С unicode коды в буквы. Проблема различения внешне похожих цифр и букв.
Иногда необходимо добавить иконку в ваш дизайн, но вам не хочется вставлять дополнительные изображения или целый шрифт иконок, такой как Font Awesome? Тогда у нас есть для вас хорошие новости - есть обширная библиотека доступных иконок и символов уже в вашем браузере. Она называется Unicode, и это стандарт, который присваивает уникальные идентификаторы для постоянно растущего числа (в настоящее время более 110 000) символов и иконок.
Это не означает, что у вас есть выбор сотен тысяч икон, хотя. Это зависит от браузера, который рендерит их, и он использует шрифты, которые установлены в системе, чтобы сделать это. В этой статье мы собрали ряд наборов символов, которые доступны в Windows, Linux, OS X, Android и IOS. Вы можете использовать их в своем дизайне сегодня!
Совет: , которая объясняет все, что нужно знать о кодировках и Unicode, которую мы рекомендуем для прочтения каждому разработчику ПО.
Как использовать эти иконки
Иконки, приведенные в таблицах ниже, являются обычными символами, которые Вы можете скопировать и вставить как если бы они являлись буквами алфавита. Но если кодировка, используемая для сохранения файлов HTML/CSS не UTF-8 они не будут отображаться. Именно поэтому мы ввели HTML escape-код, который будет работать всегда. Вот то, что вам нужно сделать, чтобы использовать эти иконки :
- Найдите иконку, которая вам нравится. Мы предоставили малые и большие превью.
- Скопируйте код.
- Вставьте её в HTML, как обычный текст. В CSS вы можете использовать их как значение свойства content . В JS, PHP и других языках программирования, вы можете использовать их как обычный текст в строках.
- Вы можете настроить иконки, установив размер шрифта, цвет, текст и тени, также как обычный текст.
Иконки
| Название | Превью | Код | |
|---|---|---|---|
| Smiley | ☺ | ☺ | ☺ |
| Warning Sign | ⚠ | ⚠ | ⚠ |
| Hot Springs | ♨ | ♨ | ♨ |
| Wheelchair | ♿ | ♿ | ♿ |
| Recycle | ♻ | ♻ | ♻ |
| 8-Ball | ➑ | ➑ | ➑ |
| High Voltage | ⚡ | ⚡ | ⚡ |
| White Star | ☆ | ☆ | ☆ |
| Black Star | ★ | ★ | ★ |
| White Heart | ♡ | ♡ | ♡ |
| Black Heart | ❤ | ❤ | ❤ |
| Coffee | ☕ | ☕ | ☕ |
| Airplane | ✈ | ✈ | ✈ |
| Hourglass | ⌛ | ⌛ | ⌛ |
| Clock | ⌚ | ⌚ | ⌚ |
| Black Scissors | ✂ | ✂ | ✂ |
| White Scissors | ✄ | ✄ | ✄ |
| Crown | ♕ | ♕ | ♕ |
| Anchor | ⚓ | ⚓ | ⚓ |
| Cross | ✝ | ✝ | ✝ |
| Black-White Circle | ◑ | ◑ | ◑ |
| Eight Note | ♪ | ♪ | ♪ |
| Beamed Eighth Notes | ♫ | ♫ | ♫ |
| Four Balloon-Spoked Asterisk | ✣ | ✣ | ✣ |
| Circled White Star | ✪ | ✪ | ✪ |
| White Star | ✰ | ✰ | ✰ |
| White Four Pointed Star | ✧ | ✧ | ✧ |
| Black Four Pointed Star | ✦ | ✦ | ✦ |
| Ballot Box Check | ☑ | ☑ | ☑ |
| Check Mark | ✔ | ✔ | ✔ |
| Cross Mark | ✘ | ✘ | ✘ |
| Pencil | ✎ | ✎ | ✎ |
| Writing Hand | ✍ | ✍ | ✍ |
| Female | ♀ | ♀ | ♀ |
| Male | ♂ | ♂ | ♂ |
| Black Telephone | ☎ | ☎ | ☎ |
| White Telephone | ☏ | ☏ | ☏ |
| Envelope | ✉ | ✉ | ✉ |
| Telephone Location | ✆ | ✆ | ✆ |
Стрелки в юникоде
| Название | Превью | Код | |
|---|---|---|---|
| Leftwards Arrow | ← | ← | ← |
| Rightwards Arrow | → | → | → |
| Upwards Arrow | |||
| Downwards Arrow | ↓ | ↓ | ↓ |
| Left Right Arrow | ↔ | ↔ | ↔ |
| Up Down Arrow | ↕ | ↕ | ↕ |
| Right And Left Arrows | ⇄ | ⇄ | ⇄ |
| Up And Down Arrows | ⇅ | ⇅ | ⇅ |
| Down-Left 90deg Arrow | ↲ | ↲ | ↲ |
| Down-Right 90deg Arrow | ↳ | ↳ | ↳ |
| Up-Left 90deg Arrow | ↰ | ↰ | ↰ |
| Up-Right 90deg Arrow | ↱ | ↱ | ↱ |
| North West Arrow To Corner | ⇱ | ⇱ | ⇱ |
| South East Arrow To Corner | ⇲ | ⇲ | ⇲ |
| Leftwards Arrow To Bar | ⇤ | ⇤ | ⇤ |
| Rightwards Arrow To Bar | ⇥ | ⇥ | ⇥ |
| Anticlockwise Semicircle Arrow | ↶ | ↶ | ↶ |
| Clockwise Semicircle Arrow | ↷ | ↷ | ↷ |
