Posebni znaki Unicode. Problem razlikovanja navzven podobnih številk in črk.
Vsak uporabnik interneta je pri poskusu konfiguriranja ene ali druge svoje funkcije vsaj enkrat na zaslonu zagledal napisano besedo "Unicode". Kaj je to, boste izvedeli z branjem tega članka.
Opredelitev
Unicode je standard za kodiranje znakov. Predlagala ga je neprofitna organizacija Unicode Inc. leta 1991. Standard je bil razvit z namenom združiti čim več različnih tipov znakov v enem dokumentu. Stran, ki je bila ustvarjena na njeni podlagi, lahko vsebuje črke in hieroglife iz različnih jezikih(iz ruščine v korejščino) in matematični znaki. V tem primeru so vsi znaki v tem kodiranju prikazani brez težav.
Razlogi za nastanek
Nekoč, že dolgo prej enoten sistem"Unicode", kodiranje je bilo izbrano na podlagi preferenc avtorja dokumenta. Zaradi tega je bilo za branje enega dokumenta pogosto treba uporabiti različne tabele. Včasih je bilo treba to storiti večkrat, kar je bistveno zapletlo življenje navadnega uporabnika. Kot smo že omenili, je rešitev tega problema leta 1991 predlagala neprofitna organizacija Unicode Inc., ki je predlagala novo vrsto kodiranja znakov. Namen je bil združiti zastarele in raznolike standarde. "Unicode" je kodiranje, ki je omogočilo doseganje takrat nepredstavljivega: ustvariti orodje, ki podpira ogromno število znakov. Rezultat je presegel številna pričakovanja - pojavili so se dokumenti, ki so hkrati vsebovali tako angleško kot rusko besedilo, latinščino in matematične izraze.
Toda pred ustvarjanjem enotnega kodiranja je bila potrebna rešitev številnih težav, ki so se pojavile zaradi ogromne raznolikosti standardov, ki so že obstajali v tistem času. Najpogostejši med njimi:
- vilinske črke ali "krakozyabry";
- omejen nabor znakov;
- problem pretvorbe kodiranja;
- podvojene pisave.

Majhen zgodovinski izlet
Predstavljajte si, da je v 80. letih. Računalniška tehnologija še ni tako razširjena in ima drugačen videz od današnje. Takrat je vsak OS edinstven na svoj način in ga vsak navdušenec spremeni za posebne potrebe. Potreba po izmenjavi informacij se spremeni v dodatno izpopolnjevanje vsega na svetu. Poskus branja dokumenta, ustvarjenega v drugem operacijskem sistemu, pogosto prikaže nerazumljiv nabor znakov na zaslonu in začnejo se igre s kodiranjem. To ni vedno mogoče storiti hitro, včasih pa se lahko potreben dokument odpre v šestih mesecih ali celo kasneje. Ljudje, ki pogosto izmenjujejo informacije, si sami ustvarijo pretvorbene tabele. In delo na njih razkrije zanimivo podrobnost: ustvariti jih morate v dveh smereh: »od mojega do tvojega« in obratno. Stroj ne more narediti banalne inverzije izračunov, saj je vir v desnem stolpcu, rezultat pa v levem, ne pa obratno. Če je bilo potrebno uporabiti katero Posebni simboli v dokumentu jih je bilo treba najprej dodati, nato pa partnerju tudi razložiti, kaj mora narediti, da se ti liki ne spremenijo v »nore«. In ne pozabimo, da smo morali za vsako kodiranje razviti ali implementirati lastne pisave, kar je privedlo do ustvarjanja ogromnega števila dvojnikov v OS.
Predstavljajte si tudi, da boste na strani pisav videli 10 kosov enakih Times New Roman z majhnimi oznakami: za UTF-8, UTF-16, ANSI, UCS-2. Ali zdaj razumete, da je bil razvoj univerzalnega standarda nujna potreba?

"Očetje stvarniki"
Začetki Unicode segajo v leto 1987, ko so Joe Becker iz Xeroxa skupaj z Leejem Collinsom in Markom Davisom iz Apple začel raziskovati na področju praktičnega ustvarjanja univerzalnega nabora znakov. Avgusta 1988 je Joe Becker objavil osnutek predloga za 16-bitni mednarodni večjezični sistem kodiranja.
Nekaj mesecev pozneje se je delovna skupina Unicode razširila na Kena Whistlerja in Mikea Kernegana iz RLG, Glenna Wrighta iz Sun Microsystems in nekaj drugih, s čimer je zaključila predhodno delo na enem standardu kodiranja.

splošen opis
Unicode temelji na konceptu znaka. Ta definicija se nanaša na abstraktni pojav, ki obstaja v določeni vrsti pisave in se uresničuje skozi grafeme (njegove »portrete«). Vsak znak je določen v "Unicode" edinstvena koda ki pripadajo določenemu bloku standarda. Na primer, grafem B obstaja v angleški in ruski abecedi, v Unicode pa ima 2 različna znaka. Zanje je uporabljena transformacija, to pomeni, da je vsak od njih opisan s ključem baze podatkov, nizom lastnosti in polnim imenom.
Prednosti Unicode
Od drugih sodobnikov se je kodiranje Unicode razlikovalo po ogromni ponudbi znakov za "šifriranje" znakov. Dejstvo je, da so imeli njegovi predhodniki 8 bitov, torej so podpirali 28 znakov, vendar nov razvoj imel že 216 znakov, kar je bil velik korak naprej. To je omogočilo kodiranje skoraj vseh obstoječih in običajnih abeced.
S prihodom "Unicode" ni bilo treba uporabljati pretvorbenih tabel: kot enoten standard je preprosto zanikal njihovo potrebo. Na enak način so "crakozyabry" potonili v pozabo - en sam standard jih je onemogočil in tudi odpravil potrebo po ustvarjanju podvojenih pisav.
Razvoj Unicode
Seveda napredek ne miruje in od prve predstavitve je minilo 25 let. Vendar kodiranje Unicode trmasto ohranja svoj položaj v svetu. V mnogih pogledih je to postalo mogoče zaradi dejstva, da se je postalo enostavno izvajati in širiti, saj so ga prepoznali razvijalci lastniške (plačane) in odprtokodne programske opreme.

