Сколько бит в кодировке unicode. Единицы измерения объема данных и ёмкости памяти: килобайты, мегабайты, гигабайты…. Стандарт кодирования символов Unicode
Кодирование информации
Любые числа (в определенных пределах) в памяти компьютера кодируются числами двоичной системы счисления. Для этого существуют простые и понятные правила перевода. Однако на сегодняшний день компьютер используется куда шире, чем в роли исполнителя трудоемких вычислений. Например, в памяти ЭВМ хранятся текстовая и мультимедийная информация. Поэтому возникает первый вопрос:
Каждый символ кодируется с 1 по 4 байта. Заменяющие символы используют 4 байта и, следовательно, требуют дополнительного хранения. Каждый символ кодируется как минимум 4 байтами. Кроме того, вы можете использовать инструмент преобразования для автоматического преобразования. Как уже сказано, это стандарт, который хорошо подходит американцам. Он колеблется от 0 до 127, причем первые 32 и последние считаются контрольными, остальные - «печатными символами», то есть признанными людьми. Он может быть представлен только 7 битами, хотя обычно используется один байт.
Как в памяти компьютера хранятся символы (буквы)?
Каждая буква принадлежит определенному алфавиту, в котором символы следуют друг за другом и, следовательно, могут быть пронумерованы последовательными целыми числами. Каждой букве можно сопоставить целое положительное число и назвать его кодом символа . Именно этот код будет храниться в памяти компьютера, а при выводе на экран или бумагу «преобразовываться» в соответствующий ему символ. Чтобы отличить представление чисел от представления символов в памяти компьютера, приходится также хранить информацию о том, какие именно данные закодированы в конкретной области памяти.
В зависимости от контекста и даже времени это означает что-то другое. Так что это зависит от того, о чем вы говорите. В одиночку это мало значит. Существуют некоторые кодировки, которые используют этот акроним. Они очень сложны и почти никто не знает, как правильно использовать свою полноту, включая меня.
Но не с какой-либо другой системой кодирования символов. Это самая полная и сложная кодировка, которая существует. Некоторые влюблены в нее, а другие ненавидят ее, хотя они признают ее полезность. Человеку сложно понять, а для компьютера - иметь дело.
Соответствие букв определенного алфавита с числами-кодами формирует так называемую таблицу кодирования . Другими словами, каждый символ конкретного алфавита имеет свой числовой код в соответствии с определенной таблицей кодирования.
Однако алфавитов в мире очень много (английский, русский, китайский и др.). Поэтому следующий вопрос:
Существует сравнение между ними. Это стандарт для представления текстов, созданных консорциумом. Среди установленных ему норм - некоторые кодировки. Но на самом деле это относится к гораздо большему, чем это. Статья, которую каждый должен прочитать, даже если они не согласны со всем, что у них есть.
Поддерживаемые наборы символов разделяются на плоскости. Эти два компьютера используют разные операционные системы; то же самое происходит с набором символов, структурой и файловым форматом, которые, как правило, разные. Связь по соединению управления.
Как закодировать все используемые на компьютере алфавиты?
Для ответа на этот вопрос пойдем историческим путем.
В 60-х годах XX века в американском национальном институте стандартизации (ANSI) была разработана таблица кодирования символов, которая впоследствии была использована во всех операционных системах. Эта таблица называется ASCII (American Standard Code for Information Interchange – американский стандартный код для обмена информацией) . Чуть позже появилась расширенная версия ASCII .
Связь происходит через последовательность команд и ответов. Этот простой метод подходит для управляющего соединения, потому что мы можем отправлять по одной команде за раз. Каждая команда или ответ занимает одну строку, поэтому нам не нужно беспокоиться о формате или структуре файла. Каждая строка заканчивается двумя символами в конце.
Связь с данными. Цель и реализация соединения для передачи данных отличаются от целей, указанных в контрольном соединении. Основной факт: мы хотим передать файлы через соединение с данными. Клиент должен определить тип передаваемого файла, структуру данных и режим передачи.
В соответствие с таблицей кодирования ASCII для представления одного символа выделяется 1 байт (8 бит). Набор из 8 ячеек может принять 2 8 = 256 различных значений. Первые 128 значений (от 0 до 127) постоянны и формируют так называемую основную часть таблицы, куда входят десятичные цифры, буквы латинского алфавита (заглавные и строчные), знаки препинания (точка, запятая, скобки и др.), а также пробел и различные служебные символы (табуляция, перевод строки и др.). Значения от 128 до 255 формируют дополнительную часть таблицы, где принято кодировать символы национальных алфавитов.
