特殊なUnicode文字。 外部的に類似した数字と文字を区別する問題。
すべてのインターネットユーザーは、その機能のいずれかを構成しようとして、少なくとも一度はディスプレイに「Unicode」と書かれた単語を見ました。 あなたはそれが何であるかをこの記事を読むことによって知るでしょう。
意味
Unicodeエンコーディングは、文字エンコーディングの標準です。 これは、非営利団体UnicodeIncによって提供されました。 1991年。 この規格は、1つのドキュメントにできるだけ多くの異なるタイプの文字を組み合わせるように設計されています。 それに基づいて作成されたページには、からの文字や象形文字が含まれている可能性があります 異なる言語(ロシア語から韓国語へ)そして 数学記号..。 この場合、このエンコーディングのすべての文字は問題なく表示されます。
作成の理由
昔々、ずっと前に 統一システム「Unicode」、エンコーディングはドキュメントの作者の好みに基づいて選択されました。 このため、1つのドキュメントを読み取るために異なるテーブルを使用する必要があることがよくあります。 時々これは数回行われなければならず、それは普通のユーザーの生活を著しく複雑にしました。 すでに述べたように、1991年にこの問題の解決策は、新しいタイプの文字エンコードを提案した非営利団体UnicodeInc。によって提案されました。 これは、廃止された多様な標準を組み合わせることが意図されていました。 「Unicode」は、当時考えられなかった膨大な数の文字をサポートするツールを作成することを可能にしたエンコーディングです。 結果は多くの期待を上回りました-英語とロシア語のテキスト、ラテン語と数式の両方を同時に含む文書が登場しました。
しかし、単一のコーディングを作成する前に、当時すでに存在していた多種多様な標準のために発生した多くの問題を解決する必要がありました。 最も一般的なものは次のとおりです。
- エルフの文字、または「krakozyabry」;
- 限られた文字セット。
- エンコーディングの変換の問題。
- フォントの複製。

小さな歴史的遠足
それが80年代だと想像してみてください。 コンピュータ技術はまだそれほど普及しておらず、今日とは異なる形をしています。 当時、各OSは独自の方法で一意であり、特定のニーズに合わせて各愛好家によって変更されています。 情報交換の必要性は、世界のすべてのもののさらなる洗練に変わります。 別のOSで作成されたドキュメントを読み込もうとすると、画面に理解できない文字のセットが表示されることが多く、エンコードされたゲームが始まります。 これを迅速に行うことが常に可能であるとは限りません。また、必要なドキュメントを6か月後、またはそれ以降に開くことができる場合もあります。 情報を交換する人は、自分で換算表を作成することがよくあります。 そのため、それらの作業により、興味深い詳細が明らかになります。「私のものからあなたのものへ」とその逆の2つの方向で作成する必要があります。 マシンは計算の平凡な反転を行うことができません。これは、右側の列がソースであり、左側が結果であるためですが、その逆はありません。 使用する必要があった場合 特別な記号ドキュメントでは、最初にそれらを追加する必要があり、次に、これらの記号が「krakozyabry」にならないようにするために必要なことをパートナーに説明しました。 また、エンコーディングごとに独自のフォントを開発または実装する必要があり、その結果、OSに膨大な数の複製が作成されたことを忘れないでください。
また、フォントのページに、UTF-8、UTF-16、ANSI、UCS-2の小さな注釈が付いた10個の同一のTimes NewRomanが表示されることを想像してみてください。 普遍的な標準を開発することが不可欠であったことを今あなたは理解していますか?

「クリエーターファーザーズ」
Unicodeの起源は、1987年にゼロックスのジョーベッカーがリーコリンズとマークデービスとともに アップル普遍的な文字集合の実用的な作成の研究を始めました。 1988年8月、Joe Beckerは、16ビットの国際多言語コーディングシステムの提案案を発表しました。
数か月後、Unicodeワーキンググループは、RLGのKenWhistlerとMikeKernegan、SunMicrosystemsのGlennWright、およびその他の数人を含むように拡張され、共通のコーディング標準に関する予備作業が完了しました。

概要
Unicodeは、文字の概念に基づいています。 この定義は、特定の書き方で存在し、書記素(それらの「肖像画」)を通じて実現される抽象的な現象として理解されます。 各文字は「Unicode」で指定されます 一意のコード標準の特定のブロックに属します。 たとえば、英語とロシア語の両方のアルファベットに書記素Bがありますが、Unicodeでは2つの異なる文字に対応します。 それらに変換が適用されます。つまり、それぞれがデータベースキー、プロパティのセット、およびフルネームによって記述されます。
Unicodeの利点
Unicodeエンコーディングは、文字を「暗号化」するための文字の膨大な供給によって、他の同時代のものとは異なりました。 事実、その前身は8ビットでした。つまり、28文字をサポートしていましたが、 新しい開発すでに216文字あり、これは大きな前進でした。 これにより、ほとんどすべての既存の一般的なアルファベットをエンコードすることが可能になりました。
「Unicode」の出現により、変換テーブルを使用する必要はありませんでした。単一の標準として、それは単にそれらの必要性を排除しました。 同様に、「krakozyabry」は忘却の中に沈んでいます。単一の標準によってそれらは不可能になり、重複するフォントを作成する必要がなくなりました。
Unicodeの開発
もちろん、進歩は止まらず、最初の発表から25年が経過しました。 しかし、Unicodeエンコーディングは頑固に世界でその地位を維持しています。 多くの点で、これは、プロプライエタリ(有料)およびオープンソースソフトウェアの開発者として認識され、簡単に実装および普及するようになったという事実によって可能になりました。

同時に、今日、四半世紀前と同じUnicodeエンコーディングが利用可能であると想定するべきではありません。 オン この瞬間そのバージョンは5.х.хに変更され、エンコードされた文字の数は231に増加しました。Unicode-16(最大数が制限されているエンコード)のサポートを維持するために、より多くの文字を使用する機能は廃止されました。 216)。 開始以来、バージョン2.0.0まで、「Unicode Standard」は、含まれる文字数をほぼ2倍にしました。 機会の成長はその後も続いた。 バージョン4.0.0では、標準自体を増やす必要がありましたが、これは行われました。 その結果、「Unicode」は私たちが今日知っている形を獲得しました。

Unicodeには他に何がありますか?