Hkrati pa ne smemo domnevati, da nam je danes na voljo enako kodiranje Unicode kot pred četrt stoletja. Na ta trenutek njegova različica se je spremenila v 5.x.x, število kodiranih znakov pa se je povečalo na 231. Možnost uporabe večje količine znakov je bila opuščena, da bi še vedno ohranili podporo za Unicode-16 (kodiranje, pri katerem je bilo največje število znakov omejeno do 216). Od svojega začetka in do različice 2.0.0 je "Unicode Standard" povečal število znakov, ki so bili vključeni vanj, skoraj 2-krat. Rast priložnosti se je nadaljevala tudi v naslednjih letih. Do različice 4.0.0 je že obstajala potreba po povečanju samega standarda, kar je bilo tudi storjeno. Kot rezultat, je "Unicode" dobil obliko, v kateri ga poznamo danes.

Kaj je še v Unicode?
Poleg ogromnega števila znakov, ki se nenehno dopolnjujejo, ima še eno uporabno lastnost. To je tako imenovana normalizacija. Namesto pomikanja po celotnem dokumentu znak za znakom in zamenjave ustreznih ikon iz iskalne tabele se uporablja eden od obstoječih algoritmov za normalizacijo. o čem se pogovarjamo?
Namesto zapravljanja računalniških virov za redno preverjanje istega znaka, ki je lahko v različnih abecedah podobni, se uporablja poseben algoritem. Omogoča vam, da vzamete podobne znake v ločen stolpec nadomestne tabele in se že sklicujete nanje ter ne preverjate vseh podatkov znova in znova.
Štirje takšni algoritmi so bili razviti in implementirani. V vsakem od njih se preoblikovanje odvija po strogo določenem principu, ki se razlikuje od drugih, zato katerega od njih ni mogoče imenovati za najbolj učinkovitega. Vsak je bil razvit za posebne potrebe, implementiran in uspešno uporabljen.

Porazdelitev standarda
V svoji 25-letni zgodovini je Unicode verjetno najbolj razširjeno kodiranje na svetu. Temu standardu so prilagojeni tudi programi in spletne strani. O širini uporabe lahko govori dejstvo, da Unicode danes uporablja več kot 60 % internetnih virov.
Zdaj veste, kdaj se je pojavil standard Unicode. Kaj je to, tudi vi veste in boste lahko cenili celoten pomen izuma, ki ga je izdelala skupina strokovnjakov Unicode Inc. pred več kot 25 leti.
Potrebujete gostovanje ali domeno? Klikni tukaj! Želite ustvariti spletno trgovino? Klikni tukaj! (Skupaj)Včasih je pri pisanju objave potreben znak (znak), ki ga ni na tipkovnici, v takih situacijah vam bo pomagala tabela znakov Unicode. Danes si bomo ogledali spletna storitev, v katerem so združeni vsi znaki Unicode ...
Tabela znakov Unicode
Za tiste, ki jih zanima ozadje videza Unicode- tukaj je povezava do wikipedije
Torej opredelimo svoje interese v znaki unicode je njihova uporaba v njihovih člankih, na njihovih spletnih straneh.
Najprej pojdimo na stran storitvenih znakov Unicode:


Oglejmo si vmesnik te storitve. Na samem vrhu je iskalno polje, dovolj je, da vtipkate ime elementa, ki ga iščete, na primer: "Puščica" ali "Elipsis", po vnosu kliknite na iskanje, da dobite rezultat.
Poleg iskanja je preklopnik jezikov strani.
Spodaj je seznam pogosto zahtevanih simbolov, morda bo med njimi tisti, ki ga potrebujete, če je tako, samo kliknite na simbol, da odprete stran s podrobnimi informacijami o njem.
Glavni del strani je tabela znakov unicode, za lažje iskanje lahko kliknete tudi na "Nadzorni znaki", da izberete skupino znakov, na primer: "Grški znaki", če morate vstaviti grški znak.
Iskanje želenega elementa v tabeli znakov Unicode
Uporabimo na primer iskanje in vanj vnesemo besedo "puščica" in kliknemo iskanje.

Na strani z rezultati iskanja poiščite simbol, ki ga potrebujemo, in ga kliknite, da odprete stran podrobne informacije o njem.
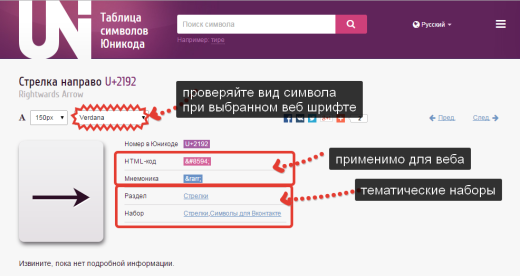
Na strani znak unicode zanima nas njegova HTML koda ali Mnemonika, oboje je mogoče uporabiti na spletni strani, za to kopirajte kodo in jo prilepite na pravo mesto v oznaki HTML, brskalnik jo bo interpretiral in prikazal kot simbol na stran.
Upoštevajte, da je na strani z znaki Unicode možnost izbire pisave. Vedno preizkusite, kako se bo vaša pisava upodabljala z Verdana, Arial (in drugimi spletnimi pisavami). ne podpirajo vseh znakov.
(kode od 0 do 127), tj. Latinske črke, številke in posebni znaki so kodirani v enem bajtu. Ruske črke (cirilica) predstavljajo 16-bitne (dvobajtne) kode:
110XXXXXX 10XXXXXX,
kjer so X binarne števke za umestitev kode znakov v skladu s tabelo UNICODE.
Unicode (eng. Unicode) je standard za kodiranje znakov, ki omogoča predstavitev znakov skoraj vseh pisnih jezikov. Znaki, predstavljeni v Unicode, so kodirani kot nepodpisana cela števila. Te številke se imenujejo kode znakov Unicode ali preprosto UNICODE. Unicode ima več oblik za predstavitev znakov na računalniku: UTF-8, UTF-16 (UTF-16BE, UTF-16LE) in UTF-32 (UTF-32BE, UTF-32LE). (Angleški format transformacije Unicode - UTF).
Razmislite, kako je kodiran UTF-8 pismo F. njo UNICODE- 1046 10 ali 0416 16 ali 10000 010110 2. UNICODE v binarni obliki je razdeljen na dva dela: pet levih bitov in šest desnih. Leva stran je dopolnjena z bajtom z znakom 110 dvobajtna koda UTF-8: 110 10000. Dva bita sta dodeljena desni strani 10 znak nadaljevanja večbajtne kode: 10 010110. Končna črkovna koda F v UTF-8 izgleda takole:
110
10000 10
010110 2
ali D0 96 16
Tako je ruska črka kodirana dvakrat: najprej v 11-bitno UNICODE, nato pa v 16-bitni UTF-8.