Кроме того, передача должна быть подготовлена контрольным соединением, прежде чем файл может быть передан по каналу передачи данных. Проблема гетерогенности решается путем определения трех атрибутов связи: типа файла, структуры данных и режима передачи.
Файл отправляется как непрерывный поток битов без какой-либо интерпретации или кодирования. Этот формат в основном используется для передачи двоичных файлов, таких как скомпилированные программы или изображения, закодированные в 0 и 1 сек. Файл не содержит вертикальные спецификации для печати. Это означает, что файл не может быть напечатан без дополнительной обработки, потому что нет понятных символов, которые должны интерпретироваться вертикальным движением движка печати. Этот формат используется файлами, которые будут храниться и обрабатываться в будущем.
Поскольку национальных алфавитов огромное множество, то расширенные ASCII-таблицы существуют во множестве вариантов. Даже для русского языка существуют несколько таблиц кодирования (распространены Windows-1251 и Koi8-r). Все это создает дополнительные трудности. Например, мы отправляем письмо, написанное в одной кодировке, а получатель пытается прочитать ее в другой. В результате видит кракозябры. Поэтому читающему требуется применить для текста другую таблицу кодирования.
Файл можно распечатать после передачи. Страницы: файл разделен на страницы, каждый из которых правильно пронумерован и идентифицирован заголовком. Страницы могут быть сохранены или доступны, случайным образом или последовательно. Если данные представляют собой просто строку байтов, идентификация конца строки не требуется. В этом случае индикация окончания строки - это закрытие соединения данных передатчиком. Первый байт называется дескрипторным блоком; другие два байта определяют размер блока в байтах. Сжатие: если файл слишком велик, данные могут быть сжаты перед отправкой. Обычно используемый метод сжатия принимает единицу данных, которые появляются последовательно и заменяет их одним вхождением, за которым следует количество повторений. В текстовом файле много пустых пространств. В двоичном файле нулевые символы обычно сжимаются.
- Файлы: файл не имеет структуры.
- Он передается с непрерывным потоком байтов.
- Этот тип может использоваться только с текстовыми файлами.
- Цепочки: это режим по умолчанию.
- В этом случае каждому блоку предшествует 3-байтовый заголовок.
Есть и другая проблема. В алфавитах некоторых языков слишком много символов и они не помещаются в отведенные им позиции с 128 до 255 однобайтовой кодировки.
Третья проблема - что делать, если в тексте используется несколько языков (например, русский, английский и французский)? Нельзя же использовать две таблицы сразу …
Чтобы решить эти проблемы одним разом была разработана кодировка Unicode.
Многие понятия не имеют о различиях между этими наборами и придерживаются того, что близко. Деталь о кодировке состоит в том, что они являются картами для двух разных вещей. Первая - это карта числового значения, которая представляет конкретный символ.
Другие планы - дополнения, имеющие персонажи, которые дополняют функции основного плана и других «специальных», например, «эмотиконов». В этих шаблонах каждый символ плоскости кодируется только в 1 байт, и поэтому у нас есть только 256 «возможных» символов. Разумеется, мы должны удалить те, которые не являются «печатными», уменьшая диапазон.
Стандарт кодирования символов Unicode
Для решения вышеизложенных проблем в начале 90-х был разработан стандарт кодирования символов, получивший название Unicode . Данный стандарт позволяет использовать в тексте почти любые языки и символы.
В Unicode для кодирования символов предоставляется 31 бит (4 байта за вычетом одного бита). Количество возможных комбинаций дает запредельное число: 2 31 = 2 147 483 684 (т.е. более двух миллиардов). Поэтому Unicode описывает алфавиты всех известных языков, даже «мертвых» и выдуманных, включает многие математические и иные специальные символы. Однако информационная емкость 31-битового Unicode все равно остается слишком большой. Поэтому чаще используется сокращенная 16-битовая версия (2 16 = 65 536 значений), где кодируются все современные алфавиты.