| Anticlockwise Circle Arrow | ↺ | ↺ | ↺ |
| Clockwise Circle Arrow | ↻ | ↻ | ↻ |
| Wide-Headed Rightwards Arrow | ➔ | ➔ | ➔ |
| Downwards Zigzag Arrow | ↯ | ↯ | ↯ |
| North West Arrow | ↖ | ↖ | ↖ |
| Heavy South East Arrow | ➘ | ➘ | ➘ |
| Heavy Rightwards Arrow | ➙ | ➙ | ➙ |
| Heavy North East Arrow | ➚ | ➚ | ➚ |
| Dashed Rightwards Arrow | ➟ | ➟ | ➟ |
| Dotted Leftwards Arrow | ⇠ | ⇠ | ⇠ |
| Black Rightwards Arrowhead | ➤ | ➤ | ➤ |
| Leftwards White Arrow | ⇦ | ⇦ | ⇦ |
| Rightwards White Arrow | ⇨ | ⇨ | ⇨ |
| Left Angle Quotation Mark | « | « | « |
| Right Angle Quotation Mark | » | » | » |
| Right Black Pointer | |||
| Left Black Pointer | ◀ | ◀ | ◀ |
| Up Black Pointer | ▲ | ▲ | ▲ |
| Down Black Pointer | ▼ | ▼ | ▼ |
| Right White Pointer | ▷ | ▷ | ▷ |
| Left White Pointer | ◁ | ◁ | ◁ |
| Up White Pointer | △ | △ | △ |
| Down White Pointer | ▽ | ▽ | ▽ |
| Bow Arrow | ➴ | ➴ | ➴ |
Спецсимволы в юникоде
Валюта в юникоде
Иконки погоды
| Название | Превью | Код | |
|---|---|---|---|
| Degree | ° | ° | ° |
| Small Sun | ☀ | ☀ | ☀ |
| Big Sun | ☼ | ☼ | ☼ |
| Cloud | ☁ | ☁ | ☁ |
| Umbrella | ☔ | ☔ | ☔ |
| Snowflake 1 | ❆ | ❆ | ❆ |
| Snowflake 2 | ❅ | ❅ | ❅ |
| Snowflake 3 | ❄ | ❄ | ❄ |
Указатели в юникоде
| Название | Превью | Код | |
|---|---|---|---|
| Pointer Left Black | ☚ | ☚ | ☚ |
| Pointer Right Black | ☛ | ☛ | ☛ |
| Pointer Left White | ☜ | ☜ | ☜ |
| Pointer Up White | ☝ | ☝ | ☝ |
| Pointer Right White | ☞ | ☞ | ☞ |
| Pointer Down White | ☟ | ☟ | ☟ |
Знаки зодиака в юникоде
| Название | Превью | Код | |
|---|---|---|---|
| Овен | ♈ | ♈ | ♈ |
| Телец | ♉ | ♉ | ♉ |
| Близнецы | ♊ | ♊ | ♊ |
| Рак | ♋ | ♋ | ♋ |
| Лев | ♌ | ♌ | ♌ |
| Дева | ♍ | ♍ | ♍ |
| Весы | ♎ | ♎ | ♎ |
| Скорпион | ♏ | ♏ | ♏ |
| Стрелец | ♐ | ♐ | ♐ |
| Козерог | ♑ | ♑ | ♑ |
| Водолей | ♒ | ♒ | ♒ |
| Рыбы | ♓ | ♓ | ♓ |
Карточные символы в юникоде
| Название | Превью | Код | |
|---|---|---|---|
| Clubs Black | ♠ | ♠ | ♠ |
| Hearts Black | ♥ | ♥ | ♥ |
| Diamonds Black | ♦ | ♦ | ♦ |
| Spades Black | ♣ | ♣ | ♣ |
| Clubs White | ♤ | ♤ | ♤ |
| Hearts White | ♡ | ♡ | ♡ |
| Diamonds White | ♢ | ♢ | ♢ |
| Spades White | ♧ | ♧ | ♧ |
Шахматные фигуры в юникоде
| Название | Превью | Код | |
|---|---|---|---|
| King White | ♔ | ♔ | ♔ |
| Queen White | ♕ | ♕ | ♕ |
| Rook White | ♖ | ♖ | ♖ |
| Bishop White | ♗ | ♗ | ♗ |
| Knight White | ♘ | ♘ | ♘ |
| Pawn White | ♙ | ♙ | ♙ |
| King Black | ♚ | ♚ | ♚ |
| Queen Black | ♛ | ♛ | ♛ |
| Rook Black | ♜ | ♜ | ♜ |
| Bishop Black | ♝ | ♝ | ♝ |
| Knight Black | ♞ | ♞ | ♞ |
| Pawn Black | ♟ | ♟ | ♟ |
Игра в кости
| Название | Превью | Код | |
|---|---|---|---|
| Dice Roll One | ⚀ | ⚀ | ⚀ |
| Dice Roll Two | ⚁ | ⚁ | ⚁ |
| Dice Roll Three | ⚂ | ⚂ | ⚂ |
| Dice Roll Four | ⚃ | ⚃ | ⚃ |
| Dice Roll Five | ⚄ | ⚄ | ⚄ |
| Dice Roll Six | ⚅ | ⚅ | ⚅ |
Математические символы в юникоде
| Название | Превью | Код | |
|---|---|---|---|
| Infinity | ∞ | ∞ | ∞ |
| Plus Minus | ± | ± | ± |
| Less-Than Or Equal To | ≤ | ≤ | ≤ |
| More-Than Or Equal To | ≥ | ≥ | ≥ |
| Not Equal To | ≠ | ≠ | ≠ |
| Division | ÷ | ÷ | ÷ |
| Multiplication x | × | × | × |
| Heavy Multiplication x | ✖ | ✖ | ✖ |
| Superscript One | ¹ | ¹ | ¹ |
| Superscript Two | ² | ² | ² |
| Superscript Three | ³ | ³ | ³ |
| Circled Plus | ⊕ | ⊕ | ⊕ |
| Circled Multiplication | ⊗ | ⊗ | ⊗ |
| Logical AND | ∧ | ∧ | ∧ |
| Logical OR | ∨ | ∨ | ∨ |
| Delta | ∆ | ∆ | ∆ |
| Pie | ∏ | ∏ | ∏ |
| Sigma (SUM) | ∑ | ∑ | ∑ |
| Omega | Ω | Ω | Ω |
| Empty Set | ∅ | ∅ | ∅ |
| Angle | ∠ | ∠ | ∠ |
| Parallel | ∥ | ∥ | ∥ |
| Perpendicular | ⊥ | ⊥ | ⊥ |
| Almost Equal To | ≈ | ≈ | ≈ |
| Triangle | △ | △ | △ |
| Circle | ○ | ○ | ○ |
| Square | □ | □ | □ |
Дроби
| Название | Превью | Код | |
