ロシア語の文字のAnsiテーブル。 エンコーディング:有用な情報と簡単な回顧展
かなり経験豊富な専門家でさえ、あるシステムの圧力または長さの特定の値が別の値のシステムの値に対応するものをすぐに教えてくれない場合があります。
に 促進するこのタスクでは、ヨーロッパとアメリカのシステムでの圧力と長さの値の比率の表を提供します 説明..。 しかし、最初に、標準自体について少し説明します。
DINドイツの標準です(の略) DeutschesInstitutfürNormungつまり、国際標準化機構-ISO(国際標準化機構)の規定の枠内で厳密に開発されたドイツ規格協会によって開発されました。
ANSI-アメリカ合衆国で採用されている標準。 を意味する 米国規格協会つまり、米国規格協会の規格です。
したがって、ANSI規格はこの機関によって決定され、はるかに 常にではない標準間 DINと ANSI正確な 適合性さまざまな分野で。
圧力単位をANSIからDINに変換する
ここではすべてが簡単です:標準の場合 ANSI数値150は圧力の反対側にあります。これは、(バルブが設計されている)公称圧力が20バール、300〜50バールなどであることを意味します。 最大値 ANSIクラス-ヨーロッパ規格によると、2500は420バールに相当します DIN.
この表を使用して、 難しくない圧力値を変換して戻す:from DIN v ANSI、私たちのエンジニアはそのような翻訳をたくさん実行する必要がありますが 頻度は低いものの.
アメリカのシステムからヨーロッパ(ロシア)への長さの単位の変換
知られているように、 アメリカ人すべてがインチとフィートで測定され、私たちと ヨーロッパ人-ミリメートル、センチメートル、メートル、つまり、世界の大多数の州のように、私たちは メトリック単位系。
インチをミリメートルに変換する方法は? 実際、これも難しいことではありません。1インチは25.4mmに等しいことを覚えておいてください。 ただし、多くの場合、小数点以下の数値 無視されたそして数えるためにそれを示します 1インチ= 25mm.
したがって、たとえば、米国の測定システムに従って流入口の断面が2インチである場合、この値を上記の規則に従って測定システムに変換すると、50 mm、より正確には、 51 mm(規則に従って50.8を丸める)..。
直径が テクニカル特徴はラテン文字でマークされています DN多くの場合、正確に示されます インチ、および圧力は文字で示されます PNそして最も頻繁に示されます バー-いずれにせよ、私たちはほとんどのようなマーキングだけを使用します 快適.
そして次の表 役立ちますあなただけでなく計算することができます 正確 1インチのミリメートル数(1000分の1ミリメートルの精度)ですが、たとえば2.5インチに何ミリメートル含まれているかを調べるのにも役立ちます。
これを行うには、列2 ""(2インチ)を見つけ、左側で1/2を探します。 合計2.5インチ= 63.501 mm、これは64 mmに切り上げることができます。たとえば、6.25インチ(つまり、6および1/4)= 158.753mmまたは159mmです。
|
| インチ ""(ミリメートル) |
|||||||
|
| ||||||||
|
| ||||||||
いくつか入力するだけでよい場合 特殊文字または文字、文字テーブルまたはキーボードショートカットを使用できます。 ASCII文字のリストについては、以下の表またはキーボードショートカットを使用した国別文字の挿入を参照してください。
ノート:
ASCII文字の挿入
ASCII文字を挿入するには、ALTキーを押したまま、文字コードを入力します。 たとえば、度記号(º)を挿入するには、Altキーを押しながら入力します。 テンキーコード0176。
ノート:
Unicode文字の挿入
重要:いくつか マイクロソフトプログラム PowerPointやInfoPathなどのOfficeは、Unicode文字コードを変換できません。 Unicode文字が必要で、Unicode文字をサポートしないプログラムのいずれかを使用している場合は、を使用して文字を入力します。これが必要になる場合があります。
ノート:
すべてのプログラムを終了します。
アイコンをダブルクリックします プログラムのインストールと削除オン コントロールパネル.
次のいずれかを実行します。
アプリケーションの場合 マイクロソフトオフィス Microsoft Officeの一部としてインストールされている場合は、 マイクロソフトオフィスフィールドで インストールされているプログラム 次にボタンを押します 交換;
もしも オフィスアプリケーション個別にインストールされた場合は、リストでその名前をクリックしてください インストールされているプログラム次にボタンを押します 変化する.