シンボルの数が絶えず増加していることに加えて、それは別の便利な機能を持っています。 これはいわゆる正規化です。 ドキュメント全体を1文字ずつスクロールしてルックアップテーブルの適切なアイコンに置き換える代わりに、既存の正規化アルゴリズムの1つが使用されます。 私たちは何について話していますか?
異なるアルファベットで類似している可能性がある同じ記号の定期的なチェックで計算リソースを浪費する代わりに、特別なアルゴリズムが使用されます。 これにより、すべてのデータを何度も再チェックするのではなく、置換テーブルの別の列にある類似の文字を取り出して参照することができます。
このような4つのアルゴリズムが開発され、実装されています。 それぞれにおいて、変換は他とは異なる厳密に定義された原則に従って行われるため、それらのいずれかを最も効果的なものと名付けることはできません。 それぞれが特定のニーズに合わせて開発され、実装され、正常に使用されています。

標準の配布
その25年の歴史の中で、Unicodeエンコーディングはおそらく世界で最も広く使用されています。 プログラムとWebページもこの標準に合わせて調整されています。 今日、Unicodeがインターネットリソースの60%以上で使用されているという事実は、アプリケーションの幅広さを示している可能性があります。
これで、Unicode標準がいつ誕生したかがわかりました。 それが何であるか、あなたはまた、UnicodeIncの専門家のグループによってなされた発明の完全な重要性を知っており、理解することができるでしょう。 25年以上前。
ホスティングまたはドメインが必要ですか? ここをクリック! オンラインストアを作成しますか? ここをクリック! (Shopify)投稿を書くときに、キーボードにない文字(記号)が必要になる場合があります。そのような状況では、Unicode文字テーブルが役立ちます。 今日は検討します オンラインサービス、すべてのUnicode文字がグループ化されています..。
Unicode文字テーブル
外観の背景に興味のある方へ Unicode-ここにウィキペディアへのリンクがあります
だから私たちの興味を指定しましょう Unicode文字-これは彼らの記事や彼らのサイトでのそれらの使用です。
まず、ページに行きましょう Unicode文字サービス:


このサービスのインターフェースを少し見てみましょう。 最上部には検索フィールドがあり、探している要素の名前を入力するだけで十分です。たとえば、「矢印」または「省略記号」と入力した後、検索をクリックして結果を取得します。 。
検索の横には、ページ言語スイッチャーがあります。
以下は、頻繁にリクエストされるシンボルのリストです。おそらくその中に必要なものがあります。その場合は、シンボルをクリックして、詳細情報のあるページに移動してください。
ページの主要部分はによって占められています Unicode文字テーブル、より便利な検索のために、「制御文字」をクリックして文字のグループを選択することもできます。たとえば、ギリシャ文字を挿入する必要がある場合は「ギリシャ文字」です。
Unicode文字テーブルで必要なアイテムを見つけます
たとえば、検索を使用して「矢印」という単語を入力し、検索を押します。

検索結果ページで、必要な記号を探し、それをクリックしてページに移動します 詳細な情報彼について。
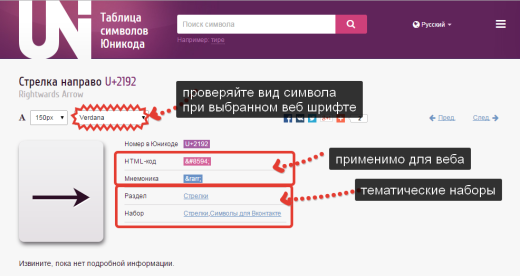
ページ上 Unicode文字 HTMLコードまたはニーモニックコードに関心があります。どちらもWebページで使用できます。このために、コードをコピーしてHTMLマークアップの適切な場所に貼り付けると、ブラウザがそれを解釈して、上のシンボルとして表示します。ページ。
Unicode文字ページでは、フォントの選択があることに注意してください。 Verdana、Arial(およびその他のWebフォント)を使用して、フォントがどのように表示されるかを常にテストしてください。 すべての文字がサポートされているわけではありません。
(0から127までのコード)、つまり 1バイトは、ラテン文字、数字、および特殊文字をエンコードします。 ロシア語の文字(キリル文字)は、16ビット(2バイト)のコードで表されます。
110XXXXX 10XXXXXX、
ここで、Xは、表に従って文字コードを配置するための2進数を示します。 UNICODE.
Unicode(英語Unicode)は、ほとんどすべての書記言語で文字を表現できるようにする文字エンコード標準です。 Unicode文字は、符号なし整数としてエンコードされます。 これらの番号は、Unicode文字コードまたは単に呼ばれます UNICODE..。 Unicodeには、コンピューターでの文字の表現のいくつかの形式があります。 UTF-8、UTF-16(UTF-16BE、UTF-16LE)およびUTF-32(UTF-32BE、UTF-32LE)..。 (英語のUnicode変換形式-UTF)。
それがどのようにエンコードされているかを検討してください UTF-8手紙 NS..。 彼女 UNICODE-104610または041616または1000001101102。 UNICODEバイナリでは、左5ビットと右6ビットの2つの部分に分割されます。 左側は符号付きのバイトに埋め込まれます 110 2バイトコード UTF-8: 110 10000.2ビットが右側に割り当てられています 10 マルチバイトコードの継続の兆候: 10 010110.最終的な文字コード NS v UTF-8そのように見えます:
110
10000 10
010110 2
またはD09616
したがって、ロシア語の文字は2回エンコードされます。最初は11ビットにエンコードされます。 UNICODE次に、16ビットUTF-8に変換します。
以下の表では、コードに加えて UNICODEと UTF-8 16進表記では、コードが与えられます UTF-8 10進表記と比較のためにエンコーディングのキリルコード CP-1251、別名 windovs-1251.
