Quanti bit vengono utilizzati per codificare 1 carattere in unicode. Codifica del testo
A partire dalla fine degli anni '60, i computer furono sempre più utilizzati per elaborare informazioni di testo e attualmente la maggior parte computer personale nel mondo (e la maggior parte delle volte) è impegnato nell'elaborazione di informazioni testuali.
ASCII - codifica del testo di base per l'alfabeto latino
Tradizionalmente, per codificare un carattere, viene utilizzata una quantità di informazioni pari a 1 byte, ovvero I = 1 byte = 8 bit.
Per codificare un carattere, è necessario 1 byte di informazioni. Se consideriamo i simboli come possibili eventi, allora possiamo calcolare quanti personaggi diversi può essere codificato: N = 2I = 28 = 256.
Questo numero di caratteri è abbastanza per rappresentare le informazioni testuali, comprese le lettere maiuscole e minuscole degli alfabeti russi e latini, numeri, segni, simboli grafici, ecc. Codice binario da 00000000 a 11111111.
Pertanto, una persona distingue i personaggi per il loro stile e un computer per i loro codici. Quando le informazioni di testo vengono immesse in un computer, si verifica la sua codifica binaria, l'immagine di un simbolo viene convertita nel suo codice binario.
L'utente preme un tasto con un simbolo sulla tastiera e una specifica sequenza di otto impulsi elettrici (codice binario del simbolo) viene inviata al computer. Il codice carattere è memorizzato in memoria ad accesso casuale computer dove occupa un byte. Nel processo di visualizzazione di un carattere sullo schermo del computer, viene eseguito il processo inverso: la decodifica, ovvero la conversione del codice del carattere nella sua immagine. Come standard internazionale è stata adottata la tabella dei codici ASCII (American Standard Code for Information Interchange). . I primi 33 codici (da 0 a 32) non corrispondono a caratteri, ma a operazioni (avanzamento riga, inserimento spazio, ecc.). I codici da 33 a 127 sono internazionali e corrispondono a simboli dell'alfabeto latino, numeri, segni aritmetici e segni di punteggiatura. I codici da 128 a 255 sono nazionali, cioè caratteri diversi corrispondono allo stesso codice nelle codifiche nazionali.
Sfortunatamente, attualmente ci sono cinque diverse tabelle di codici per le lettere russe (KOI8, CP1251, CP866, Mac, ISO), quindi i testi creati in una codifica non verranno visualizzati correttamente in un'altra.
Attualmente, un nuovo internazionale Standard Unicode, che alloca non un byte per ogni carattere, ma due, quindi può essere usato per codificare non 256 caratteri, ma N = 216 = 65536 diversi
Unicode: l'emergere della codifica universale del testo (UTF 32, UTF 16 e UTF 8)
Queste migliaia di caratteri del gruppo linguistico del sud-est asiatico non possono essere descritti in un singolo byte di informazioni, che è stato allocato per la codifica dei caratteri nelle codifiche ASCII estese. Di conseguenza, un consorzio chiamato Unicode(Unicode - Unicode Consortium) con la collaborazione di molti leader del settore IT (chi produce software, chi codifica hardware, chi crea font), interessati all'emergere di una codifica universale del testo.
La prima codifica di testo pubblicata sotto gli auspici del consorzio Unicode è stata la codifica UTF 32... Il numero nel nome della codifica UTF 32 indica il numero di bit utilizzati per codificare un carattere. 32 bit sono 4 byte di informazioni che saranno necessarie per codificare un singolo carattere nella nuova codifica universale UTF 32.
Di conseguenza, lo stesso file con testo codificato nella codifica ASCII estesa e nella codifica UTF 32, in quest'ultimo caso, avrà dimensioni (peso) quattro volte superiori. Questo è un male, ma ora abbiamo l'opportunità di codificare usando UTF 32 il numero di caratteri pari a due alla potenza di trenta secondi (miliardi di caratteri che copriranno qualsiasi valore veramente necessario con un margine colossale).