数字は、英数字ではなく、テンキーで入力する必要があります。 を押してテンキーに数字を入力する必要がある場合 NUMキーロック、これが行われていることを確認してください。
Unicodeコードを文字に変換する際に問題が発生した場合は、テンキーでコードを入力して選択し、Alt + Xを押します。
V マイクロソフトウィンドウズ XP以降のバージョンのUnicodeユニバーサルフォントは自動的にインストールされます。 Microsoft Windows 2000では、Unicodeフォントを手動でインストールする必要があります。
Microsoft Windows2000の場合
ダイアログボックスで Microsoft Office2003のインストール選択肢一つを選択してください コンポーネントを追加または削除する次にボタンを押します さらに.
選んでください 追加のカスタマイズアプリケーションボタンを押します さらに.
リストを展開する 一般的なオフィスツール.
リストを展開する 多言語サポート.
アイコンをクリックします ユニバーサルフォント目的のインストールオプションを選択します。
シンボルテーブルの使用
シンボルテーブルはMicrosoftによって組み込まれています Windowsプログラムこれにより、選択したフォントで使用可能な文字を表示できます。 シンボルテーブルを使用すると、個々のシンボルまたはシンボルのグループをクリップボードにコピーして、それらをサポートするプログラムに貼り付けることができます。
ボタンをクリックします 始める、次に選択します プログラム, 標準, サービスと 記号の表.
シンボルテーブルでシンボルを選択するには、それをクリックして、をクリックします 選択する、 クリック 右クリック記号を追加するドキュメントの場所にマウスを置き、コマンドを選択します 入れる.
一般的な文字コード
その他の文字文字については、コンピューターにインストールされている記事、ASCII文字コード、またはUnicode文字コードのスクリプト図を参照してください。
|
サイン |
サイン |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
通貨記号 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
法的記号 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
分数 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
句読点と方言の記号 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
フォームシンボル |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
一般的な発音区別符号グリフと関連する文字コードの完全なリストについては、を参照してください。
|
ブートストラップフレームワーク:高速レスポンシブレイアウト
Bootstrapフレームワークのレスポンシブレイアウトの基本に関するステップバイステップのビデオチュートリアル。
強力で実用的なツールを使用して、簡単、迅速、効率的に植字する方法を学びます。
注文して支払いを受けるためのレイアウト。
無料コース「WordPressのサイト」
WordPress CMSをマスターしたいですか?
WordPressWebサイトのデザインとレイアウトに関するチュートリアルを入手してください。
テーマの操作方法とレイアウトのスライス方法を学びます。
CMS WordPressでの描画サイトのデザイン、レイアウト、インストールに関する無料のビデオコース!
*マウスをホバーしてスクロールを一時停止します。
バックフォワード
エンコーディング:有用な情報と簡単な回顧展
この記事は、エンコーディングの問題に関する簡単な概要として書くことにしました。
一般的なエンコーディングとは何かを理解し、それらが原則としてどのように出現したかについての歴史に触れます。
それらの機能のいくつかについて説明し、エンコーディングをより意識的に操作して、いわゆるサイトに表示されないようにする瞬間についても検討します。 krakozyabrov、 NS。 判読できない文字。
じゃ、行こう ...
エンコーディングとは何ですか?
簡単に言えば、 エンコーディングは、画面に表示される特定の数値コードへの文字マッピングの表です。
それらの。 キーボードから入力する、またはモニター画面に表示される各文字は、特定のビットシーケンス(0と1)でエンコードされます。 ご存知かもしれませんが、8ビットは1バイトの情報に相当しますが、それについては後で詳しく説明します。
シンボル自体の外観は、フォントファイルによって決まります。コンピュータにインストールされているもの。 したがって、画面にテキストを表示するプロセスは、フォントを構成する特定の文字への0と1のシーケンスの一定のマッピングとして説明できます。
最新のすべてのエンコーディングの前駆細胞と見なすことができます ASCII.