|---|---|---|---|
| One Quarter (1/4) | ¼ | ¼ | ¼ |
| One Half (1/2) | ½ | ½ | ½ |
| Three Quarters (3/4) | ¾ | ¾ | ¾ |
| One Third (1/3) | ⅓ | ⅓ | ⅓ |
| Two Thirds (2/3) | ⅔ | ⅔ | ⅔ |
| One Eight (1/8) | ⅛ | ⅛ | ⅛ |
| Three Eights (3/8) | ⅜ | ⅜ | ⅜ |
| Five Eights (5/8) | ⅝ | ⅝ | ⅝ |
| Seven Eights (7/8) | ⅞ | ⅞ | ⅞ |
Римские цифры в юникоде
| Название | Превью | Код | |
|---|---|---|---|
| Roman Numeral One | Ⅰ | Ⅰ | Ⅰ |
| Roman Numeral Two | Ⅱ | Ⅱ | Ⅱ |
| Roman Numeral Three | Ⅲ | Ⅲ | Ⅲ |
| Roman Numeral Four | Ⅳ | Ⅳ | Ⅳ |
| Roman Numeral Five | Ⅴ | Ⅴ | Ⅴ |
| Roman Numeral Six | Ⅵ | Ⅵ | Ⅵ |
| Roman Numeral Seven | Ⅶ | Ⅶ | Ⅶ |
| Roman Numeral Eight | Ⅷ | Ⅷ | Ⅷ |
| Roman Numeral Nine | Ⅸ | Ⅸ | Ⅸ |
| Roman Numeral Ten | Ⅹ | Ⅹ | Ⅹ |
| Roman Numeral Eleven | Ⅺ | Ⅺ | Ⅺ |
| Roman Numeral Twelve | Ⅻ | Ⅻ | Ⅻ |
Есть некоторые различия рендеринга этих символов в различных операционных системах. Это вызвано различными семействами шрифтов, которые используются. Кроме того, iOS и Android заменяют некоторые символы Unicode на смайлики, так что не забудьте проверить добавленные символы, чтобы убедиться, что этого не произойдет и иконки показываются, как предполагалось.
Юникод (по-английски Unicode) - это стандарт кодирования символов. Проще говоря, это таблица соответствия текстовых знаков ( , букв, элементов пунктуации ) двоичным кодам. Компьютер понимает только последовательность нулей и единиц. Чтобы он знал, что именно должен отобразить на экране, необходимо присвоить каждому символу свой уникальный номер. В восьмидесятых, знаки кодировали одним байтом, то есть восемью битами (каждый бит это 0 или 1). Таким образом получалось, что одна таблица (она же кодировка или набор) может вместить только 256 знаков. Этого может не хватить даже для одного языка. Поэтому, появилось много разных кодировок, путаница с которыми часто приводила к тому, что на экране вместо читаемого текста появлялись какие-то странные кракозябры. Требовался единый стандарт, которым и стал Юникод. Самая используемая кодировка - UTF-8 (Unicode Transformation Format) для изображения символа задействует от 1 до 4 байт.
Символы
Символы в таблицах Юникода пронумерованы шестнадцатеричными числами. Например, кириллическая заглавная буква М обозначена U+041C. Это значит, что она стоит на пересечении строки 041 и столбца С. Её можно просто скопировать и потом вставить куда-либо. Чтобы не рыться в многокилометровом списке следует воспользоваться поиском. Зайдя на страницу символа, вы увидите его номер в Юникоде и способ начертания в разных шрифтах. В строку поиска можно вбить и сам знак, даже если вместо него отрисовывается квадратик, хотя бы для того, чтобы узнать, что это было. Ещё, на этом сайте есть специальные (и - случайные) наборы однотипных значков, собранные из разных разделов, для удобства их использования.
Стандарт Юникод - международный. Он включает знаки почти всех письменностей мира. В том числе и тех, которые уже не применяются. Египетские иероглифы, германские руны, письменность майя, клинопись и алфавиты древних государств. Представлены и обозначения мер и весов, нотных грамот, математических понятий.
Сам консорциум Юникода не изобретает новых символов. В таблицы добавляются те значки, которые находят своё применение в обществе. Например, знак рубля активно использовался в течении шести лет прежде чем был добавлен в Юникод. Пиктограммы эмодзи (смайлики) тоже сначала получили широкое применение в Япониии прежде чем были включены в кодировку. А вот товарные знаки, и логотипы компаний не добавляются принципиально. Даже такие распространённые как яблоко Apple или флаг Windows. На сегодняшний день, в версии 8.0 закодировано около 120 тысяч символов.