Ma molti paesi con lingue del gruppo europeo non avevano affatto bisogno di utilizzare un numero così elevato di caratteri nella codifica, tuttavia, quando si utilizzava UTF 32, hanno ricevuto un aumento di peso di quattro volte per niente. documenti di testo e, di conseguenza, un aumento del volume del traffico Internet e della quantità di dati archiviati. Questo è molto e nessuno potrebbe permettersi un tale spreco.
Come risultato dello sviluppo di un universale La codifica Unicode è apparsa UTF 16, che si è rivelato un tale successo che è stato accettato per impostazione predefinita come spazio di base per tutti i simboli che utilizziamo. UTF 16 utilizza due byte per codificare un carattere. Ad esempio, in sala operatoria Sistema Windows puoi seguire il percorso Start - Programmi - Accessori - Strumenti di sistema - Tabella dei simboli.
Di conseguenza, si aprirà una tabella con le forme vettoriali di tutti i caratteri installati nel sistema. Se selezioni il set di caratteri Unicode nelle Opzioni avanzate, puoi vedere separatamente per ogni font l'intera gamma di caratteri inclusi in esso. A proposito, facendo clic su uno di questi caratteri, puoi vedere il suo codice a due byte nella codifica UTF 16, composto da quattro cifre esadecimali:
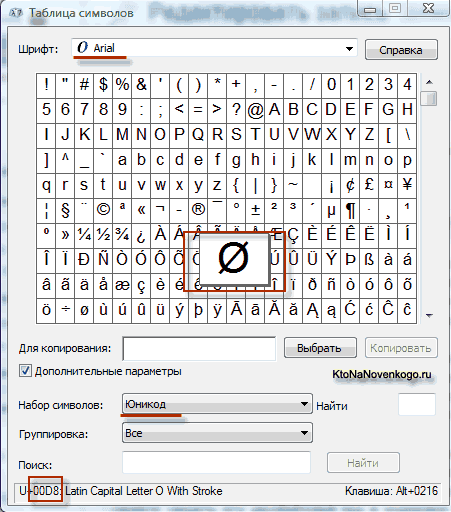
Quanti caratteri possono essere codificati in UTF 16 con 16 bit? 65.536 caratteri (due alla potenza di sedici) sono stati presi come spazio di base in Unicode. Inoltre, ci sono modi per codificare con UTF 16 circa due milioni di caratteri, ma erano limitati allo spazio esteso di un milione di caratteri di testo.
Ma anche una versione di successo della codifica Unicode chiamata UTF 16 non ha portato molte soddisfazioni a coloro che hanno scritto, ad esempio, programmi solo in lingua inglese, perché dopo il passaggio dalla versione estesa della codifica ASCII a UTF 16, il peso dei documenti è raddoppiato (un byte per un carattere in ASCII e due byte per lo stesso carattere in codifica UTF 16). È stato proprio per la soddisfazione di tutti e di tutto nel consorzio Unicode che si è deciso di inventare codifica del testo a lunghezza variabile.
Questa codifica in Unicode è stata chiamata UTF 8... Nonostante gli otto nel nome, UTF 8 è una codifica a lunghezza variabile a tutti gli effetti, ad es. ogni carattere del testo può essere codificato in una sequenza da uno a sei byte. In pratica, in UTF 8, viene utilizzato solo l'intervallo da uno a quattro byte, perché oltre i quattro byte di codice, non è nemmeno teoricamente possibile immaginare.
In UTF 8, tutti i caratteri latini sono codificati in un byte, proprio come nella vecchia codifica ASCII. Ciò che è degno di nota, nel caso della codifica solo dell'alfabeto latino, anche quei programmi che non comprendono Unicode leggeranno comunque ciò che è codificato in UTF 8. Cioè, la parte di base della codifica ASCII è stata spostata in UTF 8.