| シンボル | UNICODE | UTF-8 | CP-1251 | ||
|---|---|---|---|---|---|
| 六角 | 十 | 六角 | 十 | ||
| NS | 0410 | 1040 | D090 | 208 144 | 192 |
| NS | 0411 | 1041 | D091 | 208 145 | 193 |
| V | 0412 | 1042 | D092 | 208 146 | 194 |
| NS | 0413 | 1043 | D093 | 208 147 | 195 |
| NS | 0414 | 1044 | D094 | 208 148 | 196 |
| E | 0415 | 1045 | D095 | 208 149 | 197 |
| NS | 0416 | 1046 | D096 | 208 150 | 198 |
| Z | 0417 | 1047 | D097 | 208 151 | 199 |
| と | 0418 | 1048 | D098 | 208 152 | 200 |
| NS | 0419 | 1049 | D099 | 208 153 | 201 |
| に | 041A | 1050 | D09A | 208 154 | 202 |
| L | 041B | 1051 | D09B | 208 155 | 203 |
| NS | 041C | 1052 | D09C | 208 156 | 204 |
| NS | 041D | 1053 | D09D | 208 157 | 205 |
| O | 041E | 1054 | D09E | 208 158 | 206 |
| NS | 041F | 1055 | D09F | 208 159 | 207 |
| NS | 0420 | 1056 | D0A0 | 208 160 | 208 |
| と | 0421 | 1057 | D0A1 | 208 161 | 209 |
| NS | 0422 | 1058 | D0A2 | 208 162 | 210 |
| もつ | 0423 | 1059 | D0A3 | 208 163 | 211 |
| NS | 0424 | 1060 | D0A4 | 208 164 | 212 |
| NS | 0425 | 1061 | D0A5 | 208 165 | 213 |
| NS | 0426 | 1062 | D0A6 | 208 166 | 214 |
| NS | 0427 | 1063 | D0A7 | 208 167 | 215 |
| NS | 0428 | 1064 | D0A8 | 208 168 | 216 |
| SCH | 0429 | 1065 | D0A9 | 208 169 | 217 |
| NS | 042A | 1066 | D0AA | 208 170 | 218 |
| NS | 042B | 1067 | D0AB | 208 171 | 219 |
| NS | 042C | 1068 | D0AC | 208 172 | 220 |
| NS | 042D | 1069 | D0AD | 208 173 | 221 |
| NS | 042E | 1070 | D0AE | 208 174 | 222 |
| わたし | 042F | 1071 | D0AF | 208 175 | 223 |
| NS | 0430 | 1072 | D0B0 | 208 176 | 224 |
| NS | 0431 | 1073 | D0B1 | 208 177 | 225 |
| v | 0432 | 1074 | D0B2 | 208 178 | 226 |
| NS | 0433 | 1075 | D0B3 | 208 179 | 227 |
| NS | 0434 | 1076 | D0B4 | 208 180 | 228 |
| e | 0435 | 1077 | D0B5 | 208 181 | 229 |
| NS | 0436 | 1078 | D0B6 | 208 182 | 230 |
| NS | 0437 | 1079 | D0B7 | 208 183 | 231 |
| と | 0438 | 1080 | D0B8 | 208 184 | 232 |
| NS | 0439 | 1081 | D0B9 | 208 185 | 233 |
| に | 043A | 1082 | D0BA | 208 186 | 234 |
| l | 043B | 1083 | D0BB | 208 187 | 235 |
| NS | 043C | 1084 | D0BC | 208 188 | 236 |
| NS | 043D | 1085 | D0BD | 208 189 | 237 |
| O | 043E | 1086 | D0BE | 208 190 | 238 |
| NS | 043F | 1087 | D0BF | 208 191 | 239 |
| NS | 0440 | 1088 | D180 | 209 128 | 240 |
| と | 0441 | 1089 | D181 | 209 129 | 241 |
| NS | 0442 | 1090 | D182 | 209 130 | 242 |
| で | 0443 | 1091 | D183 | 209 131 | 243 |
| NS | 0444 | 1092 | D184 | 209 132 | 244 |
| NS | 0445 | 1093 | D185 | 209 133 | 245 |
| NS | 0446 | 1094 | D186 | 209 134 | 246 |
| NS | 0447 | 1095 | D187 | 209 135 | 247 |
| NS | 0448 | 1096 | D188 | 209 136 | 248 |
| SCH | 0449 | 1097 | D189 | 209 137 | 249 |
| NS | 044A | 1098 | D18A | 209 138 | 250 |
| NS | 044B | 1099 | D18B | 209 139 | 251 |
| NS | 044C | 1100 | D18C | 209 140 | 252 |
| NS | 044D | 1101 | D18D | 209 141 | 253 |
| NS | 044E | 1102 | D18E | 209 142 | 254 |
| わたし | 044F | 1103 | D18F | 209 143 | 255 |
| 一般規則外の記号 | |||||
| ヨ | 0401 | 1025 | D001 | 208 101 | 168 |
| e | 0451 | 1025 | D191 | 209 145 | 184 |
デザインにアイコンを追加する必要がある場合もありますが、追加の画像やFont Awesomeのようなアイコンフォント全体を挿入したくないですか? それから私達はあなたに良いニュースを持っています-あなたのブラウザですでに利用可能なアイコンとシンボルの広範なライブラリがあります。 それはUnicodeと呼ばれ、それを割り当てる標準です 一意の識別子増え続けるシンボルとアイコンの数(現在は110,000を超える)。
ただし、これは、数十万のアイコンを選択できるという意味ではありません。 それはそれらをレンダリングするブラウザに依存し、これを行うためにシステムにインストールされているフォントを使用します。 この記事では、Windows、Linux、OS X、Android、およびIOSで使用できるいくつかの文字セットを収集しました。 あなたは今日あなたのデザインでそれらを使うことができます!