Элементам кодового пространства, представляющим неотрицательные целые числа. Семейство кодировок определяет машинное представление последовательности кодов UCS.
Коды в стандарте Юникод разделены на несколько областей. Область с кодами от U+0000 до U+007F содержит символы набора ASCII с соответствующими кодами. Далее расположены области знаков различных письменностей, знаки пунктуации и технические символы. Часть кодов зарезервирована для использования в будущем. Под символы кириллицы выделены области знаков с кодами от U+0400 до U+052F, от U+2DE0 до U+2DFF, от U+A640 до U+A69F (см. Кириллица в Юникоде).
Предпосылки создания и развитие Юникода
Поскольку в ряде компьютерных систем (например, Windows NT ) фиксированные 16-битные символы уже использовались в качестве кодировки по умолчанию, было решено все наиболее важные знаки кодировать только в пределах первых 65 536 позиций (так называемая англ. basic multilingual plane, BMP ). Остальное пространство используется для «дополнительных символов» (англ. supplementary characters ): систем письма вымерших языков или очень редко используемых китайских иероглифов, математических и музыкальных символов.
Для совместимости со старыми 16-битными системами была изобретена система UTF-16 , где первые 65 536 позиций, за исключением позиций из интервала U+D800…U+DFFF, отображаются непосредственно как 16-битные числа, а остальные представляются в виде «суррогатных пар» (первый элемент пары из области U+D800…U+DBFF, второй элемент пары из области U+DC00…U+DFFF). Для суррогатных пар была использована часть кодового пространства (2048 позиций), ранее отведённого для «символов для частного использования».
Поскольку в UTF-16 можно отобразить только 2 20 +2 16 −2048 (1 112 064) символов, то это число и было выбрано в качестве окончательной величины кодового пространства Юникода.
Хотя кодовая область Юникода была расширена за пределы 2 16 уже в версии 2.0, первые символы в «верхней» области были размещены только в версии 3.1.
Роль этой кодировки в веб-секторе постоянно растёт, на начало 2010 доля веб-сайтов, использующих Юникод, составила около 50 %.
Версии Юникода
По мере изменения и пополнения таблицы символов системы Юникода и выхода новых версий этой системы, - а эта работа ведётся постоянно, поскольку изначально система Юникод включала только Plane 0 - двухбайтные коды, - выходят и новые документы ISO . Система Юникод существует в общей сложности в следующих версиях:
- 1.1 (соответствует стандарту ISO/IEC 10646-1:1993), стандарт 1991-1995 годов.
- 2.0, 2.1 (тот же стандарт ISO/IEC 10646-1:1993 плюс дополнения: «Amendments» с 1-го по 7-е и «Technical Corrigenda» 1 и 2), стандарт 1996 года.
- 3.0 (стандарт ISO/IEC 10646-1:2000), стандарт 2000 года.
- 3.1 (стандарты ISO/IEC 10646-1:2000 и ISO/IEC 10646-2:2001), стандарт 2001 года.
- 3.2, стандарт 2002 года .
- 4.0, стандарт 2003 .
- 4.01, стандарт 2004 .
- 4.1, стандарт 2005 .
- 5.0, стандарт 2006 .
- 5.1, стандарт 2008 .
- 5.2, стандарт 2009 .
- 6.0, стандарт 2010 .
- 6.1, стандарт 2012 .
- 6.2, стандарт 2012 .
Кодовое пространство
Хотя формы записи UTF-8 и UTF-32 позволяют кодировать до 2 31 (2 147 483 648) кодовых позиций, было принято решение использовать лишь 1 112 064 для совместимости с UTF-16. Впрочем, даже и этого более чем достаточно - сегодня (в версии 6.0) используется чуть менее 110 000 кодовых позиций (109 242 графических и 273 прочих символов).
Кодовое пространство разбито на 17 плоскостей по 2 16 (65536) символов. Нулевая плоскость называется базовой , в ней расположены символы наиболее употребительных письменностей. Первая плоскость используется, в основном, для исторических письменностей, вторая - для редко используемых иероглифов ККЯ , третья зарезервирована для архаичных китайских иероглифов . Плоскости 15 и 16 выделены для частного употребления.
Для обозначения символов Unicode используется запись вида «U+xxxx » (для кодов 0…FFFF), или «U+xxxxx » (для кодов 10000…FFFFF), или «U+xxxxxx » (для кодов 100000…10FFFF), где xxx - шестнадцатеричные цифры. Например, символ «я» (U+044F) имеет код 044F = 1103 .
Система кодирования
Универсальная система кодирования (Юникод) представляет собой набор графических символов и способ их кодирования для компьютерной обработки текстовых данных.
Графические символы - это символы, имеющие видимое изображение. Графическим символам противопоставляются управляющие символы и символы форматирования.
Графические символы включают в себя следующие группы:
- буквы, содержащиеся хотя бы в одном из обслуживаемых алфавитов ;
- цифры;
- знаки пунктуации;
- специальные знаки (математические , технические, идеограммы и пр.);
- разделители.
Юникод - это система для линейного представления текста. Символы, имеющие дополнительные над- или подстрочные элементы, могут быть представлены в виде построенной по определённым правилам последовательности кодов (составной вариант, composite character) или в виде единого символа (монолитный вариант, precomposed character).