Caratteri cirillici in UTF 8 sono codificati in due byte e, ad esempio, quelli georgiani in tre byte. Dopo la creazione delle codifiche UTF 16 e UTF 8, il Consorzio Unicode ha risolto il problema principale: ora abbiamo un unico spazio di codice nei nostri caratteri. L'unica cosa rimasta ai produttori di font è riempire questo spazio di codice con forme vettoriali di simboli di testo in base ai loro punti di forza e capacità.
In teoria, esiste da tempo una soluzione a questi problemi. È chiamato Unicode UnicodeÈ una tabella di codifica in cui vengono utilizzati 2 byte per codificare ciascun carattere, ad es. 16 bit. Sulla base di tale tabella, è possibile codificare N = 2 16 = 65 536 caratteri.
Unicode include quasi tutte le scritture moderne, tra cui: arabo, armeno, bengalese, birmano, greco, georgiano, devanagari, ebraico, cirillico, copto, khmer, latino, tamil, hangul, han (Cina, Giappone, Corea), cherokee, etiope, giapponese (Katakana, Hiragana, Kanji) e altri.
Per scopi accademici, sono state aggiunte molte scritture storiche, tra cui: greco antico, geroglifici egizi, cuneiforme, scrittura Maya, alfabeto etrusco.
Unicode offre un'ampia gamma di simboli e pittogrammi matematici e musicali.
Per i caratteri cirillici in Unicode, vengono assegnati due intervalli di codici:
Cirillico (# 0400 - # 04FF)
Supplemento cirillico (# 0500 - # 052F).
Ma iniezione da tavolo Unicode nella sua forma pura è limitato per il motivo che se il codice di un carattere non occuperà un byte, ma due byte, ci vorrà il doppio dello spazio su disco per memorizzare il testo e il doppio del tempo per trasferirlo tramite comunicazione canali.
Pertanto, in pratica, la rappresentazione Unicode di UTF-8 (Unicode Transformation Format) è ora più comune. UTF-8 offre la migliore compatibilità con i sistemi che utilizzano caratteri a 8 bit. Il testo contenente solo caratteri con un numero inferiore a 128 viene convertito in testo ASCII semplice quando scritto in UTF-8. Il resto dei caratteri Unicode è rappresentato da sequenze da 2 a 4 byte di lunghezza. In generale, poiché i caratteri più comuni al mondo - i caratteri dell'alfabeto latino - in UTF-8 occupano ancora 1 byte, questa codifica è più economica del puro Unicode.
Il testo inglese codificato utilizza solo 26 lettere dell'alfabeto latino e altri 6 caratteri di punteggiatura. In questo caso, il testo contenente 1000 caratteri può essere garantito per essere compresso senza perdita di informazioni alle dimensioni:
Il dizionario di Ellochka - "cannibali" (un personaggio del romanzo "Le dodici sedie") è di 30 parole. Quanti bit sono sufficienti per codificare l'intero vocabolario di Ellochka? Opzioni: 8, 5, 3, 1.
Unità di misura del volume di dati e della capacità di memoria: kilobyte, megabyte, gigabyte...
Quindi, abbiamo scoperto che nella maggior parte delle codifiche moderne, viene assegnato 1 byte per memorizzare un carattere del testo su supporti elettronici. Quelli. in byte, viene misurato il volume (V) occupato dai dati durante la loro memorizzazione e trasmissione (file, messaggi).
Volume dati (V) - il numero di byte necessari per memorizzarli nella memoria di un supporto dati elettronico.
La memoria multimediale, a sua volta, è limitata capacità, cioè. la capacità di contenere un certo volume. La capacità di memorizzazione dei supporti di memorizzazione elettronici, ovviamente, viene misurata anche in byte.
Tuttavia, un byte è una piccola unità di misura della quantità di dati, quelli più grandi sono kilobyte, megabyte, gigabyte, terabyte ...