V spodnji tabeli, poleg kod UNICODE in UTF-8 v šestnajstiškem zapisu, dane kode UTF-8 v decimalnem zapisu in za primerjavo cirilice v kodiranju CP-1251, drugače imenovano okna-1251.
| Simbol | UNICODE | UTF-8 | CP-1251 | ||
|---|---|---|---|---|---|
| Shestn. | deset | Shestn. | deset | ||
| AMPAK | 0410 | 1040 | D090 | 208 144 | 192 |
| B | 0411 | 1041 | D091 | 208 145 | 193 |
| AT | 0412 | 1042 | D092 | 208 146 | 194 |
| G | 0413 | 1043 | D093 | 208 147 | 195 |
| D | 0414 | 1044 | D094 | 208 148 | 196 |
| E | 0415 | 1045 | D095 | 208 149 | 197 |
| F | 0416 | 1046 | D096 | 208 150 | 198 |
| W | 0417 | 1047 | D097 | 208 151 | 199 |
| IN | 0418 | 1048 | D098 | 208 152 | 200 |
| Y | 0419 | 1049 | D099 | 208 153 | 201 |
| TO | 041A | 1050 | D09A | 208 154 | 202 |
| L | 041B | 1051 | D09B | 208 155 | 203 |
| M | 041C | 1052 | D09C | 208 156 | 204 |
| H | 041D | 1053 | D09D | 208 157 | 205 |
| O | 041E | 1054 | D09E | 208 158 | 206 |
| P | 041F | 1055 | D09F | 208 159 | 207 |
| R | 0420 | 1056 | D0A0 | 208 160 | 208 |
| Z | 0421 | 1057 | D0A1 | 208 161 | 209 |
| T | 0422 | 1058 | D0A2 | 208 162 | 210 |
| Pri | 0423 | 1059 | D0A3 | 208 163 | 211 |
| F | 0424 | 1060 | D0A4 | 208 164 | 212 |
| X | 0425 | 1061 | D0A5 | 208 165 | 213 |
| C | 0426 | 1062 | D0A6 | 208 166 | 214 |
| H | 0427 | 1063 | D0A7 | 208 167 | 215 |
| W | 0428 | 1064 | D0A8 | 208 168 | 216 |
| SCH | 0429 | 1065 | D0A9 | 208 169 | 217 |
| Kommersant | 042A | 1066 | D0AA | 208 170 | 218 |
| S | 042B | 1067 | D0AB | 208 171 | 219 |
| b | 042C | 1068 | D0AC | 208 172 | 220 |
| E | 042D | 1069 | D0AD | 208 173 | 221 |
| YU | 042E | 1070 | D0AE | 208 174 | 222 |
| jaz | 042F | 1071 | D0AF | 208 175 | 223 |
| ampak | 0430 | 1072 | D0B0 | 208 176 | 224 |
| b | 0431 | 1073 | D0B1 | 208 177 | 225 |
| v | 0432 | 1074 | D0B2 | 208 178 | 226 |
| G | 0433 | 1075 | D0B3 | 208 179 | 227 |
| d | 0434 | 1076 | D0B4 | 208 180 | 228 |
| e | 0435 | 1077 | D0B5 | 208 181 | 229 |
| no | 0436 | 1078 | D0B6 | 208 182 | 230 |
| h | 0437 | 1079 | D0B7 | 208 183 | 231 |
| in | 0438 | 1080 | D0B8 | 208 184 | 232 |
| th | 0439 | 1081 | D0B9 | 208 185 | 233 |
| do | 043A | 1082 | D0BA | 208 186 | 234 |
| l | 043B | 1083 | D0BB | 208 187 | 235 |
| m | 043C | 1084 | D0BC | 208 188 | 236 |
| n | 043D | 1085 | D0BD | 208 189 | 237 |
| približno | 043E | 1086 | D0BE | 208 190 | 238 |
| P | 043F | 1087 | D0BF | 208 191 | 239 |
| R | 0440 | 1088 | D180 | 209 128 | 240 |
| z | 0441 | 1089 | D181 | 209 129 | 241 |
| T | 0442 | 1090 | D182 | 209 130 | 242 |
| pri | 0443 | 1091 | D183 | 209 131 | 243 |
| f | 0444 | 1092 | D184 | 209 132 | 244 |
| X | 0445 | 1093 | D185 | 209 133 | 245 |
| c | 0446 | 1094 | D186 | 209 134 | 246 |
| h | 0447 | 1095 | D187 | 209 135 | 247 |
| sh | 0448 | 1096 | D188 | 209 136 | 248 |
| SCH | 0449 | 1097 | D189 | 209 137 | 249 |
| b | 044A | 1098 | D18A | 209 138 | 250 |
| s | 044B | 1099 | D18B | 209 139 | 251 |
| b | 044C | 1100 | D18C | 209 140 | 252 |
| uh | 044D | 1101 | D18D | 209 141 | 253 |
| Yu | 044E | 1102 | D18E | 209 142 | 254 |
| jaz | 044F | 1103 | D18F | 209 143 | 255 |
| Znaki izven splošnega pravila | |||||
| Joj | 0401 | 1025 | D001 | 208 101 | 168 |
| yo | 0451 | 1025 | D191 | 209 145 | 184 |
Včasih morate svojemu dizajnu dodati ikono, vendar ne želite vključiti dodatnih slik ali celotne pisave ikone, kot je Font Awesome? Potem imamo za vas dobro novico – v vašem brskalniku je že na voljo obsežna knjižnica ikon in simbolov. Imenuje se Unicode in je standard, ki dodeljuje edinstveni identifikatorji za nenehno naraščajoče število (trenutno več kot 110.000) simbolov in ikon.
To pa ne pomeni, da imate na izbiro na stotine tisoč ikon. Odvisno je od brskalnika, ki jih upodablja, in za to uporablja pisave, ki so nameščene v sistemu. V tem članku smo zbrali številne nabore znakov, ki so na voljo v sistemih Windows, Linux, OS X, Android in IOS. Danes jih lahko uporabite v svojem oblikovanju!
Nasvet: ki pojasnjuje vse, kar morate vedeti o kodiranju in Unicode, ki ga priporočamo v branje vsakemu razvijalcu programske opreme.