И если вам нужно делать сравнения между символами, потери производительности не происходит, так как сравнение двух 8-битных, 16-битных или 32-битных значений тратит одно и то же время на современные процессоры. Значение, связанное с аббревиатурой, конечно, представляет собой размер каждой единицы последовательности, которая составляет кодировку символа. Когда код имеет больше битов, используется следующая кодировка.
Таким образом, любой символ может быть выражен с размером от 1 до 4 байтов. Это уникальный «особый» характер? Это означает, что некоторые изображения персонажей очень похожи, а иногда и избыточны. Чтобы привести еще один пример, несколько лет назад появилась шутка, в которой говорилось об изменении символа '; ' на '; ' в исходных кодах. При компиляции кода программист сошел с ума, чтобы попытаться выяснить проблему.
В Unicode первые 128 кодов совпадают с таблицей ASCII.
Начиная с конца 60-х годов, компьютеры все больше стали использоваться для обработки текстовой информации и в настоящее время большая часть персональных компьютеров в мире (и наибольшее время) занято обработкой именно текстовой информации.
ASCII - базовая кодировка текста для латиницы
Традиционно для кодирования одного символа используется количество информации, равное 1 байту , то есть I = 1 байт = 8 битов.
Для кодирования одного символа требуется 1 байт информации. Если рассматривать символы как возможные события, то можно вычислить, какое количество различных символов можно закодировать: N = 2I = 28 = 256.
Такое количество символов вполне достаточно для представления текстовой информации, включая прописные и строчные буквы русского и латинского алфавита, цифры, знаки, графические символы и пр. Кодирование заключается в том, что каждому символу ставится в соответствие уникальный десятичный код от 0 до 255 или соответствующий ему двоичный код от 00000000 до 11111111.
Таким образом, человек различает символы по их начертаниям, а компьютер - по их кодам. При вводе в компьютер текстовой информации происходит ее двоичное кодирование, изображение символа преобразуется в его двоичный код.
Пользователь нажимает на клавиатуре клавишу с символом, и в компьютер поступает определенная последовательность из восьми электрических импульсов (двоичный код символа). Код символа хранится в оперативной памяти компьютера, где занимает один байт. В процессе вывода символа на экран компьютера производится обратный процесс - декодирование, то есть преобразование кода символа в его изображение. В качестве международного стандарта принята кодовая таблица ASCII (American Standart Code for Information Interchange) Таблица стандартной части ASCII Важно, что присвоение символу конкретного кода - это вопрос соглашения, которое фиксируется в кодовой таблице. Первые 33 кода (с 0 по 32) соответствуют не символам, а операциям (перевод строки, ввод пробела и так далее). Коды с 33 по 127 являются интернациональными и соответствуют символам латинского алфавита, цифрам, знакам арифметических операций и знакам препинания. Коды с 128 по 255 являются национальными, то есть в национальных кодировках одному и тому же коду соответствуют различные символы.
К сожалению, в настоящее время существуют пять различных кодовых таблиц для русских букв (КОИ8, СР1251, СР866, Mac, ISO), поэтому тексты, созданные в одной кодировке, не будут правильно отображаться в другой.
В настоящее время широкое распространение получил новый международный стандарт Unicode, который отводит на каждый символ не один байт, а два, поэтому с его помощью можно закодировать не 256 символов, а N = 216 = 65536 различных
Юникод - появление универсальной кодировки текста (UTF 32, UTF 16 и UTF 8)
Эти тысячи символов языковой группы юго-восточной Азии никак невозможно было описать в одном байте информации, который выделялся для кодирования символов в расширенных кодировках ASCII. В результате был создан консорциум под названием Юникод (Unicode - Unicode Consortium) при сотрудничестве многих лидеров IT индустрии (те, кто производит софт, кто кодирует железо, кто создает шрифты), которые были заинтересованы в появлении универсальной кодировки текста.
Первой кодировкой текста, вышедшей под эгидой консорциума Юникод, была кодировка UTF 32 . Цифра в названии кодировки UTF 32 означает количество бит, которое используется для кодирования одного символа. 32 бита составляют 4 байта информации, которые понадобятся для кодирования одного единственного символа в новой универсальной кодировке UTF 32.