Va ricordato che i prefissi "kilo", "mega", "giga" ... non sono decimali in questo caso. Quindi "kilo" nella parola "kilobyte" non significa "mille", cioè non significa "10 3". Il bit è un'unità binaria, per questo in informatica è conveniente utilizzare unità di misura che siano multipli del numero “2” anziché del numero “10”.
1 byte = 2 3 = 8 bit, 1 kilobyte = 2 10 = 1024 byte. In binario, 1 kilobyte = & 1.000.000.000 di byte.
Quelli. "Kilo" qui indica il numero più vicino a mille, che è una potenza del numero 2, ad es. che è un numero "tondo" in notazione binaria.
Tabella 10.
|
denominazione |
Designazione |
Valore in byte |
|
|
kilobyte | |||
|
megabyte |
2 10 Kb = 2 20 b | ||
|
gigabyte |
2 10 Mb = 2 30 b | ||
|
terabyte |
2 10 Gb = 2 40 b |
1.099 511 627 776 b |
|
A causa del fatto che le unità di misura del volume e della capacità dei portatori di informazioni sono multipli di 2 e non multipli di 10, la maggior parte dei problemi su questo argomento sono più facili da risolvere quando i valori che appaiono in essi sono rappresentati da potenze di 2 Considera un esempio di un tale problema e la sua soluzione:
Il file di testo contiene 400 pagine di testo. Ogni pagina contiene 3200 caratteri. Se la codifica è KOI-8 (8 bit per carattere), la dimensione del file sarà:
Soluzione
Determinare il numero totale di caratteri nel file di testo. In questo caso, rappresentiamo i numeri multipli di una potenza di 2 come una potenza di 2, ad es. invece di 4, scriviamo 2 2, ecc. La tabella 7 può essere utilizzata per determinare il grado.
caratteri.
2) In base alla condizione del problema, 1 carattere occupa 8 bit, ad es. 1 byte => il file occupa 2 7 * 10000 byte.
3) 1 kilobyte = 2 10 byte => la dimensione del file in kilobyte è:
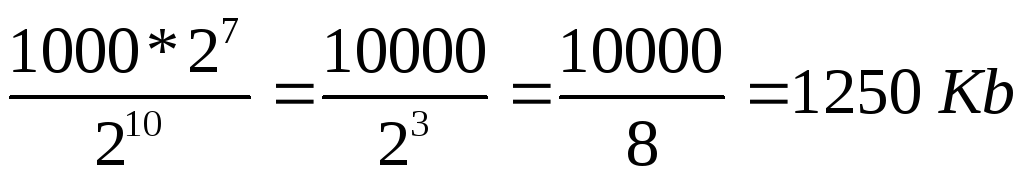 .
.
Quanti bit ci sono in un kilobyte?
&10000000000000.
Che cos'è 1 MB?
1.000.000 di byte.
1024 byte;
1024 kilobyte;
Quanti bit ci sono in un messaggio da un quarto di kilobyte? Opzioni: 250, 512, 2000, 2048.
Volume file di testo 640 Kb... Il file contiene un libro che viene digitato in media 32 righe per pagina e per 64 carattere nella stringa. Quante pagine ci sono nel libro: 160, 320, 540, 640, 1280?
Dossier sui dipendenti 8 Mb... Ognuno di loro contiene 16 pagine ( 32 linee di 64 carattere per riga). Quanti dipendenti nell'organizzazione: 256; 512; 1024; 2048?
Questo post è per coloro che non capiscono cosa sia UTF-8, ma vogliono capirlo e la documentazione disponibile spesso copre questo problema in modo molto esteso. Cercherò di descriverlo qui nel modo in cui io stesso vorrei che qualcuno me lo dicesse prima. Dato che spesso ho avuto un casino nella mia testa su UTF-8.