この略語は 情報交換用米国標準コード(印刷可能な文字といくつかの特別なコードのためのアメリカの標準コードテーブル)。
それ シングルバイトエンコーディング、最初は128文字しか含まれていませんでした:ラテンアルファベットの文字、アラビア数字など。

その後拡張され(当初は8ビットすべてを使用していなかった)、128ではなく256(2の8乗)を使用できるようになりました。 別の文字 1バイトの情報にエンコードできます。
この改善により、ASCIIへの追加が可能になりました 国語のシンボル、既存のラテンアルファベットに加えて。
世界には多くの言語もあるという事実のために、拡張ASCIIエンコーディングには多くのオプションがあります。 あなたの多くはそのようなエンコーディングについて聞いたことがあると思います KOI8-Rも拡張ASCIIエンコーディングですロシア語の文字で動作するように設計されています。
エンコーディング開発の次のステップは、いわゆるの出現と見なすことができます ANSIエンコーディング.
実際、彼らは同じでした 拡張ASCIIバージョンただし、さまざまな疑似グラフィック要素が削除され、活版印刷の記号が追加されました。これまでは、十分な「空き領域」がありませんでした。
このようなANSIエンコーディングの例は、よく知られているものです。 Windows-1251..。 活版印刷の文字に加えて、このエンコーディングには、ロシア語に近い言語(ウクライナ語、ベラルーシ語、セルビア語、マケドニア語、ブルガリア語)のアルファベットの文字も含まれていました。
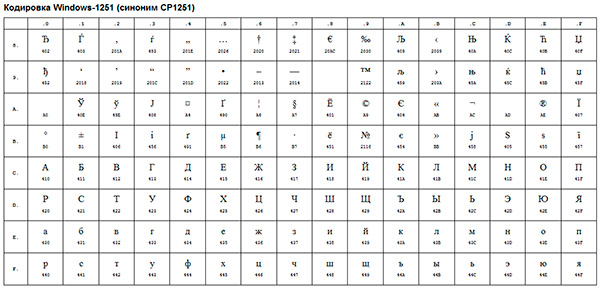
ANSIエンコーディングは総称です..。 実際、ANSIを使用する場合の実際のエンコーディングは、 オペレーティング・システムウィンドウズ。 ロシア語の場合はWindows-1251になりますが、他の言語の場合は別の種類のANSIになります。
ご存知のように、たくさんのエンコーディングと単一の標準の欠如は幸運をもたらさなかった、それがいわゆるとの頻繁な会議の理由でした krakozyabrami-読めない意味のない文字のセット。
それらの外観の理由は単純です-それは 別のエンコードテーブルを使用して、あるエンコードテーブルでエンコードされた文字を表示しようとしています.
Web開発のコンテキストでは、たとえば、次の場合にkrakozyabrasに遭遇する可能性があります。 ロシア語のテキストが、サーバーで使用されている間違ったエンコーディングで誤って保存されている.
もちろん、これは私たちが読めないテキストを得ることができる唯一のケースではありません-ここには多くのオプションがあります、特に情報が特定のエンコーディングで保存されているデータベースもあることを考えると、データベースへの接続など。
これらすべての問題の出現は、何か新しいものを生み出す動機として役立ちました。 それは、世界中のあらゆる言語をエンコードできるエンコーディングである必要がありました(結局のところ、シングルバイトエンコーディングの助けを借りて、すべての文字を記述することはできません。たとえば、中国語のすべての文字を記述することはできません。それらの256)、追加の特殊文字とタイポグラフィ。
要するに、作成する必要がありました krakozyabrovの問題を一度限り解決するユニバーサルエンコーディング.
Unicode-ユニバーサルテキストエンコーディング(UTF-32、UTF-16、およびUTF-8)
この規格自体は、1991年に非営利団体によって提案されました。 Unicodeコンソーシアム(Unicode Consortium、Unicode Inc.)、そして彼の仕事の最初の結果はエンコーディングの作成でした UTF-32.
ちなみに、略語自体 UTFを意味する Unicode変換形式(Unicode変換形式)。
このエンコーディングでは、1つの文字をエンコードするために、同じ量を使用することになっています 32ビット、 NS。 4バイトの情報。 この数値をシングルバイトエンコーディングと比較すると、簡単な結論に達します。このユニバーサルエンコーディングで1文字をエンコードするには、次のことが必要です。 4倍以上のビット、ファイルが4倍重くなります。
また、このエンコーディングを使用して記述できる可能性のある文字数がすべての妥当な制限を超えており、技術的には2の32乗に等しい数に制限されていることも明らかです。 これがファイルの重みの点で明らかにやり過ぎで無駄だったことは明らかであるため、このエンコーディングは普及していません。
彼女はに置き換えられました 新しい開発-UTF-16.