Kako uporabljati te ikone
Ikone, prikazane v spodnjih tabelah, so običajni znaki, ki jih lahko kopirate in prilepite, kot da bi bile črke abecede. Če pa se kodiranje uporablja za shranjevanje datotek HTML/CSS ne UTF-8 ne bodo prikazani. Zato smo uvedli HTML escape kodo, ki bo vedno delovala. Tukaj je tisto, kar morate storiti za uporabo teh ikon:
- Poiščite ikono, ki vam je všeč. Zagotovili smo majhne in velike predoglede.
- Kopirajte kodo.
- Prilepite ga v HTML kot navadno besedilo. V CSS jih lahko uporabite kot vrednost lastnosti vsebino. V JS, PHP in drugih programskih jezikih jih lahko uporabljate kot navadno besedilo v nizih.
- Ikone lahko prilagodite tako, da nastavite velikost pisave, barvo, besedilo in senco tako kot običajno besedilo.
ikone
| ime | Predogled | Koda | |
|---|---|---|---|
| smeška | ☺ | ☺ | ☺ |
| Opozorilni znak | ⚠ | ⚠ | ⚠ |
| Vrelci | ♨ | ♨ | ♨ |
| invalidski voziček | ♿ | ♿ | ♿ |
| Recikliraj | ♻ | ♻ | ♻ |
| 8 žoga | ➑ | ➑ | ➑ |
| visokonapetostni | ⚡ | ⚡ | ⚡ |
| bela zvezda | ☆ | ☆ | ☆ |
| Črna zvezda | ★ | ★ | ★ |
| belo srce | ♡ | ♡ | ♡ |
| črno srce | ❤ | ❤ | ❤ |
| Kava | ☕ | ☕ | ☕ |
| Letalo | ✈ | ✈ | ✈ |
| Peščena ura | ⌛ | ⌛ | ⌛ |
| ura | ⌚ | ⌚ | ⌚ |
| Črne škarje | ✂ | ✂ | ✂ |
| Bele škarje | ✄ | ✄ | ✄ |
| Krona | ♕ | ♕ | ♕ |
| Sidro | ⚓ | ⚓ | ⚓ |
| križ | ✝ | ✝ | ✝ |
| Črno bel krog | ◑ | ◑ | ◑ |
| Osma opomba | ♪ | ♪ | ♪ |
| Osvetljene osme note | ♫ | ♫ | ♫ |
| Zvezdica s štirimi baloni | ✣ | ✣ | ✣ |
| Obkrožena bela zvezda | ✪ | ✪ | ✪ |
| bela zvezda | ✰ | ✰ | ✰ |
| Bela štirikraka zvezda | ✧ | ✧ | ✧ |
| Črna štirikraka zvezda | ✦ | ✦ | ✦ |
| Preverjanje glasovnice | ☑ | ☑ | ☑ |
| Kljukica | ✔ | ✔ | ✔ |
| Križni znak | ✘ | ✘ | ✘ |
| Svinčnik | ✎ | ✎ | ✎ |
| Roka za pisanje | ✍ | ✍ | ✍ |
| Ženska | ♀ | ♀ | ♀ |
| moški | ♂ | ♂ | ♂ |
| črn telefon | ☎ | ☎ | ☎ |
| bel telefon | ☏ | ☏ | ☏ |
| Ovojnica | ✉ | ✉ | ✉ |
| telefonsko lokacijo | ✆ | ✆ | ✆ |
Puščice v unicode
| ime | Predogled | Koda | |
|---|---|---|---|
| Puščica v levo | ← | ← | ← |
| Puščica v desno | → | → | → |
| Puščica navzgor | |||
| Puščica navzdol | ↓ | ↓ | ↓ |
| Puščica levo desno | ↔ | ↔ | ↔ |
| Puščica navzgor in navzdol | ↕ | ↕ | ↕ |
| Desno in levo puščice | ⇄ | ⇄ | ⇄ |
| Puščice gor in dol | ⇅ | ⇅ | ⇅ |
| Puščica dol levo za 90 stopinj | ↲ | ↲ | ↲ |
| Puščica navzdol-desno 90 stopinj | ↳ | ↳ | ↳ |
| Puščica gor levo za 90 stopinj | ↰ | ↰ | ↰ |
| Puščica gor-desno 90 stopinj | ↱ | ↱ | ↱ |
| Severozahodna puščica do vogala | ⇱ | ⇱ | ⇱ |
| Jugovzhodna puščica do vogala | ⇲ | ⇲ | ⇲ |
| Puščica levo do vrstice | ⇤ | ⇤ | ⇤ |
| Puščica desno do vrstice | ⇥ | ⇥ | ⇥ |
| Polkrožna puščica v nasprotni smeri urnega kazalca | ↶ | ↶ | ↶ |
| Polkrožna puščica v smeri urinega kazalca | ↷ | ↷ | ↷ |
| Krožna puščica v nasprotni smeri urinega kazalca | ↺ | ↺ | ↺ |
| Krožna puščica v smeri urinega kazalca | ↻ | ↻ | ↻ |
| Široka puščica v desno | ➔ | ➔ | ➔ |
| Cikcak puščica navzdol | ↯ | ↯ | ↯ |
| Severozahodna puščica | ↖ | ↖ | ↖ |
| Težka jugovzhodna puščica | ➘ | ➘ | ➘ |
| Težka puščica v desno | ➙ | ➙ | ➙ |
| Težka severovzhodna puščica | ➚ | ➚ | ➚ |
| Črtkana puščica v desno | ➟ | ➟ | ➟ |
| Puščica s pikami v levo | ⇠ | ⇠ | ⇠ |
| Črna puščica v desno | ➤ | ➤ | ➤ |
| Bela puščica levo | ⇦ | ⇦ | ⇦ |
| Bela puščica v desno | ⇨ | ⇨ | ⇨ |
| Levi kotni narekovaj | « | « | « |
| Pravokotni narekovaj | » | » | » |
| Desni črni kazalec | |||
| Levi črni kazalec | ◀ | ◀ | ◀ |
| Gor črni kazalec | ▲ | ▲ | ▲ |
| Črni kazalec navzdol | ▼ | ▼ | ▼ |
| Desni beli kazalec | ▷ | ▷ | ▷ |
| Levi beli kazalec | ◁ | ◁ | ◁ |
| Navzgor beli kazalec | △ | △ | △ |
| Bela kazalec navzdol | ▽ | ▽ | ▽ |
| Puščica z lokom | ➴ | ➴ | ➴ |
Posebni znaki v unicode
Valuta v unicode
vremenske ikone
| ime | Predogled | Koda | |
|---|---|---|---|