Poche semplici regole
- Quindi UTF-8 è un wrapper per Unicode. Non è una codifica dei caratteri separata, è racchiusa in Unicode. Probabilmente conosci la codifica Base64 o ne hai sentito parlare: può racchiudere dati binari in caratteri stampabili. Duck, UTF-8 è lo stesso Base64 per Unicode di Base64 per i dati binari. Questa volta. Se capisci questo, molto sarà già chiaro. E anche, come Base64, è riconosciuto per risolvere il problema della compatibilità in caratteri (Base64 è stato inventato per la posta elettronica, al fine di trasferire file per posta, in cui tutti i caratteri sono stampabili)
- Inoltre, se il codice funziona con UTF-8, internamente funziona ancora con le codifiche Unicode, ovvero da qualche parte nel profondo ci sono tabelle di simboli di esattamente caratteri Unicode. È vero, potresti non avere tabelle di caratteri Unicode se hai solo bisogno di contare quanti caratteri ci sono in una riga, ad esempio (vedi sotto)
- UTF-8 è fatto in modo che i vecchi programmi e i computer di oggi possano funzionare normalmente con i caratteri Unicode, come con le vecchie codifiche, come KOI8, Windows-1251, ecc. In UTF-8 non ci sono byte con zero, tutti i byte sono o da 0x01 - 0x7F, come il normale ASCII, o 0x80 - 0xFF, che funziona anche per programmi scritti in C, come funzionerebbe con caratteri non ASCII. vero, per lavoro corretto con i simboli il programma deve conoscere le tabelle Unicode.
- Qualsiasi cosa con il settimo bit più significativo in un byte (contando i bit da zero) UTF-8 fa parte del codestream Unicode.
UTF-8 dall'interno verso l'esterno
Se conosci il sistema di bit, allora ecco a te promemoria veloce come è codificato UTF-8:
Il primo byte Unicode di un carattere UTF-8 inizia con un byte, dove il settimo bit è sempre uno e il sesto bit è sempre uno. In questo caso, nel primo byte, se si guardano i bit da sinistra a destra (7°, 6° e così via fino a zero), ci sono tante unità quanti byte, compreso il primo, vanno a codificare un carattere Unicode. La sequenza degli uno termina con uno zero. E dopo ci sono i bit del carattere Unicode stesso. Il resto dei bit Unicode del carattere cadono nel secondo o anche nel terzo byte (massimo tre, perché - vedi un po 'sotto). Il resto dei byte, ad eccezione del primo, arriva sempre con l'inizio '10' e poi 6 bit della parte successiva del carattere Unicode.
Esempio
Ad esempio: ci sono byte 110 10000 e il secondo 10 011110 ... Il primo inizia con "110", il che significa che se ce ne sono due, ci saranno due byte del flusso UTF-8 e il secondo byte, come tutti gli altri, inizia con "10". E questi due byte codificano il carattere Unicode, che consiste di 10100 bit dal primo pezzo + 101101 dal secondo, risulta -> 10000011110 -> 41E in sistema esadecimale, o U + 041 MI per iscritto notazione Unicode. Questo è il simbolo della grande O russa.
Quanti sono i byte massimi per carattere?
Inoltre, vediamo quanti byte massimi vanno in UTF-8 per codificare 16 bit di codifica Unicode. Il secondo e gli ulteriori byte possono sempre contenere un massimo di 6 bit. Quindi, se inizi con i byte finali, due byte andranno via esattamente (2° e terzo) e il primo deve iniziare con "1110" per codificarne tre. Ciò significa che il primo byte in questo caso può codificare i primi 4 bit di un carattere Unicode. Si scopre 4 + 6 + 6 = 16 byte. Si scopre che UTF-8 può avere 2 o 3 byte per carattere Unicode (non è possibile, poiché non è necessario codificare 6 bit (8 - 2 bit '10') - saranno un carattere ASCII. Ecco perché il primo byte è UTF 8 non può mai iniziare con '10').