名前が示すように、このエンコーディングでは1文字がエンコードされます 32ビットではなく、16ビットのみ(つまり、2バイト)。 明らかに、これにより、任意の文字がUTF-32の2倍「軽く」なりますが、シングルバイトでエンコードされた文字の2倍「重く」なります。
UTF-16でのエンコードに使用できる文字数は、少なくとも2の16乗です。 65536文字。 UTF-16のコードスペースの最終的なサイズが100万文字以上に拡張されたことを除けば、すべてが良好なようです。
ただし、このエンコーディングは開発者のニーズを完全には満たしていませんでした。 たとえば、ラテン文字のみを使用して記述した場合、ASCIIエンコーディングの拡張バージョンからUTF-16に切り替えた後、各ファイルの重みは2倍になりました。
結果として、 普遍的なものを作成するために別の試みが行われました、そしてそれはよく知られているUTF-8エンコーディングです。
UTF-8- これは 可変文字長のマルチバイトエンコーディング..。 名前を見ると、UTF-32やUTF-16と同様に、1文字のエンコードに8ビットが使用されていると思われるかもしれませんが、そうではありません。 もっと正確に言えば、そうではありません。
これは、UTF-8が8ビット文字を使用していた古いシステムとの最高の互換性を提供するためです。 UTF-8で1文字をエンコードするために実際に使用されます 1〜4バイト(仮に、最大6バイトが可能です)。
UTF-8では、ASCIIエンコードと同様に、すべてのラテン文字が8ビットでエンコードされます。..。 つまり、ASCIIエンコーディングの基本部分(128文字)がUTF-8に移行しました。これにより、すべてが開始されたエンコーディングの普遍性を維持しながら、表現に1バイトだけを「費やす」ことができます。
したがって、最初の128文字が1バイトでエンコードされている場合、他のすべての文字は2バイト以上でエンコードされます。 特に、各キリル文字は正確に2バイトでエンコードされます。
したがって、ファイルを不必要に「均等化」することなく、表示する必要のあるすべての可能な文字をカバーできるユニバーサルエンコーディングを取得しました。
BOMの有無は?
一緒に働いた場合 テキストエディタ(コードエディタ) メモ帳++, phpDesigner, 迅速なphpなど、ページが作成されるエンコーディングを指定するときに、原則として3つのオプションを選択できるという事実におそらく注意を向けました。
ANSI
-UTF-8
-BOMなしのUTF-8
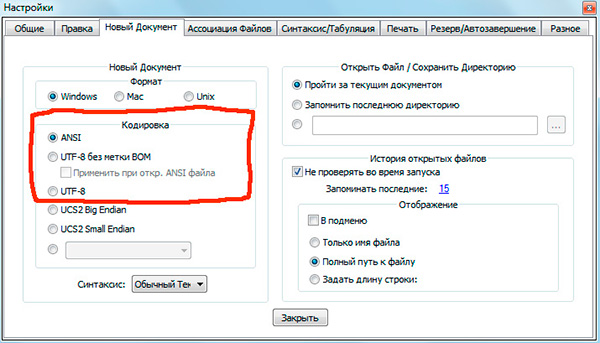

私はすぐにそれが常に選択する価値のある最後のオプションであると言わなければなりません- BOMなしのUTF-8.
では、BOMとは何ですか、なぜそれが必要ないのですか?
BOMを意味する バイト順マーク..。 これは、バイト順序を示すために使用される特殊なUnicode文字です。 テキストファイル..。 仕様によると、その使用はオプションですが、 BOMを使用する場合は、テキストファイルの先頭に設定する必要があります。
作業の詳細については説明しません。 BOM..。 私たちにとって、主な結論は次のとおりです。 このサービス文字をUTF-8と一緒に使用すると、プログラムがエンコーディングを正常に読み取ることができなくなります、その結果、スクリプトの作業でエラーが発生します。
したがって、UTF-8を使用する場合は、オプションを正確に使用してください 「BOMなしのUTF-8」..。 また、原則としてエンコーディングを指定できないエディタは使用しない方がよいでしょう(たとえば、 ノート標準プログラムから ウィンドウズ).