ヒント:これは、エンコーディングとUnicodeについて知っておくべきことすべてを説明しています。これは、すべてのソフトウェア開発者が読むことをお勧めします。
これらのアイコンの使用方法
以下の表に示されているアイコンは、アルファベットの文字であるかのようにコピーして貼り付けることができる一般的な記号です。 ただし、HTML / CSSファイルの保存に使用されるエンコーディングの場合 UTF-8ではありませんそれらは表示されません。 これが、常に機能するHTMLエスケープコードを導入した理由です。 これらのアイコンを使用するために必要なことは次のとおりです:
- あなたが好きなアイコンを見つけてください。 大小のプレビューを提供しています。
- コードをコピーします。
- プレーンテキストとしてHTMLに貼り付けます。 CSSでは、それらをプロパティ値として使用できます コンテンツ..。 JS、PHP、およびその他のプログラミング言語では、文字列のプレーンテキストとして使用できます。
- 通常のテキストと同じように、フォントサイズ、色、テキスト、シャドウを設定することで、アイコンをカスタマイズできます。
アイコン
| 名前 | プレビュー | コード | |
|---|---|---|---|
| スマイリー | ☺ | ☺ | ☺ |
| 警告サイン | ⚠ | ⚠ | ⚠ |
| 熱水泉 | ♨ | ♨ | ♨ |
| 車椅子 | ♿ | ♿ | ♿ |
| リサイクル | ♻ | ♻ | ♻ |
| エイトボール | ➑ | ➑ | ➑ |
| 高電圧 | ⚡ | ⚡ | ⚡ |
| 白い星 | ☆ | ☆ | ☆ |
| 黒い星 | ★ | ★ | ★ |
| 白い心 | ♡ | ♡ | ♡ |
| 邪険な心 | ❤ | ❤ | ❤ |
| コーヒー | ☕ | ☕ | ☕ |
| 飛行機 | ✈ | ✈ | ✈ |
| 砂時計 | ⌛ | ⌛ | ⌛ |
| 時計 | ⌚ | ⌚ | ⌚ |
| 黒はさみ | ✂ | ✂ | ✂ |
| 白いはさみ | ✄ | ✄ | ✄ |
| クラウン | ♕ | ♕ | ♕ |
| アンカー | ⚓ | ⚓ | ⚓ |
| クロス | ✝ | ✝ | ✝ |
| 白黒の円 | ◑ | ◑ | ◑ |
| 八分音符 | ♪ | ♪ | ♪ |
| ビーム八分音符 | ♫ | ♫ | ♫ |
| 4つのバルーンスポークアスタリスク | ✣ | ✣ | ✣ |
| 丸で囲んだ白い星 | ✪ | ✪ | ✪ |
| 白い星 | ✰ | ✰ | ✰ |
| 白い四芒星 | ✧ | ✧ | ✧ |
| 黒の四芒星 | ✦ | ✦ | ✦ |
| 投票箱のチェック | ☑ | ☑ | ☑ |
| チェックマーク | ✔ | ✔ | ✔ |
| クロスマーク | ✘ | ✘ | ✘ |
| 鉛筆 | ✎ | ✎ | ✎ |
| 手書きの手 | ✍ | ✍ | ✍ |
| 女性 | ♀ | ♀ | ♀ |
| 男 | ♂ | ♂ | ♂ |
| 黒い電話 | ☎ | ☎ | ☎ |
| 白い電話 | ☏ | ☏ | ☏ |
| 封筒 | ✉ | ✉ | ✉ |
| 電話の場所 | ✆ | ✆ | ✆ |
Unicode矢印
| 名前 | プレビュー | コード | |
|---|---|---|---|
| 左向き矢印 | ← | ← | ← |
| 右向き矢印 | → | → | → |
| 上向き矢印 | |||
| 下向き矢印 | ↓ | ↓ | ↓ |
| 左右矢印 | ↔ | ↔ | ↔ |
| 上向き下向き矢印 | ↕ | ↕ | ↕ |
| 右矢印と左矢印 | ⇄ | ⇄ | ⇄ |
| 上下の矢印 | ⇅ | ⇅ | ⇅ |
| 左下90度矢印 | ↲ | ↲ | ↲ |
| 右下90度矢印 | ↳ | ↳ | ↳ |
| 左上90度矢印 | ↰ | ↰ | ↰ |
| 右上90度矢印 | ↱ | ↱ | ↱ |
| ノースウェストアロートゥコーナー | ⇱ | ⇱ | ⇱ |
| 南東の矢から角へ | ⇲ | ⇲ | ⇲ |
| バーへの左向き矢印 | ⇤ | ⇤ | ⇤ |
| バーへの右向き矢印 | ⇥ | ⇥ | ⇥ |
| 反時計回りの半円矢印 | ↶ | ↶ | ↶ |
| 時計回りの半円矢印 | ↷ | ↷ | ↷ |
| 反時計回りの円の矢印 | ↺ | ↺ | ↺ |
| 時計回りの円の矢印 | ↻ | ↻ | ↻ |
| 頭の広い右向き矢印 | ➔ | ➔ | ➔ |
| 下向きジグザグアロー | ↯ | ↯ | ↯ |
| 北西の矢印 | ↖ | ↖ | ↖ |
| 重い南東の矢印 | ➘ | ➘ | ➘ |
| 重い右向き矢印 | ➙ | ➙ | ➙ |
| 重い北東の矢印 | ➚ | ➚ | ➚ |
| 破線の右向き矢印 | ➟ | ➟ | ➟ |
| 点線の左向き矢印 | ⇠ | ⇠ | ⇠ |
| 黒の右向きの矢じり | ➤ | ➤ | ➤ |
| 左向きの白い矢印 | ⇦ | ⇦ | ⇦ |
| 右向きの白い矢印 | ⇨ | ⇨ | ⇨ |
| 左角引用符 | « | « | « |
| 直角引用符 | » | » | » |
| 右ブラックポインター | |||
| 左の黒いポインター | ◀ | ◀ | ◀ |
| アップブラックポインター | ▲ | ▲ | ▲ |
| ダウンブラックポインター | ▼ | ▼ | ▼ |
| 右の白いポインター | ▷ | ▷ | ▷ |
| 左の白いポインター | ◁ | ◁ | ◁ |
| ホオジロザメ | △ | △ | △ |
| ダウンホワイトポインター | ▽ | ▽ | ▽ |
| 弓矢 | ➴ | ➴ | ➴ |
Unicodeの特殊文字
Unicode通貨
天気アイコン
| 名前 | プレビュー | コード | |
|---|---|---|---|
| 程度 | ° | ° | ° |
| 小さな太陽 | ☀ | ☀ | ☀ |
| 大きな太陽 | ☼ | ☼ | ☼ |
| クラウド | ☁ | ☁ | ☁ |
| 傘 | ☔ | ☔ | ☔ |
| スノーフレーク1 | ❆ | ❆ | ❆ |
| スノーフレーク2 | ❅ | ❅ | ❅ |