| stopnje | ° | ° | ° |
| majhno sonce | ☀ | ☀ | ☀ |
| veliko sonce | ☼ | ☼ | ☼ |
| oblak | ☁ | ☁ | ☁ |
| Dežnik | ☔ | ☔ | ☔ |
| snežinka 1 | ❆ | ❆ | ❆ |
| snežinka 2 | ❅ | ❅ | ❅ |
| snežinka 3 | ❄ | ❄ | ❄ |
Kazalniki Unicode
| ime | Predogled | Koda | |
|---|---|---|---|
| Kazalec levo črn | ☚ | ☚ | ☚ |
| Kazalec desno črn | ☛ | ☛ | ☛ |
| Kazalec levo bel | ☜ | ☜ | ☜ |
| Kazalec gor belo | ☝ | ☝ | ☝ |
| Kazalec desno bel | ☞ | ☞ | ☞ |
| Kazalec navzdol belo | ☟ | ☟ | ☟ |
Znaki zodiaka v unicode
| ime | Predogled | Koda | |
|---|---|---|---|
| Oven | ♈ | ♈ | ♈ |
| Bik | ♉ | ♉ | ♉ |
| Dvojčka | ♊ | ♊ | ♊ |
| Rak | ♋ | ♋ | ♋ |
| lev | ♌ | ♌ | ♌ |
| Devica | ♍ | ♍ | ♍ |
| tehtnice | ♎ | ♎ | ♎ |
| Škorpijon | ♏ | ♏ | ♏ |
| Strelec | ♐ | ♐ | ♐ |
| Kozorog | ♑ | ♑ | ♑ |
| Vodnar | ♒ | ♒ | ♒ |
| Ribe | ♓ | ♓ | ♓ |
Simboli kartic v unicode
| ime | Predogled | Koda | |
|---|---|---|---|
| Klub Črna | ♠ | ♠ | ♠ |
| srca črna | ♥ | ♥ | ♥ |
| Diamanti črni | ♦ | ♦ | ♦ |
| Piki črni | ♣ | ♣ | ♣ |
| Klub Bela | ♤ | ♤ | ♤ |
| srca bela | ♡ | ♡ | ♡ |
| Diamanti beli | ♢ | ♢ | ♢ |
| Pike bele | ♧ | ♧ | ♧ |
Šahovske figure v unicode
| ime | Predogled | Koda | |
|---|---|---|---|
| kralj beli | ♔ | ♔ | ♔ |
| kraljica bela | ♕ | ♕ | ♕ |
| Rook White | ♖ | ♖ | ♖ |
| Škof Beli | ♗ | ♗ | ♗ |
| Vitez Beli | ♘ | ♘ | ♘ |
| zastavljalka bela | ♙ | ♙ | ♙ |
| kralj črn | ♚ | ♚ | ♚ |
| kraljica črna | ♛ | ♛ | ♛ |
| Rook Black | ♜ | ♜ | ♜ |
| Škof Črni | ♝ | ♝ | ♝ |
| Črni vitez | ♞ | ♞ | ♞ |
| Pawn Black | ♟ | ♟ | ♟ |
Igra s kockami
| ime | Predogled | Koda | |
|---|---|---|---|
| Vrzi kocke ena | ⚀ | ⚀ | ⚀ |
| Kocke Rot Two | ⚁ | ⚁ | ⚁ |
| Mete tri kocke | ⚂ | ⚂ | ⚂ |
| Mete kocke štiri | ⚃ | ⚃ | ⚃ |
| Mete kocke pet | ⚄ | ⚄ | ⚄ |
| Mete šest kock | ⚅ | ⚅ | ⚅ |
Matematični simboli v Unicode
| ime | Predogled | Koda | |
|---|---|---|---|
| neskončnost | ∞ | ∞ | ∞ |
| plus minus | ± | ± | ± |
| Manj kot ali enako | ≤ | ≤ | ≤ |
| Več kot ali enako | ≥ | ≥ | ≥ |
| Ni enako | ≠ | ≠ | ≠ |
| divizije | ÷ | ÷ | ÷ |
| množenje x | × | × | × |
| Težko množenje x | ✖ | ✖ | ✖ |
| Nadpis ena | ¹ | ¹ | ¹ |
| Nadpis dva | ² | ² | ² |
| Nadpis tri | ³ | ³ | ³ |
| Obkroženi plus | ⊕ | ⊕ | ⊕ |
| Obkroženo množenje | ⊗ | ⊗ | ⊗ |
| Logično IN | ∧ | ∧ | ∧ |
| Logično ALI | ∨ | ∨ | ∨ |
| Delta | ∆ | ∆ | ∆ |
| pita | ∏ | ∏ | ∏ |
| Sigma (SUM) | ∑ | ∑ | ∑ |
| Omega | Ω | Ω | Ω |
| Prazen komplet | ∅ | ∅ | ∅ |
| Kot | ∠ | ∠ | ∠ |
| vzporedno | ∥ | ∥ | ∥ |
| Pravokotno | ⊥ | ⊥ | ⊥ |
| Skoraj enako | ≈ | ≈ | ≈ |
| trikotnik | △ | △ | △ |
| Krog | ○ | ○ | ○ |
| Kvadrat | □ | □ | □ |
Ulomki
| ime | Predogled | Koda | |
|---|---|---|---|
| ena četrtina (1/4) | ¼ | ¼ | ¼ |
| polovica (1/2) | ½ | ½ | ½ |
| tri četrtine (3/4) | ¾ | ¾ | ¾ |
| ena tretjina (1/3) | ⅓ | ⅓ | ⅓ |
| Dve tretjini (2/3) | ⅔ | ⅔ | ⅔ |
| ena osem (1/8) | ⅛ | ⅛ | ⅛ |
| Tri osmice (3/8) | ⅜ | ⅜ | ⅜ |
| Pet osmic (5/8) | ⅝ | ⅝ | ⅝ |
| Sedem osem (7/8) | ⅞ | ⅞ | ⅞ |
Rimske številke v unicode
| ime | Predogled | Koda | |
|---|---|---|---|
| Rimska številka ena | Ⅰ | Ⅰ | Ⅰ |
| Rimska številka dve | Ⅱ | Ⅱ | Ⅱ |
| Rimska številka tri | Ⅲ | Ⅲ | Ⅲ |
| Rimska številka štiri | Ⅳ | Ⅳ | Ⅳ |
| rimska številka pet | Ⅴ | Ⅴ | Ⅴ |
| rimska številka šest | Ⅵ | Ⅵ | Ⅵ |
| rimska številka sedem | Ⅶ | Ⅶ | Ⅶ |
| Rimska številka osem | Ⅷ | Ⅷ | Ⅷ |
| rimska številka devet | Ⅸ | Ⅸ | Ⅸ |
| Rimska številka deset | Ⅹ | Ⅹ | Ⅹ |
| Rimska številka Enajst | Ⅺ | Ⅺ | Ⅺ |
| Rimska številka dvanajst | Ⅻ | Ⅻ | Ⅻ |
Obstaja nekaj razlik pri upodabljanju teh znakov v različnih operacijski sistemi. To povzročajo različne družine pisav, ki se uporabljajo. Poleg tega iOS in Android nekatere znake Unicode zamenjata z emojiji, zato preverite dodane znake, da se prepričate, da se to ne zgodi in da se ikone prikažejo, kot je predvideno.