Conclusione
A proposito, grazie a questa codifica, puoi prendere qualsiasi byte nel flusso e determinare se un byte è Carattere Unicode(se il settimo bit significa non ASCII), se sì, allora è il primo nel flusso UTF-8 o non il primo (se '10', allora non il primo), se non il primo, allora possiamo tornare indietro byte per trovare il primo codice UTF-8 (con il sesto bit pari a 1), oppure spostati a destra e salta tutti i "10" byte per trovare il carattere successivo. Grazie a questa codifica, i programmi possono anche, senza conoscere Unicode, leggere quanti caratteri ci sono in una stringa (basato sul primo byte UTF-8, calcolare la lunghezza del carattere in byte). In generale, se ci pensi, la codifica UTF-8 è stata inventata in modo molto competente e, allo stesso tempo, molto efficiente.
Codifica delle informazioni
Tutti i numeri (entro certi limiti) nella memoria del computer sono codificati da numeri nel sistema numerico binario. Ci sono regole di traduzione semplici e chiare per questo. Tuttavia, oggi il computer viene utilizzato molto più ampiamente che nel ruolo di esecutore di calcoli ad alta intensità di lavoro. Ad esempio, la memoria del computer memorizza informazioni di testo e multimediali. Si pone quindi la prima domanda:
Come vengono archiviati i caratteri (lettere) nella memoria del computer?
Ogni lettera appartiene a un certo alfabeto in cui i caratteri si susseguono e, quindi, possono essere numerati con numeri interi consecutivi. Ogni lettera può essere associata a un numero intero positivo e chiamarlo codice carattere... È questo codice che verrà archiviato nella memoria del computer e, quando visualizzato sullo schermo o su carta, verrà "convertito" nel suo carattere corrispondente. Per distinguere la rappresentazione dei numeri dalla rappresentazione dei caratteri nella memoria del computer, devi anche memorizzare informazioni su quale tipo di dati è codificato in una particolare area di memoria.
La corrispondenza delle lettere di un certo alfabeto con i codici numerici forma il cosiddetto tabella di codifica... In altre parole, ogni carattere di uno specifico alfabeto ha il proprio codice numerico secondo una specifica tabella di codifica.
Tuttavia, ci sono molti alfabeti nel mondo (inglese, russo, cinese, ecc.). Quindi la prossima domanda è:
Come codificare tutti gli alfabeti utilizzati su un computer?
Per rispondere a questa domanda, seguiremo il percorso storico.
Negli anni '60 del XX secolo in Istituto nazionale americano per gli standard (ANSI)è stata sviluppata una tabella di codifica dei caratteri, che è stata successivamente utilizzata in tutti sistemi operativi... Questa tabella si chiama ASCII (codice standard americano per lo scambio di informazioni)... Poco dopo è apparso versione ASCII estesa.
Secondo la tabella di codifica ASCII, viene assegnato 1 byte (8 bit) per rappresentare un carattere. Un insieme di 8 celle può assumere 2 8 = 256 valori diversi. I primi 128 valori (da 0 a 127) sono costanti e formano la cosiddetta parte principale della tabella, che comprende cifre decimali, lettere dell'alfabeto latino (maiuscole e minuscole), segni di punteggiatura (punto, virgola, parentesi , ecc.), nonché spazi e vari caratteri di servizio (tabulazione, avanzamento riga, ecc.). Valori da 128 a 255 modulo parte aggiuntiva tabelle dove è consuetudine codificare simboli di alfabeti nazionali.
Poiché esiste un'enorme varietà di alfabeti nazionali, esistono tabelle ASCII estese in molte varianti. Anche per la lingua russa esistono diverse tabelle di codifica (Windows-1251 e Koi8-r sono comuni). Tutto ciò crea ulteriori difficoltà. Ad esempio, inviamo una lettera scritta in una codifica e il destinatario cerca di leggerla in un'altra. Di conseguenza, vede krakozyabry. Pertanto, il lettore deve applicare una tabella di codifica diversa per il testo.
C'è anche un altro problema. Gli alfabeti di alcune lingue hanno troppi caratteri e non rientrano nelle posizioni assegnate da 128 a 255 di codifica a byte singolo.