| スノーフレーク3 | ❄ | ❄ | ❄ |
Unicodeポインタ
| 名前 | プレビュー | コード | |
|---|---|---|---|
| ポインター左黒 | ☚ | ☚ | ☚ |
| ポインター右黒 | ☛ | ☛ | ☛ |
| ポインター左白 | ☜ | ☜ | ☜ |
| ホワイトポインター | ☝ | ☝ | ☝ |
| ポインター右白 | ☞ | ☞ | ☞ |
| ポインターダウンホワイト | ☟ | ☟ | ☟ |
干支はUnicodeでサインします
| 名前 | プレビュー | コード | |
|---|---|---|---|
| 牡羊座 | ♈ | ♈ | ♈ |
| おうし座 | ♉ | ♉ | ♉ |
| 双子 | ♊ | ♊ | ♊ |
| 癌 | ♋ | ♋ | ♋ |
| ライオン | ♌ | ♌ | ♌ |
| 乙女座 | ♍ | ♍ | ♍ |
| はかり | ♎ | ♎ | ♎ |
| サソリ | ♏ | ♏ | ♏ |
| 射手座 | ♐ | ♐ | ♐ |
| 山羊座 | ♑ | ♑ | ♑ |
| 水瓶座 | ♒ | ♒ | ♒ |
| 魚類 | ♓ | ♓ | ♓ |
Unicodeカード文字
| 名前 | プレビュー | コード | |
|---|---|---|---|
| クラブブラック | ♠ | ♠ | ♠ |
| ハーツブラック | ♥ | ♥ | ♥ |
| ダイヤモンドブラック | ♦ | ♦ | ♦ |
| スペードブラック | ♣ | ♣ | ♣ |
| クラブホワイト | ♤ | ♤ | ♤ |
| ハーツホワイト | ♡ | ♡ | ♡ |
| ホワイトダイヤモンド | ♢ | ♢ | ♢ |
| スペードホワイト | ♧ | ♧ | ♧ |
ユニコードのチェスの駒
| 名前 | プレビュー | コード | |
|---|---|---|---|
| キングホワイト | ♔ | ♔ | ♔ |
| クイーンホワイト | ♕ | ♕ | ♕ |
| 白く見える | ♖ | ♖ | ♖ |
| ホワイト司教 | ♗ | ♗ | ♗ |
| ナイトホワイト | ♘ | ♘ | ♘ |
| ポーンホワイト | ♙ | ♙ | ♙ |
| キングブラック | ♚ | ♚ | ♚ |
| クイーンブラック | ♛ | ♛ | ♛ |
| ルークブラック | ♜ | ♜ | ♜ |
| ブラック司教 | ♝ | ♝ | ♝ |
| ナイトブラック | ♞ | ♞ | ♞ |
| ポーンブラック | ♟ | ♟ | ♟ |
ダイスの神
| 名前 | プレビュー | コード | |
|---|---|---|---|
| ダイスロール1 | ⚀ | ⚀ | ⚀ |
| ダイスロール2 | ⚁ | ⚁ | ⚁ |
| ダイスロール3 | ⚂ | ⚂ | ⚂ |
| ダイスロール4 | ⚃ | ⚃ | ⚃ |
| ダイスロール5 | ⚄ | ⚄ | ⚄ |
| ダイスロール6 | ⚅ | ⚅ | ⚅ |
Unicode数学記号
| 名前 | プレビュー | コード | |
|---|---|---|---|
| インフィニティ | ∞ | ∞ | ∞ |
| プラスマイナス | ± | ± | ± |
| 以下以下 | ≤ | ≤ | ≤ |
| 以上-以上 | ≥ | ≥ | ≥ |
| 等しくない | ≠ | ≠ | ≠ |
| 分割 | ÷ | ÷ | ÷ |
| 掛け算x | × | × | × |
| 重い掛け算x | ✖ | ✖ | ✖ |
| 上付き文字1 | ¹ | ¹ | ¹ |
| 上付き文字2 | ² | ² | ² |
| 上付き文字3 | ³ | ³ | ³ |
| サークルプラス | ⊕ | ⊕ | ⊕ |
| 円の掛け算 | ⊗ | ⊗ | ⊗ |
| 論理積 | ∧ | ∧ | ∧ |
| 論理OR | ∨ | ∨ | ∨ |
| デルタ | ∆ | ∆ | ∆ |
| パイ | ∏ | ∏ | ∏ |
| シグマ(SUM) | ∑ | ∑ | ∑ |
| オメガ | Ω | Ω | Ω |
| 空集合 | ∅ | ∅ | ∅ |
| 角度 | ∠ | ∠ | ∠ |
| 平行 | ∥ | ∥ | ∥ |
| 垂直 | ⊥ | ⊥ | ⊥ |
| ほぼ等しい | ≈ | ≈ | ≈ |
| 三角形 | △ | △ | △ |
| サークル | ○ | ○ | ○ |
| 四角 | □ | □ | □ |
分数
| 名前 | プレビュー | コード | |
|---|---|---|---|
| 4分の1(1/4) | ¼ | ¼ | ¼ |
| 半分(1/2) | ½ | ½ | ½ |
| 4分の3(3/4) | ¾ | ¾ | ¾ |
| 3分の1(1/3) | ⅓ | ⅓ | ⅓ |
| 3分の2(2/3) | ⅔ | ⅔ | ⅔ |
| ワンエイト(1/8) | ⅛ | ⅛ | ⅛ |
| スリーエイト(3/8) | ⅜ | ⅜ | ⅜ |
| ファイブエイト(5/8) | ⅝ | ⅝ | ⅝ |
| セブンエイト(7/8) | ⅞ | ⅞ | ⅞ |
Unicodeのローマ数字
| 名前 | プレビュー | コード | |
|---|---|---|---|
| ローマ数字1 | Ⅰ | Ⅰ | Ⅰ |
| ローマ数字2 | Ⅱ | Ⅱ | Ⅱ |
| ローマ数字3 | Ⅲ | Ⅲ | Ⅲ |
| ローマ数字4 | Ⅳ | Ⅳ | Ⅳ |
| ローマ数字5 | Ⅴ | Ⅴ | Ⅴ |
| ローマ数字6 | Ⅵ | Ⅵ | Ⅵ |
| ローマ数字セブン | Ⅶ | Ⅶ | Ⅶ |
| ローマ数字エイト | Ⅷ | Ⅷ | Ⅷ |
| ローマ数字ナイン | Ⅸ | Ⅸ | Ⅸ |
| ローマ数字テン | Ⅹ | Ⅹ | Ⅹ |
| ローマ数字イレブン | Ⅺ | Ⅺ | Ⅺ |
| ローマ数字12 | Ⅻ | Ⅻ | Ⅻ |
これらのシンボルのレンダリングにはいくつかの違いがあります オペレーティングシステム..。 これは、使用されているさまざまなフォントファミリが原因です。 さらに、iOSとAndroidは一部のUnicode文字を絵文字に置き換えているため、追加された文字をチェックして、それが発生せず、アイコンが意図したとおりに表示されていることを確認してください。