Elementi kodnega prostora, ki predstavljajo nenegativna cela števila. Družina kodiranja definira strojno predstavitev zaporedja kod UCS.
Kode v standardu Unicode so razdeljene na več področij. Območje s kodami U+0000 do U+007F vsebuje znake ASCII z ustreznimi kodami. Sledijo področja znakov različnih skript, ločil in tehničnih simbolov. Nekatere kode so rezervirane za prihodnjo uporabo. Pod ciriličnimi znaki so dodeljena področja znakov s kodami od U + 0400 do U + 052F, od U + 2DE0 do U + 2DFF, od U + A640 do U + A69F (glej Cirilica v Unicode).
Predpogoji za nastanek in razvoj Unicode
Ker so bili v številnih računalniških sistemih (na primer Windows NT) fiksni 16-bitni znaki že uporabljeni kot privzeto kodiranje, je bilo odločeno, da se vsi najpomembnejši znaki kodirajo le znotraj prvih 65.536 mest (t. i. angleščina. osnovno večjezično letalo, BMP). Preostali prostor se uporablja za "dodatne znake" (eng. komplementarni znaki): sistemi pisanja izumrlih jezikov ali zelo redko uporabljenih kitajskih črk, matematičnih in glasbenih simbolov.
Za združljivost s starejšimi 16-bitnimi sistemi je bil izumljen sistem UTF-16, kjer je prvih 65.536 pozicij, brez pozicij iz intervala U+D800…U+DFFF, prikazanih neposredno kot 16-bitna števila, ostali pa so predstavljeni. kot "nadomestni pari" (prvi element para iz regije U+D800…U+DBFF, drugi element para iz regije U+DC00…U+DFFF). Za nadomestne pare je bil uporabljen del kodnega prostora (2048 pozicij), ki je bil prej rezerviran za "znake za zasebno uporabo".
Ker je v UTF-16 mogoče prikazati le 2 20 +2 16 −2048 (1 112 064) znakov, je bila ta številka izbrana kot končna vrednost kodnega prostora Unicode.
Čeprav je bilo območje kode Unicode razširjeno preko 2 16 že v različici 2.0, so bili prvi znaki v "top" regiji postavljeni šele v različici 3.1.
Vloga tega kodiranja v spletnem sektorju nenehno raste, v začetku leta 2010 je bil delež spletnih strani, ki uporabljajo Unicode, približno 50 %.
Različice Unicode
Ker se tabela znakov sistema Unicode spreminja in dopolnjuje ter se izdajajo nove različice tega sistema - in to delo še poteka, saj je sistem Unicode sprva vključeval samo ravnino 0 - dvobajtne kode - so izdani tudi novi dokumenti ISO. Sistem Unicode obstaja v celoti v naslednjih različicah:
- 1.1 (ustreza ISO/IEC 10646-1:1993), standard 1991-1995.
- 2.0, 2.1 (isti ISO/IEC 10646-1:1993 plus dodatki: "Spremembe" 1 do 7 in "Tehnični popravki" 1 in 2), standard iz leta 1996.
- 3.0 (ISO/IEC 10646-1:2000), standard 2000.
- 3.1 (standarda ISO/IEC 10646-1:2000 in ISO/IEC 10646-2:2001), standard 2001.
- 3.2, standard 2002.
- 4.0, standard 2003.
- 4.01, standard 2004.
- 4.1, standard 2005.
- 5.0, standard 2006.
- 5.1, standard 2008.
- 5.2, standard 2009.
- 6.0, standard 2010.
- 6.1, standard 2012.
- 6.2, standard 2012.
Kodni prostor
Čeprav obrazca UTF-8 in UTF-32 omogočata kodiranje do 231 (2147483648) kodnih točk, je bila sprejeta odločitev, da se za združljivost z UTF-16 uporabi samo 1112064. Vendar je tudi to več kot dovolj – danes (v različici 6.0) je uporabljenih nekaj manj kot 110.000 kodnih mest (109.242 grafičnih in 273 drugih znakov).
Kodni prostor je razdeljen na 17 letala 2 po 16 (65536) znakov. Ozemljitvena plošča se imenuje osnovni, vsebuje simbole najpogostejših skript. Prva ravnina se uporablja predvsem za zgodovinske pisave, druga ravnina se uporablja za redko uporabljene kitajske črke, tretja je rezervirana za arhaične kitajske črke. Letala 15 in 16 sta rezervirana za zasebno uporabo.
Za določitev Znaki Unicode zapis oblike »U+ xxxx” (za kode 0…FFFF) ali „U+ xxxxxx” (za kode 10000…FFFFF) ali „U+ xxxxxx» (za kode 100000…10FFFF), kjer xxx- šestnajstiške številke. Na primer, znak "I" (U+044F) ima kodo 044F = 1103.
Sistem kodiranja
Univerzalni sistem kodiranja (Unicode) je nabor grafičnih znakov in način za njihovo kodiranje za računalniško obdelavo besedilnih podatkov.
Grafični simboli so simboli, ki imajo vidno sliko. Grafični znaki so v nasprotju s kontrolnimi znaki in znaki za oblikovanje.