Модифицирующие символы
Представление символа «Й» (U+0419) в виде базового символа «И» (U+0418) и модифицирующего символа « ̆» (U+0306)
Графические символы в Юникоде подразделяются на протяжённые и непротяжённые (бесширинные). Непротяжённые символы при отображении не занимают места в строке . К ним относятся, в частности, знаки ударения и прочие диакритические знаки . Как протяжённые, так и непротяжённые символы имеют собственные коды. Протяжённые символы иначе называются базовыми (англ. base characters ), а непротяжённые - модифицирующими (англ. combining characters ); причём последние не могут встречаться самостоятельно. Например, символ «á» может быть представлен как последовательность базового символа «a» (U+0061) и модифицирующего символа « ́» (U+0301) или как монолитный символ «á» (U+00C1).
Особый тип модифицирующих символов - селекторы варианта начертания (англ. variation selectors ). Они действуют только на те символы, для которых такие варианты определены. В версии 5.0 варианты начертания определены для ряда математических символов, для символов традиционного монгольского алфавита и для символов монгольского квадратного письма .
Формы нормализации
Поскольку одни и те же символы можно представить различными кодами, что иногда затрудняет обработку, существуют процессы нормализации, предназначенные для приведения текста к определённому стандартному виду.
В стандарте Юникода определены 4 формы нормализации текста:
- Форма нормализации D (NFD) - каноническая декомпозиция. В процессе приведения текста в эту форму все составные символы рекурсивно заменяются на несколько составных, в соответствии с таблицами декомпозиции.
- Форма нормализации C (NFC) - каноническая декомпозиция с последующей канонической композицией. Сначала текст приводится к форме D, после чего выполняется каноническая композиция - текст обрабатывается от начала к концу и выполняются следующие правила:
- Символ S является начальным , если он имеет нулевой класс модификации в базе символов Юникода.
- В любой последовательности символов, стартующей с начального символа S, символ C блокируется от S, если и только если между S и C есть какой-либо символ B, который или является начальным, или имеет одинаковый или больший класс модификации, чем C. Это правило распространяется только на строки, прошедшие каноническую декомпозицию.
- Первичным композитом считается символ, у которого есть каноническая декомпозиция в базе символов Юникода (или каноническая декомпозиция для хангыля и он не входит в список исключений).
- Символ X может быть первично совмещён с символом Y, если и только если существует первичный композит Z, канонически эквивалентный последовательности
- Если очередной символ C не блокируется последним встреченным начальным базовым символом L и он может быть успешно первично совмещён с ним, то L заменяется на композит L-C, а C удаляется.
- Форма нормализации KD (NFKD) - совместимая декомпозиция. При приведении в эту форму все составные символы заменяются, используя как канонические карты декомпозиции Юникода, так и совместимые карты декомпозиции, после чего результат ставится в каноническом порядке.
- Форма нормализации KC (NFKC) - совместимая декомпозиция с последующей канонической композицией.
Термины «композиция» и «декомпозиция» понимают под собой соответственно соединение или разложение символов на составные части.
Примеры
| Исходный текст | NFD | NFC | NFKD | NFKC |
|---|---|---|---|---|
| Français | Franc\u0327ais | Fran\xe7ais | Franc\u0327ais | Fran\xe7ais |
| А, Ё, Й | \u0410, \u0401, \u0419 | \u0410, \u0415\u0308, \u0418\u0306 | \u0410, \u0401, \u0419 | |
| が | \u304b\u3099 | \u304c | \u304b\u3099 | \u304c |
| Henry IV | Henry IV | Henry IV | Henry IV | Henry IV |
| Henry Ⅳ | Henry \u2163 | Henry \u2163 | Henry IV | Henry IV |
Двунаправленное письмо
Стандарт Юникод поддерживает письменности языков как с направлением написания слева направо (англ. left-to-right, LTR ), так и с написанием справа налево (англ. right-to-left, RTL ) - например, арабское и еврейское письмо. В обоих случаях символы хранятся в «естественном» порядке; их отображение с учётом нужного направления письма обеспечивается приложением.
Кроме того, Юникод поддерживает комбинированные тексты, сочетающие фрагменты с разным направлением письма. Данная возможность называется двунаправленность (англ. bidirectional text, BiDi ). Некоторые упрощённые обработчики текста (например, в сотовых телефонах) могут поддерживать Юникод, но не иметь поддержки двунаправленности. Все символы Юникода поделены на несколько категорий: пишущиеся слева направо, пишущиеся справа налево, и пишущиеся в любом направлении. Символы последней категории (в основном это знаки пунктуации) при отображении принимают направление окружающего их текста.
Представленные символы
Юникод включает практически все современные письменности , в том числе:
и другие.
С академическими целями добавлены многие исторические письменности, в том числе: руны , древнегреческая , египетские иероглифы , клинопись , письменность майя , этрусский алфавит .
В Юникоде представлен широкий набор математических и музыкальных символов, а также пиктограмм .
Однако в Юникод принципиально не включаются логотипы компаний и продуктов, хотя они и встречаются в шрифтах (например, логотип Apple в кодировке MacRoman (0xF0) или логотип Windows в шрифте Wingdings (0xFF)). В юникодовских шрифтах логотипы должны размещаться только в области пользовательских символов.
ISO/IEC 10646
Консорциум Юникода работает в тесной связи с рабочей группой ISO/IEC/JTC1/SC2/WG2, которая занимается разработкой международного стандарта 10646 (ISO /IEC 10646). Между стандартом Юникода и ISO/IEC 10646 установлена синхронизация, хотя каждый стандарт использует свою терминологию и систему документации.