非負の整数を表すコード空間の要素。 エンコーディングのファミリは、UCSコードのシーケンスのマシン表現を定義します。
Unicodeコードはいくつかの領域に分かれています。 U +0000からU + 007Fまでのコードのある領域には、対応するコードのASCII文字が含まれています。 次は、さまざまなスクリプトの文字、句読点、技術記号の領域です。 一部のコードは、将来の使用のために予約されています。 キリル文字の下に、コードがU +0400からU + 052F、U + 2DE0からU + 2DFF、U + A640からU + A69Fの文字の領域が割り当てられます(Unicodeのキリル文字を参照)。
Unicodeの作成と開発の前提条件
多くのコンピュータシステム(Windows NTなど)では、固定の16ビット文字がすでにデフォルトのエンコーディングとして使用されていたため、すべての最も重要な文字を最初の65,536桁(いわゆる英語)内でのみエンコードすることにしました。 基本的な多言語平面、BMP)。 残りのスペースは「追加の文字」(eng。 補足文字):絶滅した言語の書記体系または非常にまれに使用される漢字、数学および音楽の記号。
古い16ビットシステムとの互換性のために、UTF-16システムが発明されました。このシステムでは、U + D800 ... U + DFFFの間隔からの位置を除いて、最初の65,536の位置が16ビットの数値として直接表示されます。残りは「代理ペア」として表されます(U + D800…U + DBFF領域からのペアの最初の要素、U + DC00…U + DFFF領域からのペアの2番目の要素)。 サロゲートペアの場合、以前は「私的使用のための文字」用に予約されていたコードスペースの一部(2048桁)が使用されました。
UTF-16は220 + 2 16 −2048(1 112 064)文字しか表示できないため、この数値がUnicodeコードスペースの最終値として選択されました。
Unicodeコード領域はバージョン2.0の早い段階で2〜16を超えて拡張されましたが、「上部」領域の最初の文字はバージョン3.1にのみ配置されていました。
Webセクターにおけるこのエンコーディングの役割は絶えず増大しており、2010年の初めにUnicodeを使用するWebサイトのシェアは約50%でした。
Unicodeバージョン
Unicode文字テーブルが変更および補充され、このシステムの新しいバージョンがリリースされると(元のUnicodeシステムにはプレーン0(2バイトコード)のみが含まれていたため、この作業は進行中です)、新しいISOドキュメントがリリースされます。 Unicodeシステムは、合計で次のバージョンに存在します。
- 1.1(ISO / IEC 10646-1:1993に準拠)、1991-1995標準。
- 2.0、2.1(同じ標準ISO / IEC 10646-1:1993に加えて、「修正」1から7および「技術正誤表」1と2)、1996標準。
- 3.0(ISO / IEC 10646-1:2000標準)2000標準。
- 3.1(ISO / IEC 10646-1:2000およびISO / IEC 10646-2:2001規格)2001規格。
- 3.2、2002標準。
- 4.0、標準2003。
- 4.01、標準2004。
- 4.1、標準2005。
- 5.0、標準2006。
- 5.1、標準2008。
- 5.2、標準2009。
- 6.0、標準2010。
- 6.1、標準2012。
- 6.2、標準2012。
コードスペース
UTF-8およびUTF-32表記形式では、最大2,331(2,147,483,648)のコードポイントをエンコードできますが、UTF-16との互換性のために1,112,064のみを使用することが決定されました。 ただし、これでも十分です。現在(バージョン6.0では)、110,000未満のコードポイントが使用されています(109,242のグラフィックと273の他のシンボル)。
コードスペースは17に分割されます 飛行機各216(65536)文字。 ゼロ平面はと呼ばれます 基本、最も一般的なスクリプトの記号が含まれています。 最初のプレーンは主に歴史的なスクリプトに使用され、2番目のプレーンはめったに使用されないCJK文字用に使用され、3番目のプレーンは古風な漢字用に予約されています。 飛行機15と16は私的使用のために予約されています。
指示する Unicode文字「U + xxxx"(コード0 ... FFFFの場合)、または" U + xxxxx"(コード10000 ... FFFFFの場合)、または" U + xxxxxx"(コード100000 ... 10FFFFの場合)、ここで xxx-16進数。 たとえば、文字「i」(U + 044F)のコードは044F = 1103です。
コーディングシステム
ユニバーサルコーディングシステム(Unicode)は、グラフィックシンボルのセットであり、テキストデータをコンピュータで処理するためにそれらをエンコードする方法です。
グラフィックシンボルは、画像が表示されるシンボルです。 グラフィカル文字は、制御文字や書式設定文字とは対照的です。
グラフィックシンボルには、次のグループが含まれます。
- サポートされているアルファベットの少なくとも1つに含まれる文字。
- 数字;
- 句読点;
- 特別な記号(数学、技術、表意文字など);
- セパレータ。
Unicodeは、テキストを線形表現するためのシステムです。 追加の上付き文字または下付き文字がある文字は、特定の規則に従って作成された一連のコード(複合文字)または単一の文字(モノリシックバージョン、合成済み文字)として表すことができます。
文字の変更
基本文字「I」(U + 0418)および変更文字「」(U + 0306)の形式での文字「Y」(U + 0419)の表現