コードエディタで開いている現在のファイルのエンコーディングは、通常、ウィンドウの下部に表示されます。
エントリに注意してください 「UTF-8としてのANSI」エディターで メモ帳++と同じ意味 「BOMなしのUTF-8」..。 これは同じです。
![]()
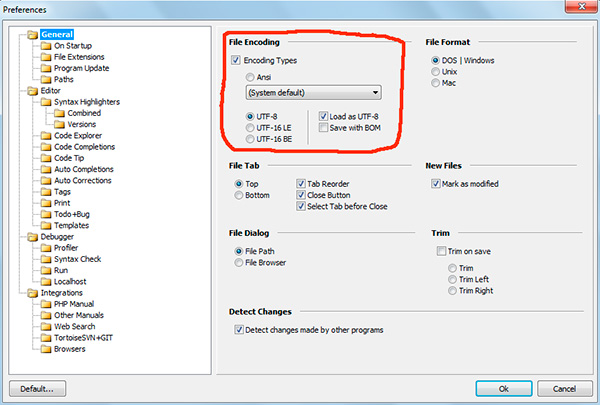
プログラムで phpDesigner使用されているかどうかはすぐにはわかりません BOM、 か否か。 これを行うには、碑文を右クリックします 「UTF-8」、その後、ポップアップウィンドウで次のことを確認できます。 BOM(オプション BOMで保存).
エディターで 迅速なphpエンコーディング BOMなしのUTF-8として示される 「UTF-8 *」.
ご想像のとおり、エディターが異なれば、すべてが少し異なって見えますが、主なアイデアは得られます。
ドキュメントがに保存された後 BOMなしのUTF-8、セクションの特別なメタタグで正しいエンコーディングが指定されていることも確認する必要があります 頭あなたのhtmlドキュメント:
これらの単純なルールに従うことで、エンコーディングで多くのスペースを回避することができます。
以上です。このちょっとした説明と説明が、エンコーディングとは何か、エンコーディングとは何か、そしてそれらがどのように機能するかをよりよく理解するのに役立つことを願っています。
より応用的な観点からこのトピックに興味がある場合は、私のビデオチュートリアルを勉強することをお勧めします。
ドミトリー・ナウメンコ。
追伸サイト構築のさまざまな側面に関するプレミアムチュートリアルと、 無料コース PHPで独自のCMSシステムを最初から作成する方法について。 これらすべてが、さまざまなWeb開発テクノロジーをより速く簡単に習得するのに役立ちます。
あなたはその素材が好きで、ありがとうございましたか?
友達や同僚と共有するだけです!
|
コード(バイナリ) |
(10進数の符号なし) |
(符号付き10進数) |
|
|
A(大きなラテン語) | |||
|
B(ラージラテン) | |||
|
a(小さなラテン語) | |||
|
A(大きなロシア語) エンコーディング ANSI | |||
|
A(大きなロシア語) エンコーディング ASCII |
上に示したように、同様のコードも符号なし形式の0から255までの整数に一致します。 したがって、各文字には、文字コードとも呼ばれる整数があります。 文字コードのコレクションはと呼ばれます コードテーブル また コーディング .
パソコンの場合、最も一般的な コードテーブル ANSI(米国規格協会)およびASCII(情報交換のための米国規格コード)。 WindowsではANSIテーブルが使用され、DOSではASCIIが使用されました。 ただし、これら2つの表では、最初の128コード(0から127) マッチ ; それらは、「疑似グラフィック」の国内(ロシア)文字および記号を格納するために使用される次の128コードのみが異なります。
与えられた表では、指定 KS「文字コード」を意味し、 と-「シンボル」。
指標表の標準部分(ascii-ansi)
上記の記号のいくつかには特別な意味があります。 したがって、たとえば、コード9の文字は水平集計文字を示し、コード10の文字は改行文字であり、コード13の文字はキャリッジリターン文字です。
 GPTとMBRのパーティション構造の違い
GPTとMBRのパーティション構造の違い InternetExplorerをきれいに拭きます
InternetExplorerをきれいに拭きます Windowsアップデートはダウンロードされますが、インストールされません
Windowsアップデートはダウンロードされますが、インストールされません