Il terzo problema è cosa fare se il testo utilizza più lingue (ad esempio russo, inglese e francese)? Non puoi usare due tabelle contemporaneamente...
Per risolvere questi problemi, la codifica Unicode è stata sviluppata in una volta sola.
Standard di codifica dei caratteri Unicode
Per risolvere i problemi di cui sopra nei primi anni '90, è stato sviluppato uno standard di codifica dei caratteri, chiamato Unicode. Questo standard ti consente di utilizzare quasi tutte le lingue e i simboli nel testo.
Unicode fornisce 31 bit per la codifica dei caratteri (4 byte meno un bit). Il numero di combinazioni possibili dà un numero esorbitante: 2 31 = 2 147 483 684 (cioè più di due miliardi). Pertanto, Unicode descrive gli alfabeti di tutte le lingue conosciute, anche "morte" e inventate, include molte lingue matematiche e altre Simboli speciali... Tuttavia, la capacità di informazioni di Unicode a 31 bit è ancora troppo grande. Pertanto, viene utilizzata più spesso la versione abbreviata a 16 bit (2 16 = 65 536 valori), in cui sono codificati tutti gli alfabeti moderni.
In Unicode, i primi 128 codici sono gli stessi della tabella ASCII.
Attualmente, la maggior parte degli utenti che utilizzano un computer elabora informazioni di testo, che consistono in simboli: lettere, numeri, segni di punteggiatura, ecc.
Sulla base di una cella con capacità di informazione di 1 bit, possono essere codificati solo 2 stati diversi. Affinché ogni carattere che può essere inserito dalla tastiera nel registro latino riceva il proprio codice binario univoco, sono necessari 7 bit. Sulla base di una sequenza di 7 bit, secondo la formula di Hartley, si possono ottenere N = 2 7 = 128 diverse combinazioni di zeri e uno, es. codici binari. Associando ogni carattere al suo codice binario, otteniamo una tabella di codifica. Una persona opera con simboli, un computer - con i loro codici binari.
Per il layout della tastiera latina, una tale tabella di codifica è una per il mondo intero, quindi il testo digitato utilizzando il layout della tastiera latina verrà visualizzato adeguatamente su qualsiasi computer. Questa tabella si chiama ASCII(American Standard Code of Information Interchange) in inglese si pronuncia [eski], in russo si pronuncia [aski]. Di seguito l'intera tabella ASCII, i cui codici sono indicati in forma decimale. Può essere utilizzato per determinare che quando si inserisce, ad esempio, il carattere "*" dalla tastiera, il computer lo percepisce come codice 42 (10), a sua volta 42 (10) = 101010 (2) - questo è il codice binario del carattere “* ”. I codici da 0 a 31 non vengono utilizzati in questa tabella.
tavolo caratteri ASCII
| codice | simbolo | codice | simbolo | codice | simbolo | codice | simbolo | codice | simbolo | codice | simbolo |
| Spazio | . | @ | P | " | P | ||||||
| ! | UN | Q | un | Q | |||||||
| " | B | R | B | R | |||||||
| # | C | S | C | S | |||||||
| $ | D | T | D | T | |||||||
| % | E | tu | e | tu | |||||||
| & | F | V | F | v | |||||||
| " | G | W | G | w | |||||||
| ( | h | X | h | X | |||||||
| ) | io | sì | io | sì | |||||||
| * | J | Z | J | z | |||||||
| + | : | K | [ | K | { | ||||||
| , | ; | l | \ | io | | | ||||||
| - | < | m | ] | m | } | ||||||
| . | > | n | ^ | n | ~ | ||||||
| / | ? | oh | _ | o | DEL |
Per codificare un carattere viene utilizzata una quantità di informazioni pari a 1 byte, ovvero I = 1 byte = 8 bit. Utilizzando una formula che collega il numero di eventi possibili K e la quantità di informazioni I, puoi calcolare quanti simboli diversi possono essere codificati (supponendo che i simboli siano eventi possibili):
K = 2 I = 2 8 = 256,
cioè, un alfabeto con una capacità di 256 caratteri può essere utilizzato per rappresentare informazioni testuali.