Сотрудничество Консорциума Юникода с Международной организацией по стандартизации (англ. International Organization for Standardization, ISO ) началось в 1991 году . В 1993 году ISO выпустила стандарт DIS 10646.1. Для синхронизации с ним Консорциум утвердил стандарт Юникода версии 1.1, в который были внесены дополнительные символы из DIS 10646.1. В результате значения закодированных символов в Unicode 1.1 и DIS 10646.1 полностью совпали.
В дальнейшем сотрудничество двух организаций продолжилось. В 2000 году стандарт Unicode 3.0 был синхронизирован с ISO/IEC 10646-1:2000. Предстоящая третья версия ISO/IEC 10646 будет синхронизирована с Unicode 4.0. Возможно, эти спецификации даже будут опубликованы как единый стандарт.
Аналогично форматам UTF-16 и UTF-32 в стандарте Юникода, стандарт ISO/IEC 10646 также имеет две основные формы кодирования символов: UCS-2 (2 байта на символ, аналогично UTF-16) и UCS-4 (4 байта на символ, аналогично UTF-32). UCS значит универсальный многооктетный (многобайтовый) кодированный набор символов (англ. universal multiple-octet coded character set ). UCS-2 можно считать подмножеством UTF-16 (UTF-16 без суррогатных пар), а UCS-4 является синонимом для UTF-32.
Способы представления
Юникод имеет несколько форм представления (англ. Unicode transformation format, UTF ): UTF-8 , UTF-16 (UTF-16BE, UTF-16LE) и UTF-32 (UTF-32BE, UTF-32LE). Была разработана также форма представления UTF-7 для передачи по семибитным каналам, но из-за несовместимости с ASCII она не получила распространения и не включена в стандарт. 1 апреля 2005 года были предложены две шуточные формы представления: UTF-9 и UTF-18 (RFC 4042).
Unicode UTF-8: 0x00000000 - 0x0000007F: 0xxxxxxx 0x00000080 - 0x000007FF: 110xxxxx 10xxxxxx 0x00000800 - 0x0000FFFF: 1110xxxx 10xxxxxx 10xxxxxx 0x00010000 - 0x001FFFFF: 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
Теоретически возможны, но не включены в стандарт также:
0x00200000 - 0x03FFFFFF: 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 0x04000000 - 0x7FFFFFFF: 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
Несмотря на то, что UTF-8 позволяет указать один и тот же символ несколькими способами, только наиболее короткий из них правильный. Остальные формы должны отвергаться по соображениям безопасности.
Порядок байтов
В потоке данных UTF-16 старший байт может записываться либо перед младшим (англ. UTF-16 big-endian ), либо после младшего (англ. UTF-16 little-endian ). Аналогично существует два варианта четырёхбайтной кодировки - UTF-32BE и UTF-32LE.
Для определения формата представления Юникода в начало текстового файла записывается сигнатура - символ U+FEFF (неразрывный пробел с нулевой шириной), также именуемый меткой порядка байтов (англ. byte order mark, BOM ). Это позволяет различать UTF-16LE и UTF-16BE, поскольку символа U+FFFE не существует. Также этот способ иногда применяется для обозначения формата UTF-8, хотя к этому формату и неприменимо понятие порядка байтов. Файлы, следующие этому соглашению, начинаются с таких последовательностей байтов:
UTF-8 EF BB BF UTF-16BE FE FF UTF-16LE FF FE UTF-32BE 00 00 FE FF UTF-32LE FF FE 00 00
К сожалению, этот способ не позволяет надёжно различать UTF-16LE и UTF-32LE, поскольку символ U+0000 допускается Юникодом (хотя реальные тексты редко начинаются с него).
Файлы в кодировках UTF-16 и UTF-32, не содержащие BOM, должны иметь порядок байтов big-endian (unicode.org).
Юникод и традиционные кодировки
Внедрение Юникода привело к изменению подхода к традиционным 8-битным кодировкам. Если раньше кодировка задавалась шрифтом, то теперь она задаётся таблицей соответствия между данной кодировкой и Юникодом. Фактически 8-битные кодировки превратились в форму представления некоторого подмножества Юникода. Это намного упростило создание программ, которые должны работать с множеством разных кодировок: теперь, чтобы добавить поддержку ещё одной кодировки, надо всего лишь добавить ещё одну таблицу перекодировки в Юникод.
Кроме того, многие форматы данных позволяют вставлять любые символы Юникода, даже если документ записан в старой 8-битной кодировке. Например, в HTML можно использовать коды с амперсандом .
Реализации
Большинство современных операционных систем в той или иной степени обеспечивают поддержку Юникода.
В операционных системах семейства Windows NT для внутреннего представления имён файлов и других системных строк используется двухбайтовая кодировка UTF-16LE. Системные вызовы, принимающие строковые параметры, существуют в однобайтном и двухбайтном вариантах. Подробнее см. в статье
Если вам нужно ввести лишь несколько специальных символов или знаков, вы можете воспользоваться таблицей символов или сочетаниями клавиш. Список символов ASCII см. в приведенных ниже таблицах или в разделе Вставка букв национальных алфавитов с помощью сочетаний клавиш .
Примечания:
Вставка символов в кодировке ASCII
Чтобы вставить символ в кодировке ASCII, нажмите и удерживайте клавишу ALT, а затем наберите код символа. Например, для вставки знака градуса (º) следует, удерживая нажатой клавишу ALT, набрать на цифровой клавиатуре код 0176.
Примечание:
Вставка символов в кодировке Юникод
Важно: Некоторые программы Microsoft Office, например PowerPoint и InfoPath, не удается преобразовать Юникод коды символов. Если требуется знака Юникод и используете одну из программ, не поддерживающих символов Юникода, с помощью для ввода знаков, которая может потребоваться.
Примечания:
Завершите работу всех программ.