В результате чего один и то же файл с текстом, закодированный в расширенной кодировке ASCII и в кодировке UTF 32, в последнем случае будет иметь размер (весить) в четыре раза больше. Это плохо, но зато теперь у нас появилась возможность закодировать с помощью UTF 32 число символов равное двум в тридцать второй степени (миллиарды символов, которые покроют любое реально необходимое значение с колоссальным запасом).
Но многим странам с языками европейской группы такое огромное количество символов использовать в кодировке вовсе и не было необходимости, однако при использовании UTF 32 они ни за что ни про что получали четырехкратное увеличение веса текстовых документов, а в результате и увеличение объема интернет трафика и объема хранимых данных. Это много и такое расточительство себе никто не мог позволить.
В результате развития универсальной кодировки Юникод появилась UTF 16 , которая получилась настолько удачной, что была принята по умолчанию как базовое пространство для всех символов, которые у нас используются. UTF 16 использует два байта для кодирования одного символа. Например, в операционной системе Windows вы можете пройти по пути Пуск - Программы - Стандартные - Служебные - Таблица символов.
В результате откроется таблица с векторными формами всех установленных у вас в системе шрифтов. Если вы выберите в Дополнительных параметрах набор символов Юникод, то сможете увидеть для каждого шрифта в отдельности весь ассортимент входящих в него символов. Кстати, щелкнув по любому из этих символов вы сможете увидеть его двухбайтовый код в кодировке UTF 16, состоящий из четырех шестнадцатеричных цифр:
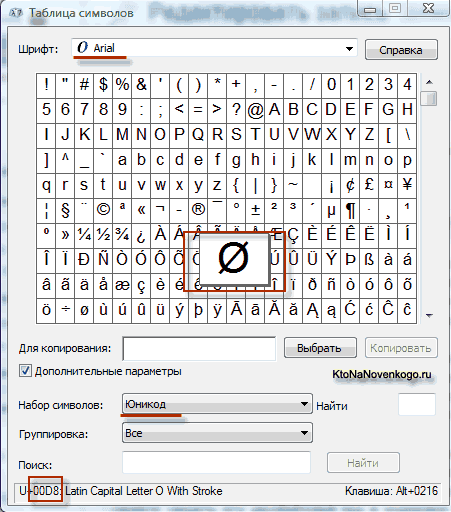
Сколько символов можно закодировать в UTF 16 с помощью 16 бит? 65 536 символов (два в степени шестнадцать) было принято за базовое пространство в Юникод. Помимо этого существуют способы закодировать с помощью UTF 16 около двух миллионов символов, но ограничились расширенным пространством в миллион символов текста.
Но даже удачная версия кодировки Юникод под названием UTF 16 не принесла особого удовлетворения тем, кто писал, допустим, программы только на английском языке, ибо у них после перехода от расширенной версии кодировки ASCII к UTF 16 вес документов увеличивался в два раза (один байт на один символ в ASCII и два байта на тот же самый символ в кодировке UTF 16). Вот именно для удовлетворения всех и вся в консорциуме Юникод было решено придумать кодировку текста переменной длины .
Такую кодировку в Юникод назвали UTF 8 . Несмотря на восьмерку в названии UTF 8 является полноценной кодировкой переменной длины, т.е. каждый символ текста может быть закодирован в последовательность длинной от одного до шести байт. На практике же в UTF 8 используется только диапазон от одного до четырех байт, потому что за четырьмя байтами кода ничего уже даже теоретически не возможно представить.
В UTF 8 все латинские символы кодируются в один байт, так же как и в старой кодировке ASCII. Что примечательно, в случае кодирования только латиницы, даже те программы, которые не понимают Юникод, все равно прочитают то, что закодировано в UTF 8. Т.е. базовая часть кодировки ASCII перешла в UTF 8.
Кириллические же символы в UTF 8 кодируются в два байта, а, например, грузинские - в три байта. Консорциум Юникод после создания кодировок UTF 16 и UTF 8 решил основную проблему - теперь у нас в шрифтах существует единое кодовое пространство. Производителям шрифтов остается только исходя из своих сил и возможностей заполнять это кодовое пространство векторными формами символов текста.
 Как вернуть старый дизайн Вконтакте — отключаем новую версию
Как вернуть старый дизайн Вконтакте — отключаем новую версию Внешняя обработка в 1с 8
Внешняя обработка в 1с 8 Лучшие смартфоны с двумя активными сим картами
Лучшие смартфоны с двумя активными сим картами