozmiaru plików tekstowych, które w porównaniu np. z grafiką zajmują bardzo mało miejsca, nie ma to większego znaczenia.
Alfabet cyrylicy w Unicode wynosi od 768 do 923 (znaki podstawowe) i od 924 do 1023 (cyrylica rozszerzona, różne mniej popularne litery narodowe). Jeśli program nie jest przystosowany do cyrylicy Unicode, możliwe jest, że znaki tekstowe są rozpoznawane nie jako cyrylica, ale jako rozszerzona łacina (kody od 256 do 511). I w tym przypadku zamiast tekstu na ekranie pojawia się bezsensowny zestaw różnych egzotycznych symboli.
Jest to możliwe, jeśli program jest nieaktualny, stworzony przed 1995 rokiem. Albo rzadki, o który nikt nie zawracał sobie głowy rusyfikacją. Możliwe jest również, że system operacyjny Windows zainstalowany na komputerze nie jest w pełni skonfigurowany dla cyrylicy. W takim przypadku musisz dokonać odpowiednich wpisów w rejestrze.
 Który jest lepszy iPhone 6s czy 6 plus
Który jest lepszy iPhone 6s czy 6 plus Gdzie są zrzuty ekranu i gry w folderze Steam?
Gdzie są zrzuty ekranu i gry w folderze Steam? Jak usunąć lub przywrócić wszystkie usunięte okna dialogowe VKontakte naraz?
Jak usunąć lub przywrócić wszystkie usunięte okna dialogowe VKontakte naraz?