Дважды щелкните значок Установка и удаление программ на панели управления .
Выполните одно из указанных ниже действий.
если приложение Microsoft Office установлено как часть Microsoft Office, выберите Microsoft Office в поле Установленные программы , а затем нажмите кнопку Заменить ;
Если приложение Office было установлено отдельно, щелкните его название в списке Установленные программы , а затем нажмите кнопку Изменить .
Числа следует набирать на цифровой клавиатуре, а не на алфавитно-цифровой. Если для ввода чисел на цифровой клавиатуре требуется нажать клавишу NUM LOCK, убедитесь, что это сделано.
Если у вас возникают проблемы с преобразованием кода Юникода в символ, наберите код на цифровой клавиатуре, выделите его, а затем нажмите клавиши ALT+X.
В Microsoft Windows XP и более поздних версиях универсальный шрифт для Юникода устанавливается автоматически. В Microsoft Windows 2000 шрифт Юникода необходимо установить вручную.
В Microsoft Windows 2000
В диалоговом окне Установка Microsoft Office 2003 выберите параметр Добавить или удалить компоненты , а затем нажмите кнопку Далее .
Выберите Дополнительная настройка приложений и нажмите кнопку Далее .
Разверните список Общие средства Office .
Разверните список Многоязыковая поддержка .
Щелкните значок Универсальный шрифт и выберите нужный параметр установки.
Использование таблицы символов
Таблица символов - это встроенная в Microsoft Windows программа, которая позволяет просматривать символы, доступные в выбранном шрифте. С помощью таблицы символов можно копировать отдельные символы или группы символов в буфер обмена, а затем вставлять их в программу, которая их поддерживает.
Нажмите кнопку Пуск , а затем последовательно выберите пункты Программы , Стандартные , Служебные и Таблица символов .
Чтобы выбрать символ в таблице символов, щелкните его, нажмите кнопку Выбрать , щелкните правой кнопкой мыши в том месте документа, в которое нужно добавить символ, и выберите команду Вставить .
Распространенные коды символьных знаков
Дополнительные символы символ читайте в статье , установленной на компьютере, коды символов ASCII или диаграммы кода знака Юникода сценарием .
|
Знак |
Знак |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Символы денежных единиц |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Юридические символы |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Дроби |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Знаки пунктуации и диалектные символы |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Символы форм |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Распространенные коды диакритических знаковПолный список глифов и соответствующих кодов символов см. в .
|
Unicode - это международный стандарт кодировки символов, позволяющий единообразно отображать тексты на любом компьютере в мире, независимо от используемого на нем системного языка.
Основы
Чтобы понять, для чего нужна таблица символов Юникода, давайте сначала разберемся в механизме отображения текста на экране монитора. Компьютер, как мы знаем, обрабатывает всю информацию в цифровом виде, а вывести ее для правильного восприятия человеком должен в графическом. Таким образом, для того чтобы мы могли читать этот текст, надо решить как минимум две задачи:
- Закодировать печатные символы в цифровую форму.
- Обеспечить операционной системе возможность сопоставления цифровой формы с векторными символами, иными словами, найти правильные буквы.
Первые кодировки
Родоначальницей всех кодировок принято считать американскую ASCII. В ней был описан применяемый в английском языке латинский алфавит со знаками препинания и арабские цифры. Именно использованные в ней 128 символов стали основой для последующих разработок - их использует даже современная таблица символов Юникода. Буквы латинского алфавита занимают с тех пор первые позиции в любой кодировке.
Всего ASCII позволяла сохранить 256 символов, но поскольку первые 128 были заняты латиницей, остальные 128 начали использовать во всем мире для создания национальных стандартов. К примеру, в России на ее основе были созданы CP866 и KOI8-R. Назывались такие вариации расширенными версиями ASCII.
Кодовые страницы и «кракозябры»
Дальнейшее развитие технологий и появление графического интерфейса привело к тому, что американским институтом стандартизации была создана кодировка ANSI. Российским пользователям, особенно со стажем, ее версия известна под названием Windows 1251. В ней впервые было применено понятие «кодовая страница». Именно с помощью кодовых страниц, которые содержали символы национальных алфавитов, отличных от латинского, было налажено «взаимопонимание» между компьютерами, используемыми в разных странах.
Вместе с тем наличие большого количества различных кодировок, используемых для одного языка, начало вызывать проблемы. Появились так называемые кракозябры. Возникали они от несовпадения исходной кодовой страницы, в которой создавалась какая-либо информация, и кодовой станицы, применяемой по умолчанию на компьютере конечного пользователя.

В качестве примера можно привести указанные выше кириллические кодировки CP866 и KOI8-R. Буквы в них отличались кодовыми позициями и принципами размещения. В первой они были расставлены в алфавитном порядке, а во второй - в произвольном. Можете представить, что творилось перед глазами пользователя, который пытался открыть такой текст, не имея нужной кодовой страницы или при ее неправильной интерпретации компьютером.
Создание Unicode
Распространение интернета и сопутствующих технологий, таких как электронная почта, привело к тому что в конце концов ситуация с искажением текстов перестала устраивать всех. Передовые компании в области IT образовали Unicode Consortium ("Консорциум Юникод"). Таблица символов, представленная им в 1991 году под названием UTF-32, позволяла хранить более миллиарда уникальных символов. Это был важнейший шаг на пути к расшифровке текстов.

Однако первая универсальная таблица кодов-символов Юникод UTF-32, не получила большого распространения. Основной причиной стала избыточность хранимой информации. Быстро было подсчитано, что для стран, в которых используется латинский алфавит, закодированный с помощью новой универсальной таблицы, текст будет занимать места в четыре раза больше, чем при использовании расширенной таблицы ASCII.