Grafični simboli vključujejo naslednje skupine:
- črke, ki jih vsebuje vsaj ena od streženih abeced;
- številke;
- ločila;
- posebni znaki (matematični, tehnični, ideogrami itd.);
- ločevalniki.
Unicode je sistem za linearno predstavitev besedila. Znake, ki imajo dodatne nadpisne ali podpisne elemente, lahko predstavimo kot zaporedje kod, zgrajenih po določenih pravilih (sestavljena različica, sestavljeni znak) ali kot en sam znak (monolitna različica, predkomponirani znak).
Modifikacijski simboli
Predstavitev znaka "Y" (U+0419) kot osnovnega znaka "AND" (U+0418) in znaka za spreminjanje "̆" (U+0306)
Grafični znaki v Unicode se delijo na razširjene in nerazširjene (brez širine). Neraztegnjeni znaki ne zavzamejo prostora v nizu, ko so prikazani. Sem spadajo zlasti naglasna znamenja in drugi diakritični znaki. Tako razširjeni kot nerazširjeni znaki imajo svoje kode. Razširjeni znaki se sicer imenujejo osnovni znaki. osnovni znaki), in nerazširjeno - spreminjanje (eng. kombiniranje znakov); slednji pa se ne morejo samostojno srečati. Znak "á" je na primer lahko predstavljen kot zaporedje osnovnega znaka "a" (U+0061) in modifikatorskega znaka "́" (U+0301) ali kot monoliten znak "á" (U+00C1 ).
Posebna vrsta spreminjajočih se znakov so izbirniki različic sloga. izbirniki variacij). Vplivajo samo na tiste simbole, za katere so definirane takšne različice. V različici 5.0 so za serijo definirane možnosti pisave matematični simboli, za znake tradicionalne mongolske abecede in za znake mongolske kvadratne pisave.
Oblike normalizacije
Ker so lahko predstavljeni isti znaki različne kode, kar včasih otežuje obdelavo, obstajajo procesi normalizacije, ki so zasnovani tako, da besedilo privedejo do določene standardne oblike.
Standard Unicode opredeljuje 4 oblike normalizacije besedila:
- Normalizacijska oblika D (NFD) je kanonična razgradnja. V procesu preoblikovanja besedila v to obliko se vsi sestavljeni znaki rekurzivno nadomestijo z več sestavljenimi znaki, v skladu s tabelami razčlenitve.
- Normalizacijska oblika C (NFC) je kanonična razgradnja, ki ji sledi kanonična sestava. Najprej se besedilo reducira na obliko D, po kateri se izvede kanonična kompozicija - besedilo se obdela od začetka do konca in upošteva se naslednja pravila:
- Simbol S je primarniče ima v bazi znakov Unicode ničelni modifikacijski razred.
- V katerem koli zaporedju znakov, ki se začne z začetnim znakom S, je znak C blokiran pred S, če in samo če je med S in C kateri koli znak B, ki se bodisi začne bodisi ima enak modifikacijski razred ali večji od C. To je pravilo velja samo za nize, ki so bili podvrženi kanonični razgradnji.
- Primarni Sestavljen je znak, ki ima kanonično razgradnjo v bazi znakov Unicode (ali kanonično razgradnjo za hangul in ni na seznamu izključitev).
- Simbol X je lahko primarni kombiniran s simbolom Y, če in samo če obstaja primarni sestavljeni Z, ki je kanonično enakovreden zaporedju
- Če naslednji simbol C ni blokiran z zadnjim najdenim začetnim osnovnim simbolom L in ga je mogoče uspešno primarno ujemati z njim, se L nadomesti s sestavljenim L-C in C se odstrani.
- Normalizacijska oblika KD (NFKD) je združljiva razgradnja. Ko se pretvorijo v to obliko, se vsi sestavljeni znaki zamenjajo tako z uporabo kanoničnih zemljevidov razgradnje Unicode kot z združljivimi preslikavami razgradnje, nato pa se rezultat postavi v kanoničen vrstni red.
- Normalizacijska oblika KC (NFKC) - združljiva razgradnja, ki ji sledi kanonično sestavo.
Izraza "sestava" in "razgradnja" pomenita povezavo oziroma razgradnjo simbolov na njihove sestavne dele.
Primeri
| Izvirno besedilo | NFD | NFC | NFKD | NFKC |
|---|---|---|---|---|
| Francais | Franc\u0327ais | Fran\xe7ais | Franc\u0327ais | Fran\xe7ais |
| A, Yo, Y | \u0410, \u0401, \u0419 | \u0410, \u0415\u0308, \u0418\u0306 | \u0410, \u0401, \u0419 | |
| が | \u304b\u3099 | \u304c | \u304b\u3099 | \u304c |
| Henrik IV | Henrik IV | Henrik IV | Henrik IV | Henrik IV |
| Henry Ⅳ | Henry \u2163 | Henry \u2163 | Henrik IV | Henrik IV |
dvosmerno pisanje
Standard Unicode podpira jezike, napisane tako od leve proti desni (eng. od leve proti desni, LTR), kot tudi pisanje od desne proti levi (eng. od desne proti levi, RTL) - na primer arabske in hebrejske črke. V obeh primerih so znaki shranjeni v "naravnem" vrstnem redu; njihov prikaz ob upoštevanju želene smeri pisanja zagotavlja aplikacija.
Poleg tega Unicode podpira kombinirana besedila, ki združujejo fragmente z različnimi smermi pisanja. Ta možnost se imenuje dvosmernost(Angleščina) dvosmerno besedilo, BiDi). Nekateri poenostavljeni besedilni procesorji (na primer v mobilni telefon) lahko podpira Unicode, vendar nima dvosmerne podpore. Vsi znaki Unicode so razdeljeni v več kategorij: napisani od leve proti desni, napisani od desne proti levi in napisani v kateri koli smeri. Znaki zadnje kategorije (večinoma ločila), ko so prikazani, zavzamejo smer okoliškega besedila.
Zastopani liki
Unicode vključuje skoraj vse sodobne skripte, vključno z:
drugo.
Številne zgodovinske pisave so bile dodane za akademske namene, med drugim: rune, starogrški, egipčanski hieroglifi, klinopis, majevska pisava, etruščanska abeceda.
Unicode ponuja široko paleto matematičnih in glasbenih simbolov ter piktogramov.