Unicodeのグラフィック文字は、拡張と非拡張(幅なし)に分けられます。 拡張されていない文字は、表示時に行のスペースを占有しません。 これらには、特にアクセント記号やその他の発音区別符号が含まれます。 拡張文字と非拡張文字の両方に独自のコードがあります。 拡張シンボルは、基本(eng)とも呼ばれます。 基本文字)、および拡張されていないもの-変更(eng。 文字を組み合わせる); 後者は独立して会うことはできません。 たとえば、文字「á」は、基本文字「a」(U + 0061)と修飾子文字「́」(U + 0301)のシーケンスとして、またはモノリシック文字「á」(U + 00C1)。
特殊なタイプの変更文字は、スタイルセレクター(eng。 異体字セレクター)。 それらは、そのようなバリアントが定義されているシンボルにのみ適用されます。 バージョン5.0では、シリーズのスタイルオプションが定義されています 数学記号、伝統的なモンゴルのアルファベットの記号とモンゴルの正方形の文字の記号。
正規化フォーム
同じ記号を表現できるので 異なるコード、処理が複雑になることがありますが、テキストを特定の標準形式にするように設計された正規化プロセスがあります。
Unicode標準では、次の4つの形式のテキスト正規化が定義されています。
- 正規化フォームD(NFD)-正規分解。 テキストをこの形式に変換するプロセスでは、分解テーブルに従って、すべての複合文字が再帰的にいくつかの複合文字に置き換えられます。
- 正規化フォームC(NFC)は、正規分解とそれに続く正規合成です。 最初に、テキストがフォームDに縮小され、その後、正規の構成が実行されます。テキストは最初から最後まで処理され、次のルールに従います。
- S記号は イニシャル Unicode文字ベースで変更クラスがゼロの場合。
- 最初の文字Sで始まる文字のシーケンスでは、SとCの間に最初の文字であるかCと同じかそれ以上の変更クラスを持つ文字Bがある場合にのみ、文字CはSからブロックされます。ルールは、正規分解を経た文字列にのみ適用されます。
- 主要なコンポジットは、Unicode文字ベースで正規分解された文字です(またはハングルの正規分解であり、例外リストには含まれていません)。
- シーケンスと標準的に同等なプライマリコンポジットZが存在する場合に限り、X文字をY文字とプライマリアラインメントできます。
- 次のC文字が最後に検出された最初の基本文字Lによってブロックされておらず、正常に整列できる場合、LはL-Cコンポジットに置き換えられ、Cは削除されます。
- 正規化フォームKD(NFKD)-互換性のある分解。 この形式にキャストすると、すべての複合文字は、正規のUnicode分解マップと互換性のある分解マップの両方を使用して置き換えられ、その後、結果は正規の順序で配置されます。
- 正規化形式KC(NFKC)-互換性のある分解とそれに続く カノニカル構成。
「構成」および「分解」という用語は、それぞれ、記号の構成部分への接続または分解を意味します。
の例
| ソーステキスト | NFD | NFC | NFKD | NFKC |
|---|---|---|---|---|
| フランス語 | フラン\ u0327ais | フラン\ xe7ais | フラン\ u0327ais | フラン\ xe7ais |
| A、E、Y | \ u0410、\ u0401、\ u0419 | \ u0410、\ u0415 \ u0308、\ u0418 \ u0306 | \ u0410、\ u0401、\ u0419 | |
| が | \ u304b \ u3099 | \ u304c | \ u304b \ u3099 | \ u304c |
| ヘンリー4世 | ヘンリー4世 | ヘンリー4世 | ヘンリー4世 | ヘンリー4世 |
| ヘンリーⅣ | ヘンリー\ u2163 | ヘンリー\ u2163 | ヘンリー4世 | ヘンリー4世 |
双方向の手紙
Unicode標準は、左から右の両方向(eng。 左から右、LTR)、および右から左への書き込み(eng。 右から左、RTL)-たとえば、アラビア語とヘブライ語の文字。 どちらの場合も、文字は「自然な」順序で格納されます。 文字の望ましい方向を考慮したそれらの表示は、アプリケーションによって提供されます。
さらに、Unicodeは、文字の異なる方向でフラグメントを組み合わせる結合テキストをサポートします。 この機能はと呼ばれます 双方向性(eng。 双方向テキスト、BiDi)。 いくつかの簡略化されたテキストプロセッサ(たとえば、 携帯電話)Unicodeはサポートできますが、双方向サポートはサポートできません。 すべてのUnicode文字は、左から右に書かれる、右から左に書かれる、および任意の方向に書かれるといういくつかのカテゴリに分類されます。 後者のカテゴリの記号(主に句読点)は、表示されると、周囲のテキストの方向を取ります。
注目のシンボル
Unicodeには、次のような事実上すべての最新のスクリプトが含まれています。
他の。
学術目的のために、ルーン文字、古代ギリシャ語、エジプトの象形文字、楔形文字、マヤ文字、エトルリア文字など、多くの歴史的な文字が追加されています。
Unicodeは、数学および音楽の記号と絵文字を幅広く提供します。
ただし、Unicodeには基本的に会社と製品のロゴは含まれていませんが、フォントには含まれています(たとえば、MacRomanエンコーディングのAppleロゴ(0xF0)やWingdingsフォントのWindowsロゴ(0xFF))。 Unicodeフォントでは、ロゴはカスタム文字領域にのみ配置する必要があります。
ISO / IEC 10646
ユニコードコンソーシアムは緊密に連携しています ワーキンググループ ISO / IEC / JTC1 / SC2 / WG2、これは国際規格10646(ISO / IEC 10646)を開発しています。 Unicode標準とISO / IEC 10646の間で同期が確立されますが、各標準は独自の用語とドキュメントシステムを使用します。
ユニコードコンソーシアムと国際標準化機構(eng。 国際標準化機構、ISO )1991年に始まりました。 1993年、ISOはDIS10646.1標準を発行しました。 これと同期するために、コンソーシアムはUnicode標準のバージョン1.1を承認しました。これにより、DIS10646.1から文字が追加されました。 その結果、Unicode1.1とDIS10646.1でエンコードされた文字の値はまったく同じです。