Развитие Unicode
Следующая таблица символов Юникода UTF-16 эту проблему устранила. Кодирование в ней осуществлялось в два раза меньшим количеством бит, но вместе с тем уменьшилось и количество возможных комбинаций. Вместо миллиардов символов она позволяет сохранить только 65 536. Тем не менее она оказалась настолько удачной, что это число, по решению Консорциума, было определено как базовое пространство хранения символов стандарта Unicode.
Несмотря на такой успех, UTF-16 не устраивала всех, поскольку объем хранимой и передаваемой информации по-прежнему завышался в два раза. Универсальным решением стала UTF-8, таблица символов Юникода с переменной длиной записи. Это можно назвать прорывом в данной области.

Таким образом, с введением двух последних стандартов таблица символов Юникода решила проблему единого кодового пространства для всех применяемых в настоящее время шрифтов.
Юникод для русского языка
Благодаря переменной длине кода, применяемого для отображения символов, латиница кодируется в Юникоде так же, как и в своей прародительнице ASCII, то есть одним битом. Для других алфавитов картина может выглядеть по-разному. К примеру, знаки грузинского алфавита используют для кодирования три байта, а знаки кириллического алфавита - два. Все это возможно в рамках использования стандарта UTF-8 Юникод (таблица символов). Русский язык или кириллический алфавит занимает в общем кодовом пространстве 448 позиций, разбитых на пять блоков.
![]()
В указанные пять блоков входят основной кириллический и церковнославянский алфавит, а также дополнительные буквы других языков, использующих кириллицу. Ряд позиций выделен для отображения старых форм представления букв кириллицы, а 22 позиции из общего количества пока остаются свободными.
Актуальная версия Юникода
С решением своей первоочередной задачи, которая заключалась в стандартизации шрифтов и создании для них единого кодового пространства, "Консорциум" не прекратил свою работу. Юникод постоянно развивается и пополняется. Последняя актуальная версия этого стандарта 9.0 увидела свет в 2016 году. В нее было включено шесть дополнительных алфавитов и расширен список стандартизованных эмодзи.
Надо сказать, что с целью упрощения исследований, в Юникод добавляются даже так называемые мертвые языки. Такое название они получили потому, что людей, для которых он бы являлся родным, не существует. К этой группе относят также языки, дошедшие до нашего времени только в виде письменных памятников.
В принципе, подать заявку на добавление символов в новую спецификацию Юникода может любой желающий. Правда, для этого придется заполнить приличное количество исходных документов и потратить много времени. Живым примером этому может служить история программиста Теренса Идена. В 2013 году он подал заявку на включение в спецификацию символов, относящихся к обозначению кнопок управления питанием компьютера. В технической документации они использовались с середины 70-х годов прошлого века, но до появления спецификации 9.0 не входили в состав Unicode.
Таблица символов
На каждом компьютере, независимо от применяемой операционной системы, используется Юникод-таблица символов. Как пользоваться этими таблицами, где их найти и для чего они могут пригодиться обычному пользователю?
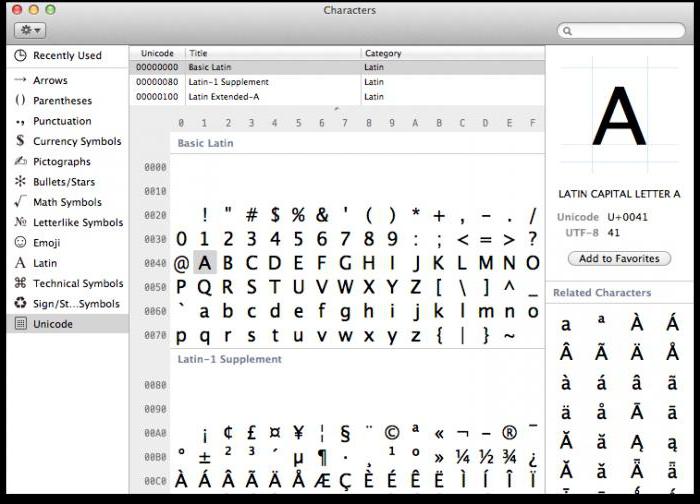
В ОС Windows таблица символов располагается в разделе меню «Служебные». В семействе операционных систем Linux ее обычно можно найти в подразделе «Стандартные», а в MacOS - в настройках клавиатуры. Основное назначение этой таблицы - ввод в текстовые документы символов, которые не расположены на клавиатуре.
Применение для таких таблиц можно найти самое широкое: от ввода технических символов и значков национальных денежных систем до написания инструкции по практическому применению карт Таро.
В заключение
Юникод используется повсеместно и вошел в нашу жизнь вместе с развитием интернета и мобильных технологий. Благодаря его использованию существенно упростилась система межнациональных коммуникаций. Можно сказать, что внедрение Юникода является показательным, но совершенно незаметным со стороны примером использования технологий для общего блага всего человечества.
 Ключи запуска 1с 8.3 из командной строки. Развитие режима агента конфигуратора. Команды, существующие в пакетном режиме
Ключи запуска 1с 8.3 из командной строки. Развитие режима агента конфигуратора. Команды, существующие в пакетном режиме Ошибка: попытка вставки неуникального значения в уникальный индекс: microsoft sql server
Ошибка: попытка вставки неуникального значения в уникальный индекс: microsoft sql server Вывод печатных форм с запросом данных в форму "Печать документов" из подсистемы БСП "Печать"
Вывод печатных форм с запросом данных в форму "Печать документов" из подсистемы БСП "Печать"