L'essenza della codifica è che a ciascun carattere viene assegnato un codice binario da 00000000 a 11111111 o il corrispondente codice decimale da 0 a 255.
Va ricordato che attualmente per codificare il russo le lettere usano cinque diverse tabelle di codici (KOI - 8, CP1251, CP866, Mac, ISO), inoltre, i testi codificati utilizzando una tabella non verranno visualizzati correttamente in un'altra codifica. Questo può essere chiaramente rappresentato come un frammento della tabella di codifica dei caratteri combinata.
Simboli diversi sono assegnati allo stesso codice binario.
| Codice binario | Codice decimale | KOI8 | CP1251 | CP866 | Mac | ISO |
| B | V | - | - | T |
Tuttavia, nella maggior parte dei casi, l'utente si occupa della transcodifica dei documenti di testo e programmi speciali- convertitori integrati nelle applicazioni.
Dal 1997 ultime versioni Microsoft Office supportare la nuova codifica. È chiamato Unicode. UnicodeÈ una tabella di codifica in cui vengono utilizzati 2 byte per codificare ciascun carattere, ad es. 16 bit. Sulla base di tale tabella, è possibile codificare N = 2 16 = 65 536 caratteri.
Unicode include quasi tutte le scritture moderne, tra cui: arabo, armeno, bengalese, birmano, greco, georgiano, devanagari, ebraico, cirillico, copto, khmer, latino, tamil, hangul, han (Cina, Giappone, Corea), cherokee, etiope, giapponese (Katakana, Hiragana, Kanji) e altri.
Per scopi accademici, sono state aggiunte molte scritture storiche, tra cui: greco antico, geroglifici egizi, cuneiforme, scrittura Maya, alfabeto etrusco.
Unicode offre un'ampia gamma di simboli e pittogrammi matematici e musicali.
Per i caratteri cirillici in Unicode, vengono assegnati due intervalli di codici:
Cirillico (# 0400 - # 04FF)
Supplemento cirillico (# 0500 - # 052F).
Ma l'implementazione della tabella Unicode nella sua forma pura è trattenuta per il motivo che se il codice di un carattere occuperà non un byte, ma due byte, che per memorizzare il testo occuperà il doppio dello spazio su disco, e per il suo trasferimento sui canali di comunicazione - il doppio del tempo.
Pertanto, ora in pratica, la rappresentazione Unicode di UTF-8 (Unicode Transformation Format) è più comune. UTF-8 offre la migliore compatibilità con i sistemi che utilizzano caratteri a 8 bit. Il testo contenente solo caratteri con un numero inferiore a 128 viene convertito in testo ASCII semplice quando scritto in UTF-8. Il resto dei caratteri Unicode è rappresentato da sequenze da 2 a 4 byte di lunghezza. In generale, poiché i caratteri più comuni al mondo - i caratteri dell'alfabeto latino - in UTF-8 occupano ancora 1 byte, questa codifica è più economica del puro Unicode.
Per determinare il codice di caratteri numerici, è possibile utilizzare tabella dei codici... Per fare ciò, seleziona la voce "Inserisci" - "Simbolo" nel menu, dopodiché sullo schermo viene visualizzata la finestra di dialogo Simbolo. Nella finestra di dialogo viene visualizzata la tabella dei simboli per il carattere selezionato. I caratteri in questa tabella sono disposti riga per riga, in sequenza da sinistra a destra, a partire dal carattere Spazio.
 Differenze tra strutture di partizione GPT e MBR
Differenze tra strutture di partizione GPT e MBR Pulisci Internet Explorer
Pulisci Internet Explorer Gli aggiornamenti di Windows vengono scaricati ma non installati
Gli aggiornamenti di Windows vengono scaricati ma non installati