今後も両団体の連携は継続していきます。 2000年に Unicode標準 3.0はISO / IEC 10646-1:2000と同期されています。 ISO / IEC 10646の次の第3バージョンは、Unicode4.0と同期されます。 おそらく、これらの仕様は単一の標準として公開されることさえあります。
Unicode標準のUTF-16およびUTF-32形式と同様に、ISO / IEC 10646標準にも、UCS-2(UTF-16と同様に1文字あたり2バイト)とUCS-4の2つの主要な文字エンコード形式があります。 (UTF-32と同様に、1文字あたり4バイト)。 UCSは意味します ユニバーサルマルチオクテット(マルチバイト) コード化された文字セット(eng。 ユニバーサルマルチオクテットコード化文字セット )。 UCS-2はUTF-16(代理ペアのないUTF-16)のサブセットと見なすことができ、UCS-4はUTF-32の同義語です。
プレゼンテーション方法
Unicodeにはいくつかの表現形式があります(eng。 Unicode変換形式、UTF ):UTF-8、UTF-16(UTF-16BE、UTF-16LE)およびUTF-32(UTF-32BE、UTF-32LE)。 UTF-7形式も7ビットチャネルを介した送信用に開発されましたが、ASCIIとの互換性がないため、普及せず、標準に含まれていませんでした。 2005年4月1日、UTF-9とUTF-18(RFC 4042)の2つのユーモラスな提出物が提案されました。
Unicode UTF-8:0x00000000-0x0000007F:0xxxxxxx 0x00000080-0x000007FF:110xxxxx 10xxxxxx 0x00000800-0x0000FFFF:1110xxxx 10xxxxxx 10xxxxxx 0x00010000-0x001FFFFF:11110xxx 10xxxxxx 10xxxxxx 10xxxx
理論的には可能ですが、標準には含まれていません。
0x00200000-0x03FFFFFF:111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 0x04000000-0x7FFFFFFF:1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
UTF-8ではいくつかの方法で同じ文字を指定できますが、正しいのは最も短い文字だけです。 残りのフォームは、セキュリティ上の理由から拒否する必要があります。
バイトオーダー
UTF-16データストリームでは、上位バイトは下位バイトの前に書き込むことができます(eng。 UTF-16ビッグエンディアン)、または若い後(eng。 UTF-16リトルエンディアン)。 同様に、4バイトエンコーディングにはUTF-32BEとUTF-32LEの2つのバリエーションがあります。
最初にUnicode表現のフォーマットを定義するには テキストファイル署名が書かれています-文字U + FEFF(幅がゼロのノーブレークスペース)、別名 バイト順マーク(eng。 バイト順マーク、BOM )。 これにより、U + FFFE文字が存在しないため、UTF-16LEとUTF-16BEを区別できます。 バイト順序の概念はこの形式には適用されませんが、UTF-8形式を示すために使用されることもあります。 この規則に従うファイルは、次のバイトシーケンスで始まります。
UTF-8 EF BB BF UTF-16BE FE FF UTF-16LE FF FE UTF-32BE 00 00 FE FF UTF-32LE FF FE 00 00
残念ながら、この方法ではUTF-16LEとUTF-32LEを確実に区別できません。これは、文字U + 0000がUnicodeで許可されているためです(ただし、実際のテキストがUTF-16LEで始まることはめったにありません)。
BOMを含まないUTF-16およびUTF-32エンコーディングのファイルは、ビッグエンディアン(unicode.org)のバイト順である必要があります。
Unicodeおよび従来のエンコーディング
Unicodeの導入により、従来の8ビットエンコーディングへのアプローチが変わりました。 以前にエンコーディングがフォントによって指定されていた場合、現在はこのエンコーディングとUnicodeの間の対応テーブルによって指定されています。 実際、8ビットエンコーディングはUnicodeのサブセットを表す形式になっています。 これにより、多くの異なるエンコーディングで動作する必要のあるプログラムの作成がはるかに簡単になりました。もう1つのエンコーディングのサポートを追加するには、別のUnicodeルックアップテーブルを追加するだけです。
さらに、多くのデータ形式では、ドキュメントが古い8ビットエンコーディングで記述されている場合でも、任意のUnicode文字を挿入できます。 たとえば、HTMLでアンパサンドコードを使用できます。
実装
最新のオペレーティングシステムのほとんどは、ある程度のUnicodeサポートを提供します。
Windows NTファミリのオペレーティングシステムでは、ファイル名やその他のシステム文字列の内部表現に2バイトのUTF-16LEエンコーディングが使用されます。 文字列パラメータを使用するシステムコールは、シングルバイトとダブルバイトのバリエーションで利用できます。 詳細については、記事を参照してください
 iPhoneの音量ボタンと電源ボタンの反発-結婚かどうか?
iPhoneの音量ボタンと電源ボタンの反発-結婚かどうか? ネットワークカードにケーブルが表示されない:問題を解決するための手順インターネットケーブルが機能しない場合の対処方法
ネットワークカードにケーブルが表示されない:問題を解決するための手順インターネットケーブルが機能しない場合の対処方法 StoCardとウォレット:アプリケーションからの割引カード
StoCardとウォレット:アプリケーションからの割引カード