Vendar Unicode v osnovi izključuje logotipe podjetij in izdelkov, čeprav se pojavljajo v pisavah (na primer logotip Apple v MacRoman (0xF0) ali logotip Windows v Wingdings (0xFF)). V pisavah Unicode je treba logotipe postaviti samo v območje znakov po meri.
ISO/IEC 10646
Konzorcij Unicode tesno sodeluje z delovna skupina ISO/IEC/JTC1/SC2/WG2, ki razvija mednarodni standard 10646 (ISO /IEC 10646). Obstaja sinhronizacija med standardom Unicode in ISO/IEC 10646, čeprav vsak standard uporablja svojo terminologijo in dokumentacijski sistem.
Sodelovanje med konzorcijem Unicode in Mednarodno organizacijo za standardizacijo Mednarodna organizacija za standardizacijo, ISO ) se je začelo leta 1991 . Leta 1993 je ISO izdal DIS 10646.1. Za sinhronizacijo z njim je konzorcij odobril standard Unicode različice 1.1, ki je vključeval dodatne znake iz DIS 10646.1. Posledično so se vrednosti kodiranih znakov v Unicode 1.1 in DIS 10646.1 natančno ujemale.
Sodelovanje med obema organizacijama se je nadaljevalo tudi v prihodnje. Leta 2000 Standard Unicode 3.0 je bil sinhroniziran z ISO/IEC 10646-1:2000. Prihajajoča tretja različica ISO/IEC 10646 bo sinhronizirana z Unicode 4.0. Morda bodo te specifikacije celo objavljene kot enoten standard.
Podobno kot formata UTF-16 in UTF-32 v standardu Unicode ima standard ISO/IEC 10646 tudi dve glavni obliki kodiranja znakov: UCS-2 (2 bajta na znak, podobno kot UTF-16) in UCS-4 ( 4 bajte na znak, podobno kot UTF-32). UCS pomeni univerzalni multi-oktet(večbajtni) kodiran nabor znakov(Angleščina) univerzalni nabor kodiranih znakov z več okteti ). UCS-2 se lahko šteje za podmnožico UTF-16 (UTF-16 brez nadomestnih parov), UCS-4 pa je sinonim za UTF-32.
Predstavitvene metode
Unicode ima več oblik predstavitve. Format transformacije Unicode, UTF ): UTF-8 , UTF-16 (UTF-16BE, UTF-16LE) in UTF-32 (UTF-32BE, UTF-32LE). Za prenos po sedembitnih kanalih je bila razvita tudi oblika predstavitve UTF-7, vendar zaradi nezdružljivosti z ASCII ni bila široko uporabljena in ni bila vključena v standard. 1. aprila 2005 sta bili predlagani dve predstavitvi šale: UTF-9 in UTF-18 (RFC 4042).
Unicode UTF-8: 0x00000000 - 0x0000007F: 0xxxxxxx 0x00000080 - 0x000007FF: 110xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
Teoretično so možni, vendar niso vključeni v standard, tudi:
0x00200000 - 0x03FFFFFF: 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 0x04000000 - 0x7FFFFFFF: 11111100xxx 1xxxxx 1xxx 1xxxx 1xxxxxxxxxxxxxxxxxxxxxx
Čeprav UTF-8 omogoča, da isti znak določite na več načinov, je pravilen le najkrajši. Druge obrazce je treba iz varnostnih razlogov zavrniti.
Vrstni red bajtov
V podatkovnem toku UTF-16 se lahko visoki bajt zapiše bodisi pred nizkim bajtom (eng. UTF-16 big-endian), ali po mlajšem (eng. UTF-16 mali-endian). Podobno obstajata dve različici štiribajtnega kodiranja - UTF-32BE in UTF-32LE.
Za določitev oblike predstavitve Unicode na začetku besedilna datoteka podpis je napisan - znak U+FEFF (neprekinjeni presledek ničelne širine), imenovan tudi oznaka vrstnega reda bajtov(Angleščina) oznaka vrstnega reda bajtov, BOM ). To omogoča razlikovanje med UTF-16LE in UTF-16BE, saj znak U+FFFE ne obstaja. Ta metoda se včasih uporablja tudi za označevanje formata UTF-8, čeprav koncept endiannessa ne velja za to obliko. Datoteke, ki sledijo tej konvenciji, se začnejo s temi zaporedji bajtov:
UTF-8 EF BB BF UTF-16BE FE FF UTF-16LE FF FE UTF-32BE 00 00 FE FF UTF-32LE FF FE 00 00
Na žalost ta metoda ne razlikuje zanesljivo med UTF-16LE in UTF-32LE, saj Unicode dovoljuje znak U+0000 (čeprav se prava besedila redko začnejo z njim).
Datoteke, kodirane UTF-16 in UTF-32, ki ne vsebujejo BOM, morajo biti v bajtnem vrstnem redu big-endian (unicode.org).
Unicode in tradicionalna kodiranja
Uvedba Unicode je povzročila spremembo pristopa k tradicionalnim 8-bitnim kodiranjem. Če je bilo predhodno kodiranje nastavljeno s pisavo, ga zdaj določa korespondenčna tabela med tem kodiranjem in Unicode. Pravzaprav so 8-bitna kodiranja postala oblika predstavitve neke podmnožice Unicode. To je precej olajšalo ustvarjanje programov, ki morajo delati z veliko različnimi kodirji: zdaj, če želite dodati podporo za drugo kodiranje, morate dodati še eno tabelo za pretvorbo Unicode.
Poleg tega vam številni formati podatkov omogočajo, da vstavite kateri koli znak Unicode, tudi če je dokument napisan v starem 8-bitnem kodiranju. Na primer, v HTML-ju lahko uporabite kode ampersand.
Izvedbe
Večina sodobnih operacijskih sistemov do neke mere zagotavlja podporo Unicode.
Družina operacijskih sistemov Windows NT uporablja dvobajtno kodiranje UTF-16LE za interno predstavitev imen datotek in drugih sistemskih nizov. Sistemski klici, ki sprejemajo nizovne parametre, so na voljo v enobajtnih in dvobajtnih različicah. Več preberite v članku
 LibreOffice - večnamenski pisarniški paket
LibreOffice - večnamenski pisarniški paket Prenesite program 7zip. Programi za Windows. Kako uporabljati kontekstni meni v sistemu Windows
Prenesite program 7zip. Programi za Windows. Kako uporabljati kontekstni meni v sistemu Windows Mozilla Thunderbird (poštni odjemalec)
Mozilla Thunderbird (poštni odjemalec)